Just wanted to make folks aware that a Linux bug on Ryzen, which looks like a fabrication issue, is present in die made before week 25 of fabrication. This doesn’t look like it can be addressed in microcode. Apparently no explanation or announcement from AMD yet, but this is where we’re at now.
1 Like
@catsay has been investigating the Ryzen segmentation fault issues for quite a while now and I’m sure he can elaborate on the subject with more specifics.
We also have another topic about the segmentation fault issues on Ryzen here: Calling all Linux Ryzen owners! Submit your CPU numbers (uCode/ProdDate)
2 Likes
Thanks for the link.
You should in theory be able to RMA a pre week 25 chip.
1 Like
how do you find out? is there a serial number lookup, or something?
It’s encoded in the batch number. CatSay’s thread has the full details
2 Likes
Hey there.
I have updated my old topic with some new information.
Google Sheets doc of affected & RMA chip UA numbers
Testing for this
Previously people used ryzen-kill script which compiled gcc with lots of threads, but that’s unreliable since it doesn’t stress the CPU power management as easily
My way of testing for this:
- Reset your BIOS to stock
- Install mprime (linux prime95 basically)
- Run
mprime -tfor a good few minutes to get the CPU quite warm. - Attempt to compile pretty much anything a few times over.
A good project to use is tesseract
git clone https://github.com/rigred/tesseract.git
## Install dependencies (sdl2, zlib, maybe a few more)
cd tesseract
## repeat the below a few times until it fails (probably immediately)
make -C src clean && make -C src -j16 install
2 Likes
So how prevalent is this issue with the Ryzen chips, I’m getting ready to build a PC and an R7 is on the table for consideration? I’d hate to bring everything together only to find out that I have to RMA my CPU.
Ask the place your buying from when they got their chips.

According to Michael @ phoronix the bug is a non-issue for regular use and only shows up when hammering the chip with multiple concurrent compilations. Besides you’d have to get a pre-week 25 chip to be affected in the first place.
Humm. Compiling software is actually just a way to put ridiculous amounts of load on the CPU, far more than the CPU can reasonably be expected to process in a timely manner.
If you put that type of load on a CPU, especially multiple ones, it should crash if unstable. I have been doing that with x265.exe on my 1700 @ stock.
The AVX2 ones just crash outright when running multiple instances within a few moments of initilization. The AVX ones are more stable, (100% stable at 1 instance using <75% CPU) but if running hybrid workloads, like ffmpeg + ffmpeg + x265 + ffmpeg + x265 all concurrently, and especially at higher resolutions (normal workload for me), I get crashes:
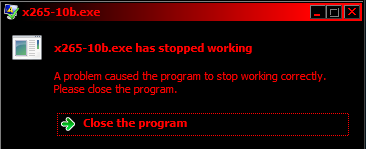
Both ffmpeg and x265 can crash, so I figured it was a memory issue but maybe it’s a Ryzen CPU one?
So is there a way to know the fabrication date besides removing the CPU-cooler? Humm.
Edit:
From other thread:
x_x So I need to schedule downtime in a week or two when my current projects finish encoding…
The following is half-written article compiling [pun intended] all the info on the Ryzen CPU bug that I will finish later maybe if there is interest maybe.
Introduction
Ryzen CPUs manufactured prior to the 25th week of 2017 have a hardware defect is related to heavy concurrent workloads.
Some people are calling for a recall, but AMD is silent on the matter. Currently, they are allowing people to RMA their defective chips individually but do so without explicitly acknowledging the defect as such.
- The issue cannot be fixed using a microcode update.
- This issue must be fixed via a multi-week long RMA process, start one here: https://support.amd.com/en-us/warranty/pib, or general tech support: https://support.amd.com/en-us/contact/email-form
- This issue does not matter to gamers/overclockers.
- If Ashes of the Singularity/CinebenchR15 crashes, just restart it.
- This is an issue to people who need 100% stability from their hardware due to their productivity-oriented workloads that can take a significant amount of time to complete and/or require the result to be trustworthy (compiling, encoding, CAD, scientific calculations, etc). Ryzen defect + ZFS pool = guess what happens to your data.
