Hope you all are well, Exard3k, greatnull, Lt.Broccoli, MikeGrok, twin_savage, and wendell. Apologies for my delayed reply. Work and people keep me busy. On the upside, I can consider something like this project. Let me try to respond to all the main points I see. Apologies for the long post!
I am most humbly grateful for the offers to run some tests on this software! A pleasant surprise! A little preview/testing helps before plunging with such an investment.
I am still going to look for an EGSnrc example to run. The GEANT4 package comes with some test examples; one of which approximates one of the types of simulations I want to run; though it uses an old machine and orders of magnitude fewer voxels and particles. While I compiled it for my desktop and ran it, the executable seems to not be totally self-sufficient. It still needs the GEANT4 libraries installed on my machine. So it seems that testing will require compiling those libraries first then compiling the examples to run them. That makes for more than a simple run and see situation so I am not sure how much I can ask. This post is long enough. I will post information for anyone still interested.
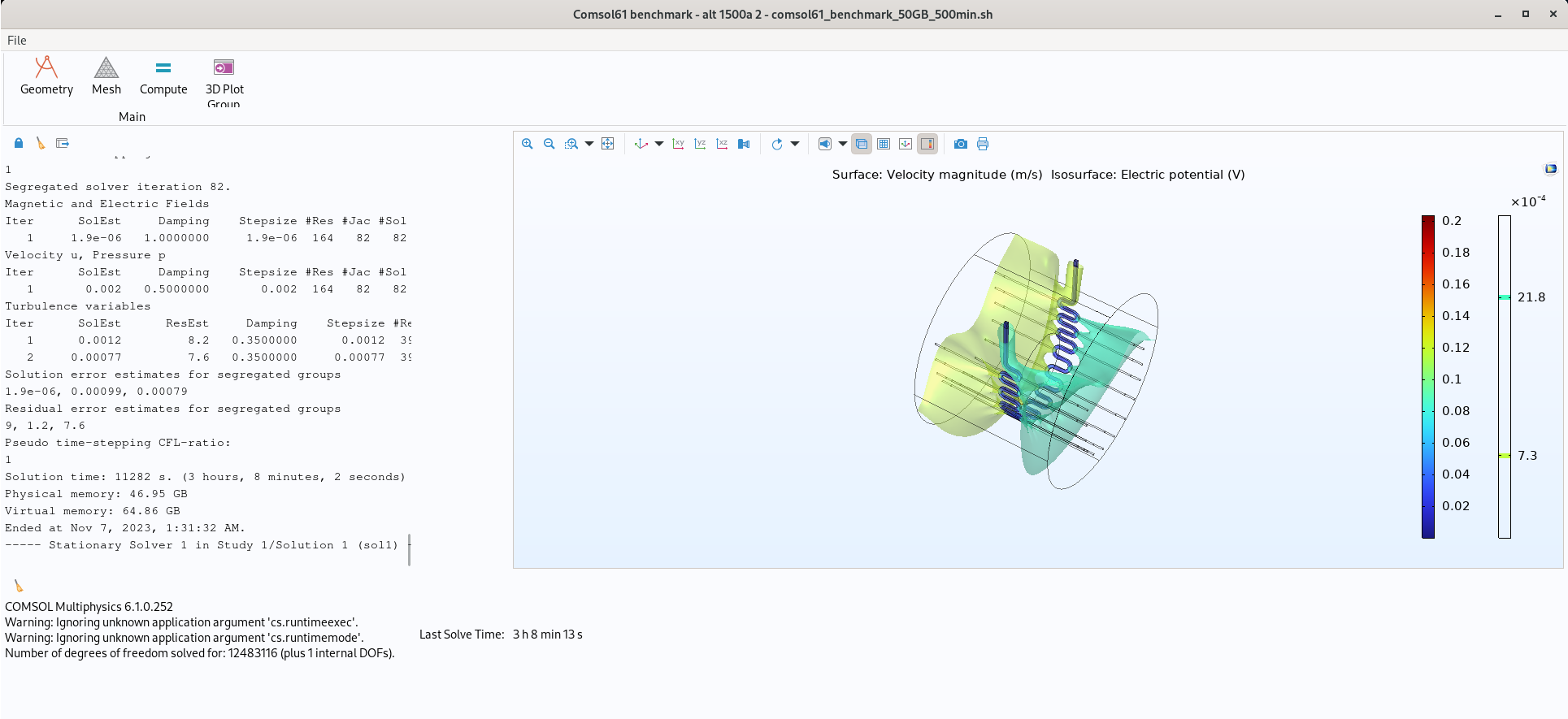
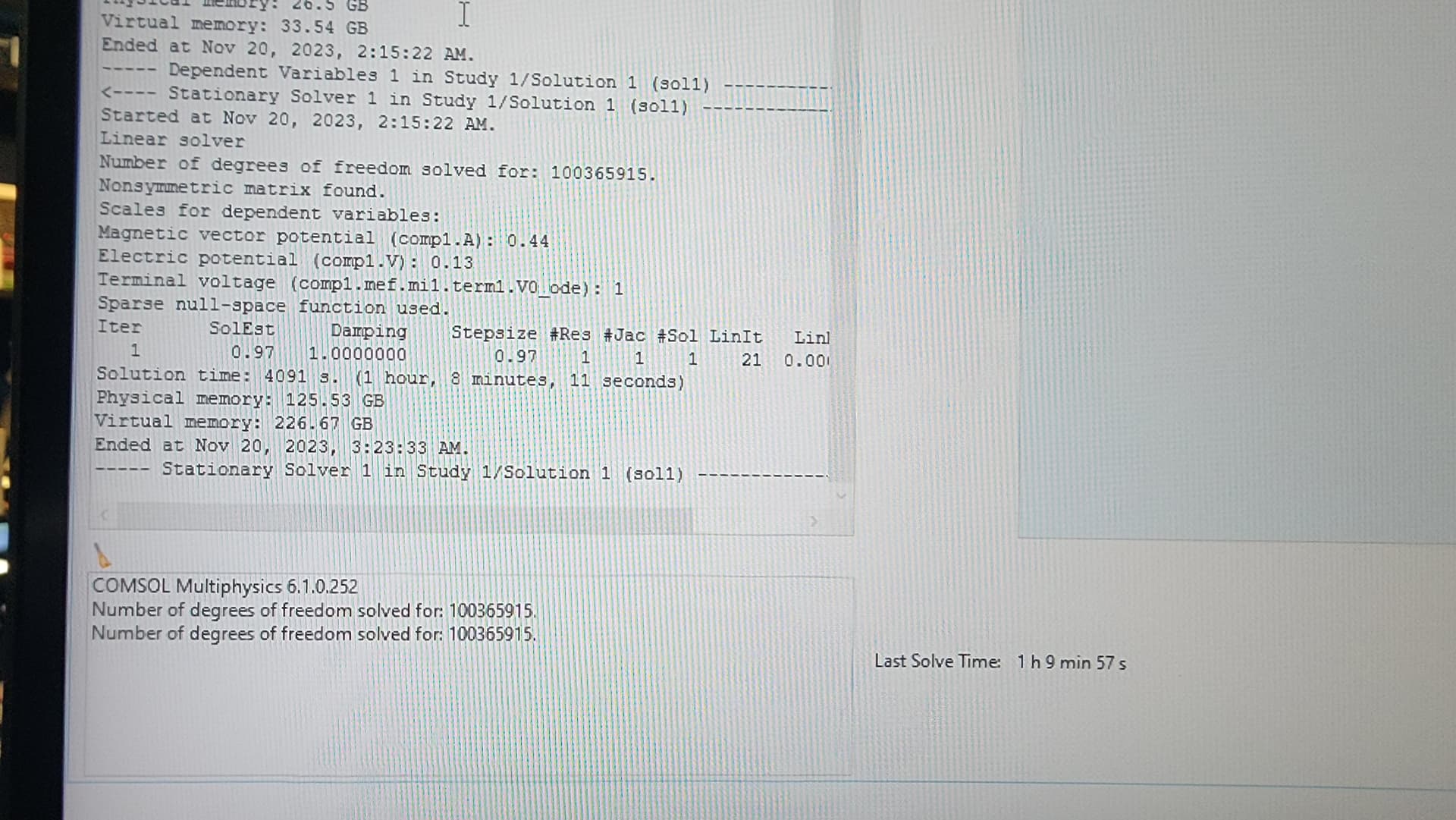
From the few compiled runs I did, I learned that I might need between 0.5 - 25GB file size (text file of numbers) depending on whether I want to simulate upto a whole 4-room suite. My i7-7700, GeForce 1080, 8gb ram desktop struggles.
I did try some online configurations. Here are the results. Not sure how to insert a link on this forum to the respective webpages. Interesting similarities and differences. Seems like the main issue I need to figure out is choosing Threadripper or Xeon-w. I am not sure of a similar website for Epyc so that was not included. I have been thinking I could add 1-2 gpus for additional value and variety of work – kind of liking the additional possibilities: render 3D resulting images rather than just 2d, gpu accelerated simulations via PyTorch, AI inference for go (game), image generation, etc… Maybe going with a generation old is worth thought. Not sure about future proofing or upgrading then though.
