So I’m building a ML server for my own amusement (also looking to make a career pivot into ML ops/infra work).
Most of what I do is reinforcement learning, and most of the models that I train are small enough that I really only use GPU for calculating model updates. Model inference happens on the CPU, and I don’t need huge batches, so GPUs are somewhat of a secondary concern in that context.
That said, I have some cash left over in my budget, and I’d like to throw in an array of 4-8 GPUs for supervised learning. I kind of want a mix of VRAM size and performance, as I expect that when not doing RL, I’ll be wanting to play around with LLMs, diffusion models, and a few other “transformery” things.
I’ll also be giving some remote friends access to this rig via Jupyter, so being able to fork off a GPU into a VM or container is appealing.
My absolute max budget for this is around $3,100 USD, though I’d like to keep to around $2,500. I live in NZ, so figure around $150 or so for shipping, plus 15% markup due to import taxes and brokering fees.
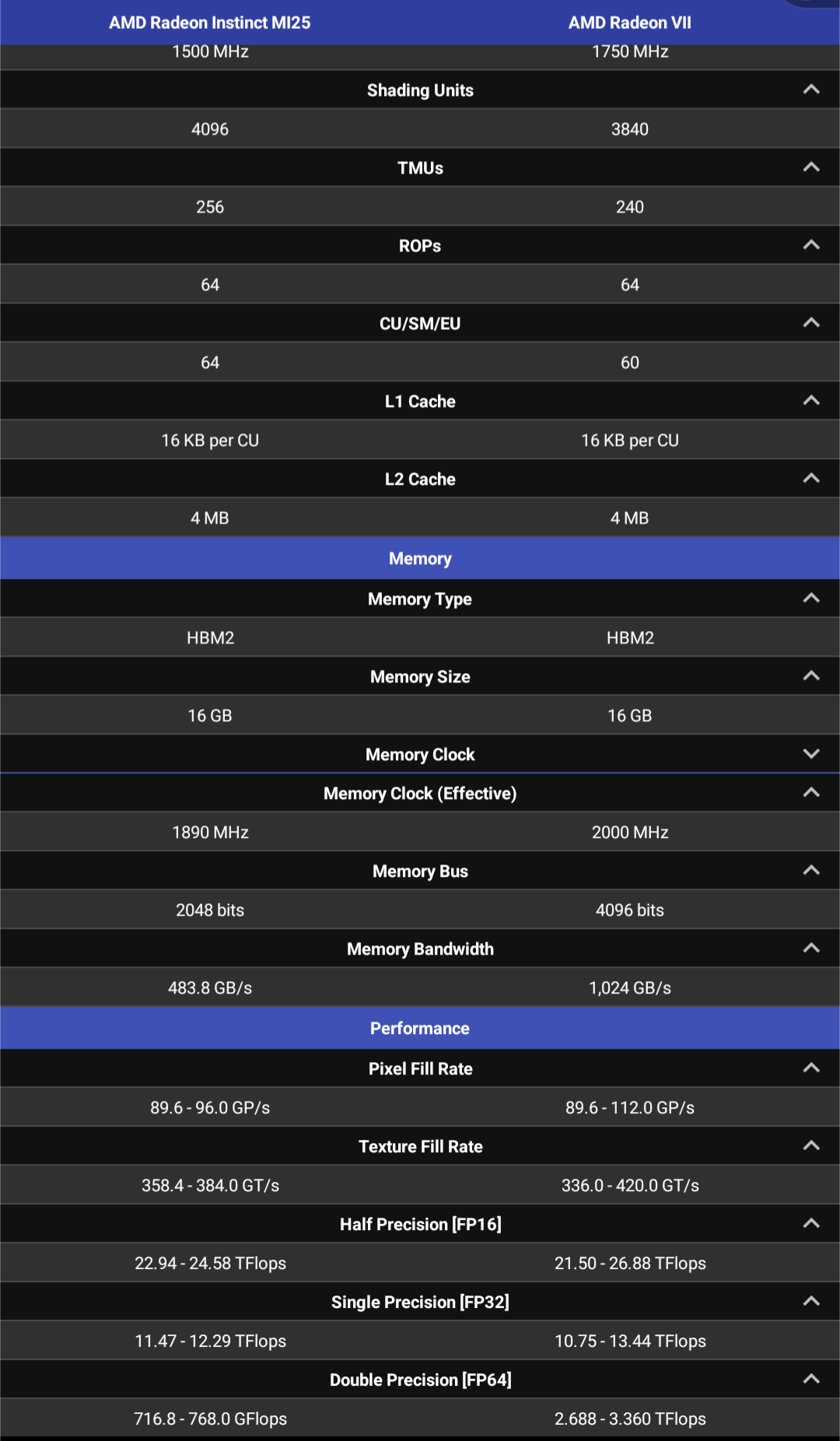
At the moment I’m debating between the A4000 and MI25 cards. Pros on both are that they’re cheap and they have fast VRAM. Unfortunately neither supports memory pooling via NVLink or Infinity Fabric, but cards that do are either too power hungry, or too far out of my price range.
