Introduction
Welcome to Part Two!
This builds on the first wiki in this series, which you can find here.
After having installed and configured the Basics of TrueNAS Scale, we’ll learn about Storage Pools, VDEVs and Datasets to configure our First Pool and a Custom Dataset. A Snapshot Task will be created as well.
Learning about ZFS/TrueNAS Storage and Terminology
First off, we’ll need to learn a bit about ZFS terminology so it’s easier to follow along.
A lot of ZFS Terminology is used the same way in TrueNAS, but there is some minor differences.
As this series is covering TrueNAS Scale, I’ll mostly focus on that.
I’ll refer to the following graphics throughout this section for visualization:
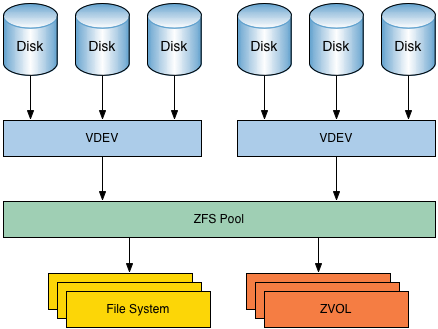
Disks
Storage Devices attached via PCIe, SATA or SAS to your host system are described as Disks.
These must each be physical disks so TrueNAS can perform SMART Tests, keep an eye on the temperatures and spin them up and down properly, they can not be RAID Arrays or the like.
Disks sit at the bottom of the Storage Stack and are what actually stores your data. But except during Pool Creation and Maintenance Tasks, you’ll not directly interact with them on a daily basis
VDEVs
VDEVs, or Virtual DEVices, are the logical devices that make up a Storage Pool.
They are created from one or usually more Disks.
There are different Types of VDEVs for different purposes:
- DATA: A VDEV used to store the Data stored in the Pool and its Datasets
- Cache: A VDEV used for L2ARC Cache, optional and only useful if RAM is maxed out
- LOG: A dedicated VDEV for ZFS’s intent log, can improve performance
- Hot Spare: A VDEV for spare Disks that can automatically replace broken ones in Data VDEVs
- Metadata: A dedicated VDEV to store Metadata
- Dedup: A dedicated VDEV to Store deduplication data (Deduplication is not recommended)
In most simple setups, there will only ever be Data VDEVs in a Pool, which can be configured with the following layouts of Disks:
- Mirror: Two Disks are Mirrored and Contain exactly the same storage blocks
- Stripe: Storage Blocks are spread over one or more disks, no redundancy and error correction available with this!
- Z-RAID1,2,3: Parity Data gets distributed over all drives in the array, with either one, two or three able to fail before data loss.
Often Times, one will opt to create multiple VDEVs of the same Disk Layout if the Number of Disks >10.
ZFS Pools & Root Datasets in TrueNAS Scale
A Pool is a combination of one or more VDEVs, but at least one DATA VDEV.
It stores Encryption and Datasets in an un-encrypted way, so if your Datasets are encrypted the pool stays visible and can be unlocked.
TrueNAS Scale also automatically creates a root Dataset in the Pool, under which a User Creates ZVols or Datasets at their liking.
File Systems / Datasets
File Systems or Datasets are the layer a user or a program will interact with to store data.
Datasets are comparable to Partitions in traditional filesystems (e.g. ext4), but have a lot of added features beyond storing files, for example:
- ZFS Enrcryption to Encrypt Datasets with a Key or Passphrase
- Snapshots which reference old Blocks instead of having to clone a whole Partiton to back it up
- Quotas to Restrict Usage of Storage in relation to the Pool / Root Dataset per Dataset or User
ZVols
Zvols are Block Devices within a ZFS Pool that can be used for Swap Space or VM Disks.
Creating a ZFS Pool
In this Section, we’ll create a simple ZFS Pool out of our Disks with a singular Data VDEV.
Such a Configuration will be used in most simple Homeservers and can be adapted by adding another VDEV to a Storage Pool for expansion or creating a second Pool for e.g. separate SSD Storage.