- Purely unoffical: All CPUs prior to 25th are potentially affected, most 25th week chips are fine, and all post 25th week chips are fine.
- You can check your manufacture date here: (It is only printed on the heat spreader, and never put in the chip so there is no way to obtain the data via software.)
- You can check if your pre-week 25 chip was affected using the Steps To Reproduce instructions below.
Background
The issue was first discovered by DragonFlyBSD developer Matt Dillon and was publicized by Michael Larabel from Phoronix.
In other words, the specific trigger has yet to be pinpointed, or rather AMD has yet to make a formal statement as to what the actual trigger is, but it seems strongly correlated with discrete core cache and context-switching.
Matt Dillon paraphrasing AMD’s comments on the Ryzen DragonFlyBSD workaround commit:
"Ryzen has an issue when the instruction pre-fetcher crosses from canonical to non-canonical address space. […] AMD validated the bug and determined that unmapping the boundary page completely solves the issue."
http://lists.dragonflybsd.org/pipermail/commits/2017-August/626190.html
Having developers modify address spaces layouts in a particular way “completely solves” a specific occurrence using a specific piece of open source software, so, this implies AMD knows exactly what the real trigger is. Disabling ASLR, disabling SMT and messing with cache via disabling Cool and Quiet will take the issue longer to manifest helps prologue the expected time to failure, but cannot fully mitigate the issue. Thus, AMD is currently marketing this as a “GCC Linux Compilation issue” or Linux performance marginality issue, both of which are of course nonsense.
- This is not a GCC issue. GCC compiles just fine on non-Ryzen systems and post week 25 Ryzen systems.
- This is not a Linux issue. It is at the hardware level, within the CPU, so it obviously affects every OS. I noticed it on often on Windows using x265.
- This is not a “performance mitigation” issue, as AMD calls it. Mitigating the issue by disabling/overloading threads at the OS/App level just changes the workload in such a way as to work around the known hardware defect. The bug will still occur, but will take longer to manifest.
- Example from Matt Dillon’s commit: “There is a bug in Ryzen related to the kernel iretq’ing into a high user %rip address near the end of the user address space (top of user stack). This is a temporary workaround for the issue. The original %rip for sigtramp was 0x00007fffffffffe0. Moving it down to fa0 wasn’t sufficient. Moving it down to f00 moved the bug from nearly instant to taking a few hours to reproduce. Moving it down to be0 it took a day to reproduce. Moving it down to 0x00007ffffffffba0 (this commit) survived the overnight test.” From: https://gitweb.dragonflybsd.org/dragonfly.git/commitdiff/b48dd28447fc8ef62fbc963accd301557fd9ac20
- This is also NOT a normal CPU Load issue.
- CPUs at 100% 24/7 will never experience the issue under certain workloads, where as other workloads will get it within a few minutes. Some users report doing multi-month long burn-in tests (typical for some scientific workloads) without experiencing the issue, but can reproduce it using a different workload within 5 minutes. From: https://community.amd.com/thread/215773?start=1215&tstart=0
Community Resources:
“Main” AMD Community issue thread: https://community.amd.com/message/2796982
Phoronix threads/articles: https://techreport.com/news/32362/amd-confirms-linux-performance-marginality-problem-on-ryzen and
https://www.phoronix.com/scan.php?page=news_item&px=Ryzen-Compiler-Issues
https://www.phoronix.com/scan.php?page=news_item&px=Ryzen-Segv-Response
https://www.phoronix.com/scan.php?page=article&item=new-ryzen-fixed&num=1
Reddit: https://www.reddit.com/r/Amd/
Level1: Calling all Linux Ryzen owners! Submit your CPU numbers (uCode/ProdDate)
Ryzen Pre-Week 25 fabrication RMA issue
Ryzen segv data spreadsheet: https://docs.google.com/spreadsheets/d/1pp6SKqvERxBKJupIVTp2_FMNRYmtxgP14ZekMReQVM4/edit#gid=0
Gentoo spreadsheet: https://docs.google.com/spreadsheets/d/1gzniXYcXm1uACXGoBLpbpq54KE6SlHxQ6M_wPnTkub8/edit#gid=950983791
Steps To Reproduce
Step #1) Eliminate other sources of instability.