I did have a look at the A5000 and MI50/MI60 cards in an attempt to get something that could do memory pooling. A5000 is still a bit too expensive, and it’s not clear whether infinity fabric link is actually supported on anything earlier than the MI100, even though the physical connector is there. Also the only four-GPU infinity fabric link bridge card that I could find was like $600USD (same price as the only two-GPU one that I found).
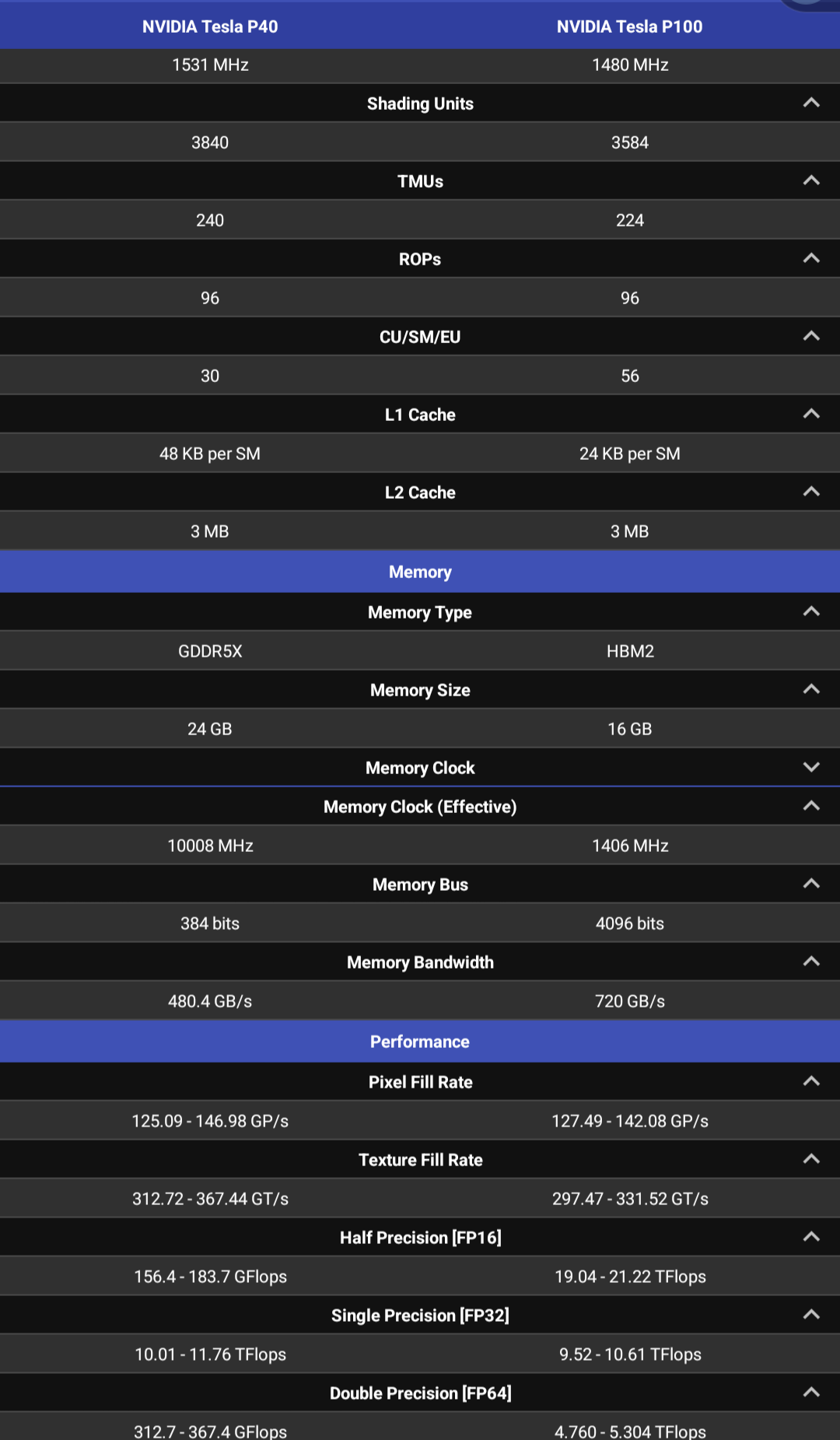
I also had a look at Pascal and even Maxwell Tesla cards. The P40 is cheap as chips, but also doesn’t NVLink, and doesn’t have quite the performance that I’d like. I could go P100 for NVLink, but then I’d be in a price range that’s similar to used A4000s, and that perf boost looks appealing.
I’m currently leaning heavily toward A4000, but the price of used MI25 cards is really appealing. Perf per watt isn’t great, but I could learn to live with it.
Most of the feedback that I’m getting from other hobbyist ML practitioner friends seems to be to avoid team red, but I have a feeling that I may get more learning framework internals XP out of taking the hard path with ROCm.
Does anyone on this forum have a good amount of experience with both vendors? If so, what would you advise?
Also in general, is there anything that I should be considering that I’m not? If it helps any, I’m a fairly experienced software engineer (20+ years professional experience) with a fair amount of time in the saddle in ops and systems engineering roles.