If you need additional VDEVs you can use this Tutorial as a base and divert as you follow along.
To gest started:
-
Log into your TrueNAS Scale Server
-
Navigate to Storage and click “Create Pool”:
-
You’ll be greeted by the following configuration Dialogue, showing available Disks and options to configure your Pool:

Choosing a Layout for the Data VDEV(s)
At this Point, you’ll have to choose a Layout for your Data VDEV(s).
Reference the Information Above for more Detail on these Options.
As a Rule of thumb, use the following Recommendations:
-
For Maximum Performance: Create One or Multiple ZFS Mirror Data VDEVs
-
2 Disks: Crate a singular Mirror Data VDEV (1 disk can fail, 50% usable storage)
-
3 or 5 Disks: Create a singular Z-RAID1 Data VDEV (1 disk can fail, are unusable for storage)
-
4 or 6 Disks: Create a singular Z-rAID2 Data VDEV (2 disks can fail, are unusable for storage)
When using multiples of the above recommendations, you can add another VDEV of the same type to the Pool for added safety.
For Example, 12 Disks could be configured in two Zraid2 VDEVs with 6 disks each.
Configuring a ZFS Pool with three Disks
Follow the steps below to create a ZFS Pool with a singular RAIDZ-1 VDEV.
We’ll use Encryption and this is recommended in any case unless if your CPU has no AES-NI Support.
-
Type a Descriptive Name for Your Pool that will be easy to remember into this field:
-
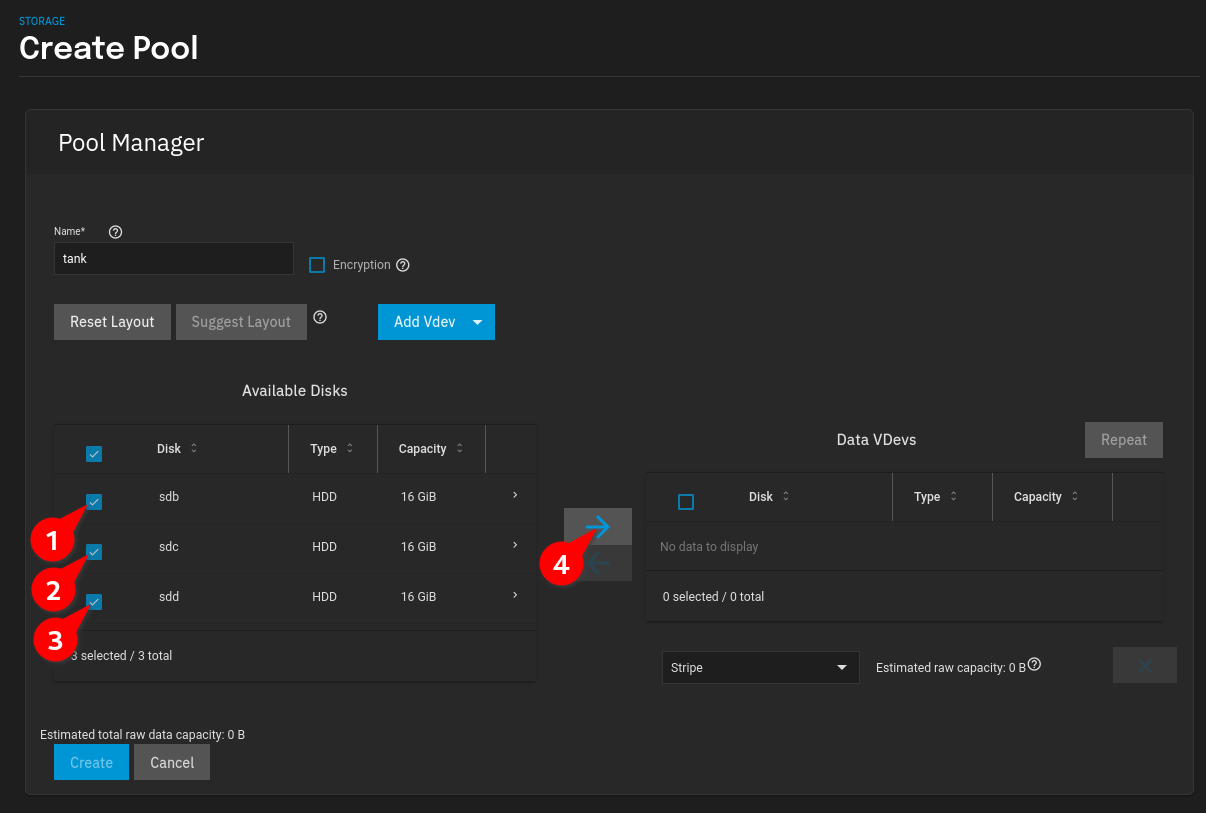
Select the Disks which will be added to the Data VDEV and Click the Arrow:
-
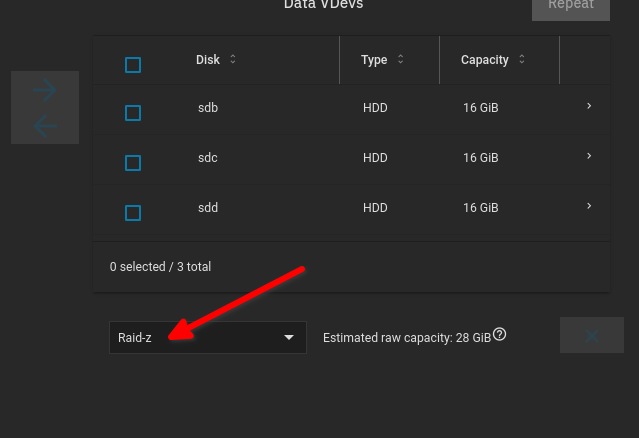
Select RAID-Z(1) if not selected automatically:
-
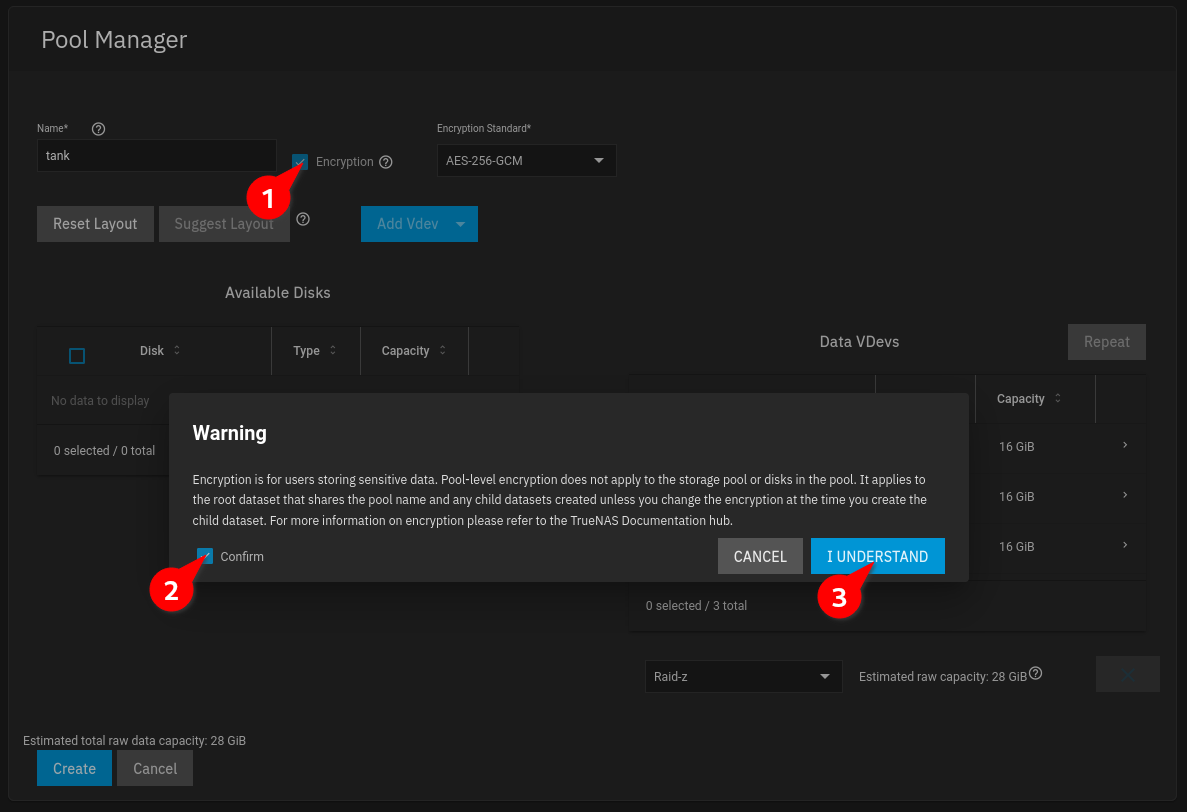