Prime95 will never produce this specific issue*(citation needed) due to some [non-]optimization quirks, so use it to test for basic stability.
Important: If you can’t run Prime95 stable indefinitely, then fix your unrelated issues before testing for the concurrency bug. You cannot know if your issues are related to the concurrent cpu load bug (covered by warranty) if you have on-load temp issues, overclock, undervolt, or have unstable memory (out of warranty). Fix that other stuff first.
- Load stock settings in the UEFI.
- Raise SoC to 1.1v
- Set RAM to 2133Mhz.
- Note that anything past the officially supported speed per [rank/module quantity] configuration (2666[1/1-2], 2400[2/1-2], 2133[1/3-4], 1866[2/3-4) is considered overclocking on Ryzen.
- Raise vCore to 1.365v (up to 1.425v is safe, 1.365 is supposed to be the default prior to Ryzen power management stuffs, according to tech-support).
Step #2)
The most definitive (so far) way to test is using the script at: https://github.com/suaefar/ryzen-test
It compiles GCC multiple times concurrently, on a loop. The CPU load this generates puts Prime95 and the IntelBurnTest to shame. The script will give you a time-to-fail when something quits. Error logs for the specific error are at…[]
Requirements:
- Linux, A Live-CD/USB works
- 16GB of RAM+
- The compilation takes more memory as it runs. The concurrency bug can trigger long prior to hitting 16GB usage. There was some workarounds possible relating to the ramdisk.
For the purposes of this test, Fedora 26 is recommended over Ubuntu 17.04 due to known kernel-SMT related issues with Ubuntu.
So install Fedora or just start a Live-CD/USB and start a terminal.
sudo passwd
su -
wget ftp://ftp.fu-berlin.de/unix/languages/gcc/releases/gcc-7.1.0/gcc-7.1.0.tar.bz2
git https://github.com/suaefar/ryzen-test
cd ryzen-test
chmod +x ./kill-ryzen.sh
chmod +x ./save-ryzen.sh
chmod +x ./buildloop.sh
nano ./kill-ryzen.sh
change the line that says:
wget ftp://ftp.fu-berlin.de/unix/languages/gcc/releases/gcc-7.1.0/gcc-7.1.0.tar.bz2
to
cp ~/gcc-7.1.0.tar.bz2 .
For Fedora, comment out (#) the following line near the top:
sudo apt install build-essential || exit 1
ctrl + o
Enter
ctrl + x
And now finally, start the test:
./kill-ryzen.sh
If there is any instability in your system, it will likely error out within 5 minutes and print out a to time to fail. Example output:
[loop-5] Mon Aug 14 12:19:55 CDT 2017 start 0
[loop-5] Mon Aug 14 12:22:00 CDT 2017 build failed
[loop-5] TIME TO FAIL: 130 s
[KERN] Aug 14 12:22:00 ronin kernel: bash[6763]: segfault at 7fa18822d7e8 ip 00007fa187f49330 sp 00007fff63fa3eb8 error 4 in libc-2.24.so[7fa187e20000+193000]
With 32 GB of RAM, my shortest time to failure was 42 seconds and longest was about 380 seconds (6.3 minutes). Typical was 239 seconds (4 minutes). More memory + faster SSD = GCC complies faster = crashes occurs sooner. Most people are reporting that most errors will occur below 1 hour (3600 seconds) if they do not run out of memory. Some people have reported errors at 38 hours in, but non above 40 hours as far as I know. At this time and in my opinion, 48 hours (2 days) without error should be considered stable. Nothing less. Reboot system in between test runs. ctrl+c to stop it.
Windows:
Method 1) Due to the specifics of how virtualization is actually implemented, it is actually possible to reproduce this issue within a Linux virtual machine on a Windows host. This is experimental, obviously, but there’s no point installing another OS, or Fedora or Win10 or w/e if the issue cannot be replicated. If it doesn’t affect you in a VM, congrats! You aren’t affected, probably.
[image1]
[image2]
If it occurs (as in the screenshots above), time test for it natively…
Method 2) Win10 also has more official-ish support for the linux-subsystem than previous versions so the linux test can also be used in this terminal. IDK know to use it.