- System76: 11 182$
- Threadripper Pro 59995wx, RTX A4000 16GB, 128 GB RAM, 2x 1TB SSD
- I happened across this vendor. Apparently they are less than 100 min away from me. Who knew! Do any of you have a good experience with them?
- PugetSystems: 11 672$
- Threadripper Pro 59995wx, RTX A4000 16GB, 128 GB RAM, 1x 1TB SSD
- Lenovo: 11 708$
- Threadripper Pro 59995wx, T400 8GB, 128 GB RAM, 2x 256GB SSD
- Quote includes a 45% discount (via a code?). I am not sure how much I can rely on that. Though my work seems to have suddenly fell in love with Lenovo so maybe I can get a deal through them.
- Dell: 10 915$
- Intel w9-3475x, RTX A4000 16GB, 128 GB RAM, 1x 512 GB SSD
- Lenovo seems to sell a generation prior of these cpus.
I am not sure on RAM total. Initially I thought that 2GB/core would be fair. Given that I may have to ultimately write upto 25GB, I am not sure.
The EGSnrc Fortran code is officially known/intended to compile for gcc-fortran. I will have to read about Nvidia’s Cuda Fortran. There are some academic papers claiming to run it on a GPU with upto 60x performance (2011-2013) though without links or code included. I am hoping to get that working if I can on my machine. Maybe that means I should think about GPUs too? EGSnrc is better for my therapy-oriented simulations while GEANT4 is more shielding-oriented and general purpose.
Not sure if MHz*cores is enough. Seems like number of channels, bandwidth, and bus speed(?) are important judging from the posts here. Thanks for the notice on the F line. I had not heard or seen it. I will look into whether anyone mentions optimizations for Intel/AMD. There is no vendor. Both are open source libraries.
MikeGrok, I think we will have to discuss these configurations more. 96 cores is enticing. You seem to demonstrate the economic power of building myself.
I expect more cache means that each core is better able to hold the data needed and the computation results. As twin_savage says, big cache may be a hindrance if it cannot be moved back and forth well.