Check “Encryption”, in the Pop-UP check “Confirm” and click “I Understand”:
-
Click Create, Check “Confirm” and Click “Create Pool” to approve disk erasure and Pool Creation:
→ This will Erase any Data on the Selected Disks. -
IMPORTANT: When Prompted, Download the Encryption Key and afterwards confirm with “Done”:
→ Keep this key save. Ideally, write it down on paper too, as it will be the only way to recover data from encrypted Datasets. If you feel like you can keep it save as a digital file, that is also an option, but be safe and not sorry.


Congratulations! You have now configured your first Storage Pool and TrueNAS Scale has automatically configured a Root Dataset:
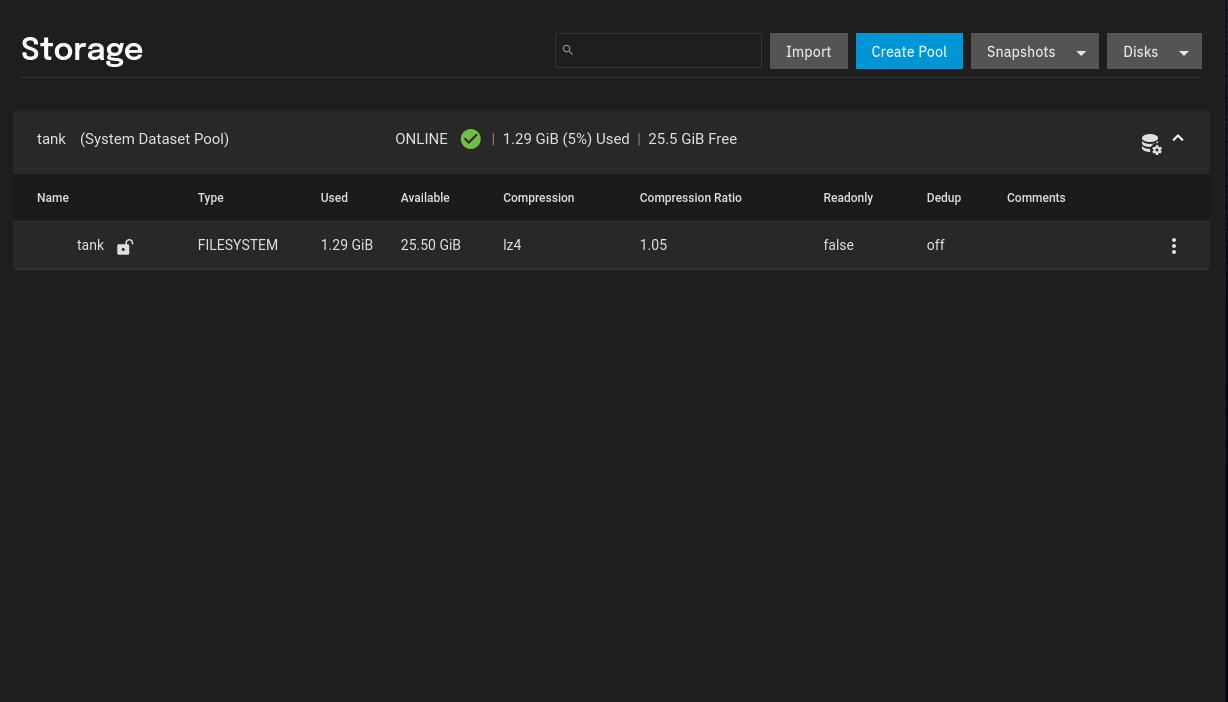
Creating a Dataset
While TrueNAS Scale has created a Root Dataset on the Storage Pool, this is not of much use yet.