[link]
Method 3) Disclaimers: Windows in general does not utilize hardware as well as Linux can so the issue is harder to reproduce natively. Windows 10 handles heavy workloads better than Win 7, [some benchmarks], so it is recommended to test using Win 10 instead of 7. Anecdotally, some overclockers have said Win10 is very unstable compared to 7, implying that Win10 has lower tolerance for errors, likely because it can better utilize the available hardware resources.
So anyway, There is also this questionable project: https://github.com/hayamdk/ryzen_segv_test but the authors have reported seg-faults on unrelated systems and it also requires Visual Studio 2017 so… questionable.
I could also probably write a small script to encode a video using x265 in single-threaded mode 16 times concurrently, in a loop forever and post it on github. IDK if it’s worth the effort tho. It would take an hour or two to write + test. Anyone interested? Also: are there download and copyleft friendly videos available or should I make everyone encode Rick Astley thousands of times over?
wmic cpu get Name,NumberOfCores,NumberOfLogicalProcessors /format:list
Steps To Fix (RMA)
- Reset UEFI to default settings.
- Record Idle and load temps for CPU (Prime95 is fine for this)
- Test for bug. If it does not appear after 48 hrs. Congrats! Your CPU is not affected.
- Otherwise, Raise SoC to 1.1, vCore to 1.365, disable XMP, set RAM to 2133Mhz (JEDEC spec).
- Record Idle and load temps for CPU (Prime95 is fine for this)
- Test for bug. If it does not appear after 48 hrs. Congrats! Your motherboard has funky voltage defaults. Always use these settings or continue fiddling.
- Otherwise, Get an RMA started here: https://support.amd.com/en-us/warranty/rma, or general tech support: https://support.amd.com/en-us/contact/email-form
- Take/upload pictures of your case internals showing your fan configurations and HSF.
- Take/upload pictures of UEFI settings (F12 + Fat32 formatted USB drive on GigaByte boards)
The following should only be done if instructed to do so by tech support:
- Otherwise, the next step is to raise vCore to 1.4
- Take/upload pictures of UEFI settings
- Test for bug. If it does not appear after 48 hrs. Congrats! You have a lousy chip that will always run hot but is stable. Cancel the RMA.
- Otherwise, Raise vCore to 1.425 (do not go over this amount)
- Take/upload pictures of UEFI settings
- Test for bug. If it does not appear after 48 hrs. Congrats! You have a very lousy chip that will always run very hot, but is stable. Cancel the RMA.
- Ship the CPU to AMD with an RMA #, as instructed by tech support personnel.
- After replacement arrives, test for issue again using stock voltages and continue to work tech support.
2 Likes
An additional observation that I found interesting:
I contribute to blender and compile it a lot.
If I compile blender with a single thread it will fail with a Internal Compiler Error (Segmentation Fault) at some stage.
When I compile blender with all 16 threads it builds just fine. This is completely opposite from the gcc ryzen-kill test where more threads trigger it faster.
1 Like
It’s also worth noting we have several retail Ryzen chips (no samples) including at least one 1800x before week 25 that do not exhibit the issue. It’s hard to imagine but perhaps binning is related in some way.
2 Likes
Now there is finally one benefit to being a photonerd and a pc-nerd.
I don’t have to rip my system apart to look at that number.

Week 07 seems very early on. I guess I should get this tested…
Dammit.
1 Like
I just cited the issue in my reply to tech support, and said that I expected to get a replacement not from one of the affected batches. It was a little more strongly worded than I would normally prefer, but not rude, and the next email was an approval (with a free shipping label, and a promise they wouldn’t wait to send the replacement out). So, seems good, and hopefully I’ll be in good shape soon.
Out of interest could you say what batch numbers those are for your unaffected chips?
My hypothesis is that they are 17xx SUS chips. Or am I wrong?
no idea, they are in use, but there might be some clear shots in our broll… I will haev to go back and look or some bored soul here could? 
Ah Ok. I understand.
I too will have to wait for that bored soul to come along.
My reason for the SUS suspicion is due to the fact almost all the people who did RMA’s got SUS CPU’s.
That is [S]aratoga Fab 8 produced and [S]uzho[u] assembled.