You’ll have to creat a child dataset that will actually be used to share data over the network or be accessed by Software installed on TrueNAS Scale.
In the following Instructions, we’ll create a Dataset to store our home media collection.
Creating a Dataset for Media Storage
-
Click on the three Buttons next to your Root Dataset and Click “Add Dataset”:
-
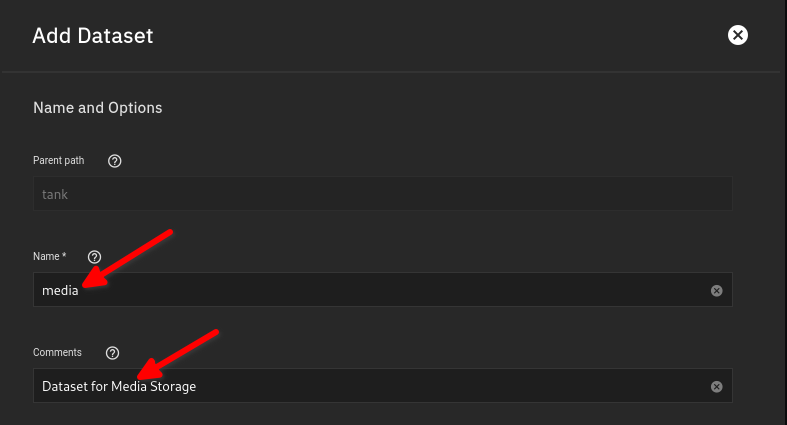
Change the “Name” and “Comment” Fields to something descriptive:
-
Leave “Sync”, “Compression Level”, “Atime” and “Eencryption Options” at Inherit:
→ Atime: Writing FIle Access TIme is not neccessary for a Home Media Dataset and therefore not worth the Performance Penalty. You might decide different for a Dataset containing Documents or other personal Files. -
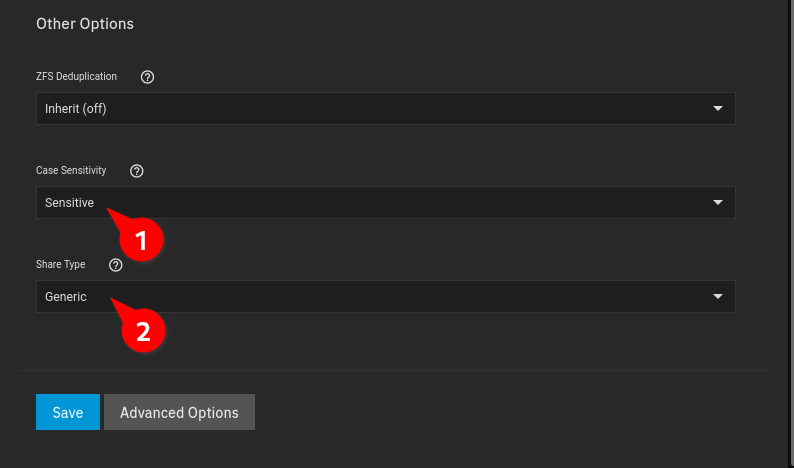
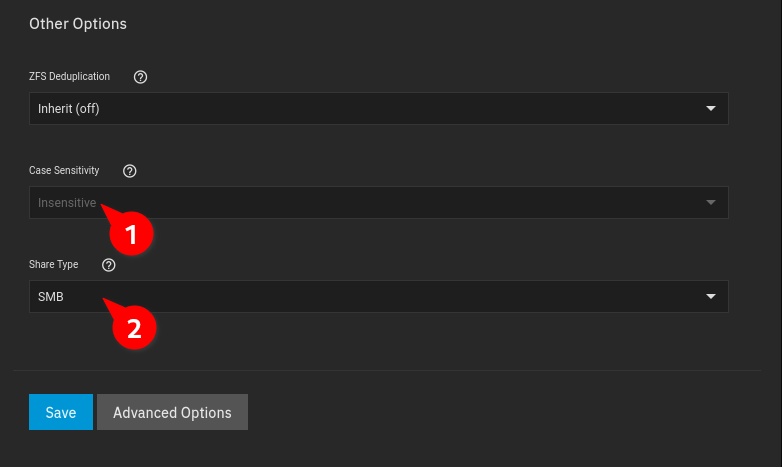
Case Sensitivity and Share Type depend on your Use Case.
→ If Files will be accessed by Linux Clients, e.g. a Jellyfin Container or Linux PCs, then leave Case Sensitivity at “Sensitive” and Share Type at “Generic”:
→ If you’re planning to serve files to Windows Clients directly, switch Case Sensitivity to “Insensitive” and Share Type to “SMB”:
-
Deduplication should always be left off, it has limited advantages and a massive performance hit.
-
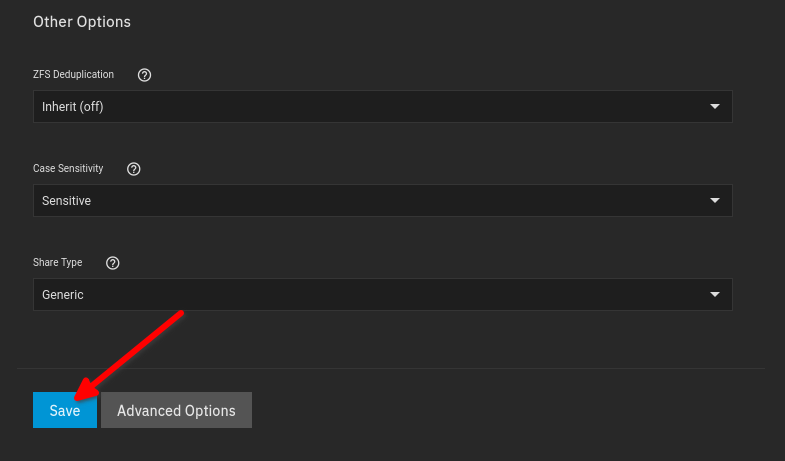
Confirm the Dataset with “Save”:


We have a Dataset!
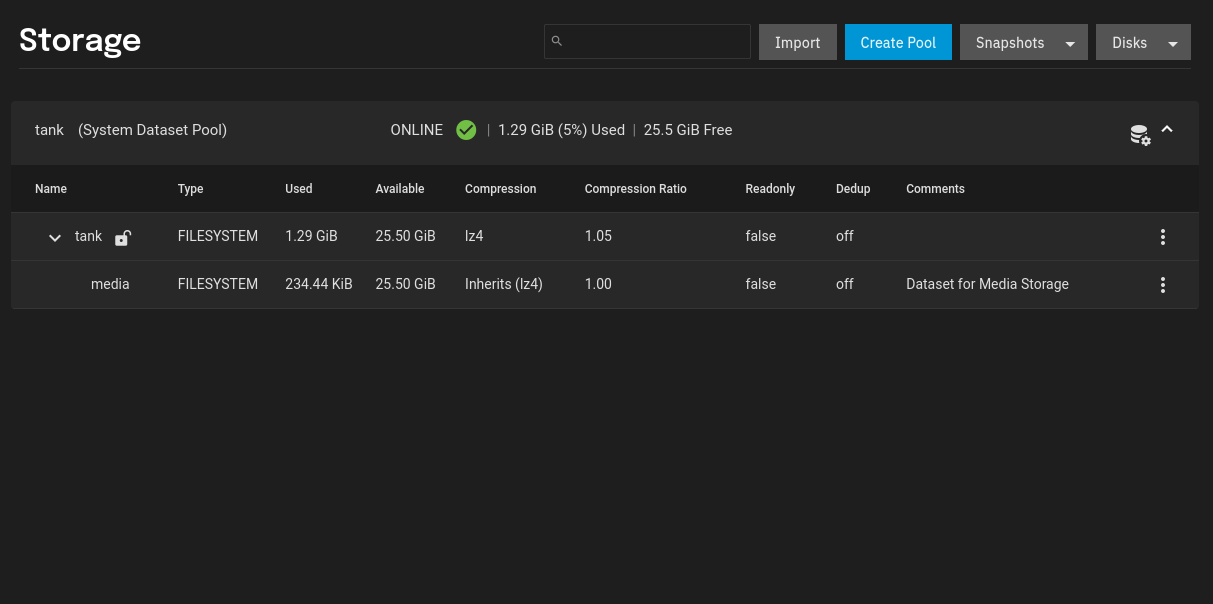
Now now Storage Tab should look like this, with a usable Dataset created:
Snapshots
In the last section of this wiki Enty, we’ll create a Daily Snapshot Task for all Datasets in our Storage Pool.
Snapshots reference blocks on the VDEVs that have been modified or changed and therefore copied to a new block, but still exist. Therefore one can roll back easily to an earlier state.
You might wish to create Snapshot Tasks per Dataset if you have different Datasets for different purposes, but in most cases configuring a single task makes sense.
Creating a Snapshot Task for our Storage Pool
-
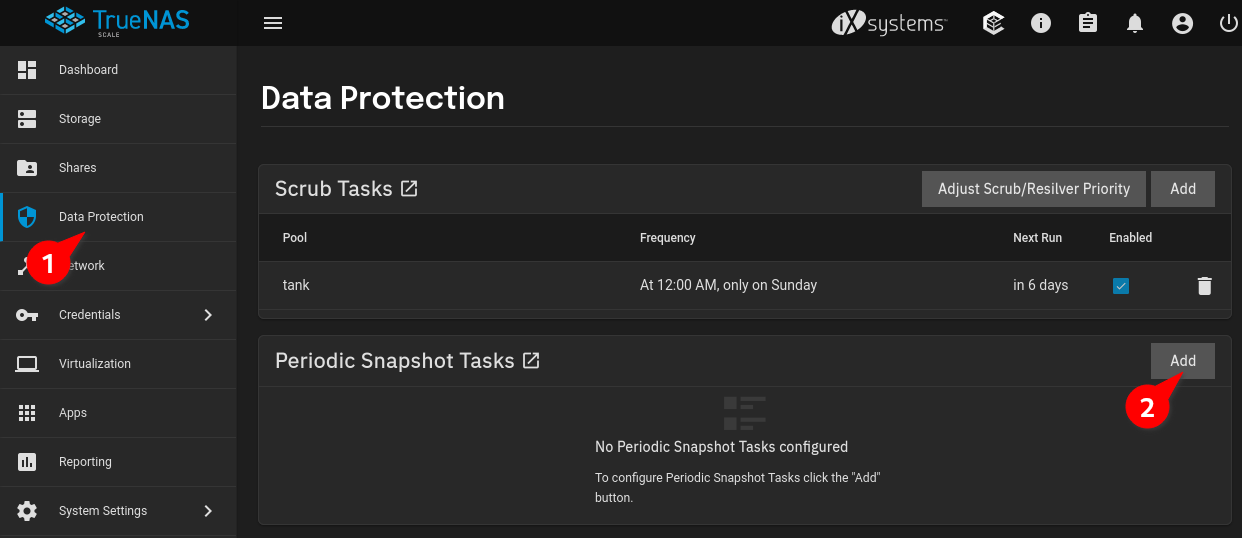
Navigate to “Data Protection” and Click “Add” next to “Periodic Snapshot Tasks”:
-
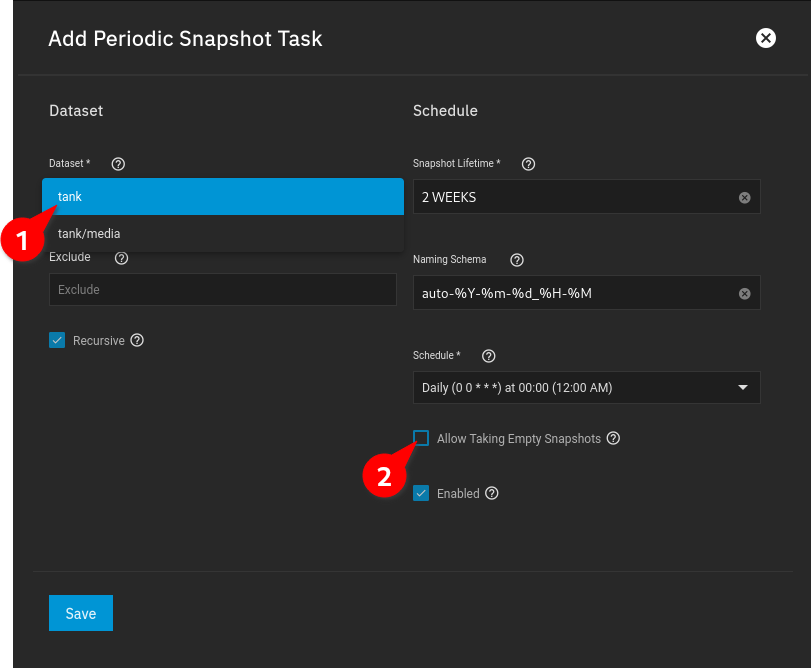
Select the Root Dataset of your Pool and Uncheck “Allow Taking Empty Snapshots”:
-
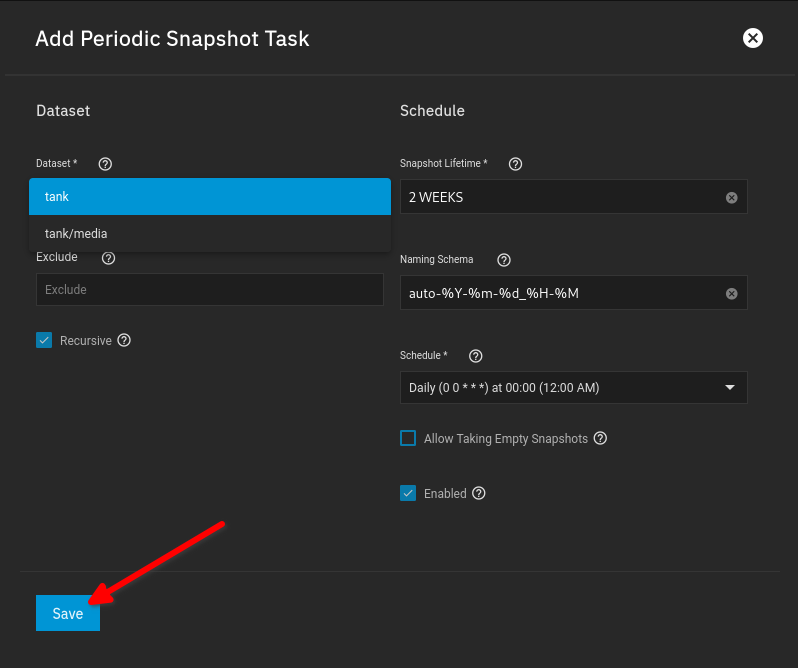
All other Options can be left at default, so Click “Save” to Create the Task:
That was it! Every night at 12AM TrueNAS will create a Snapshot of the state of your Datasets within the selected Pool / Root Dataset, which can be used for Rollback and Backups.
Conclusion
After following this wiki Entry, you should have a functioning Pool, Dataset and a Snapshot Tasks to go along with it.
In the Next Entry we will talk about installing Jellyfin to actually make some use of our Server.