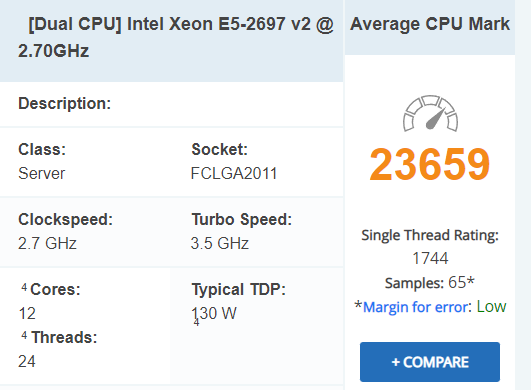
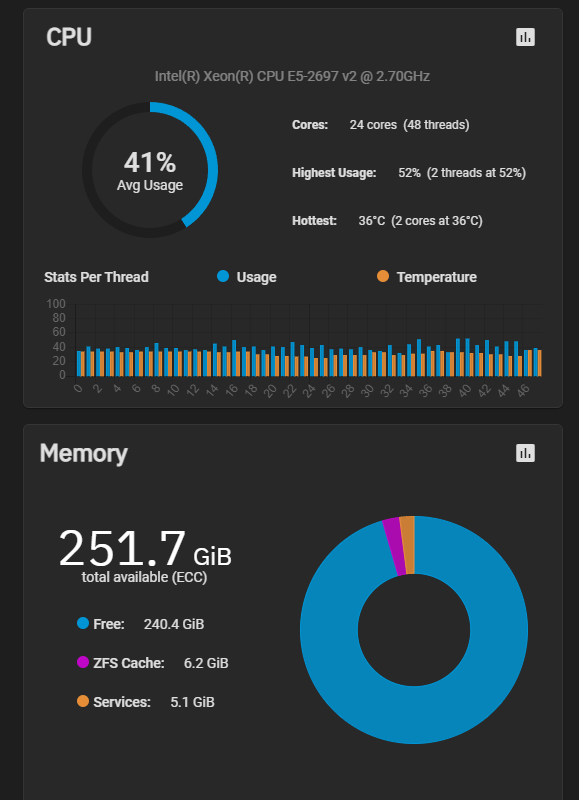
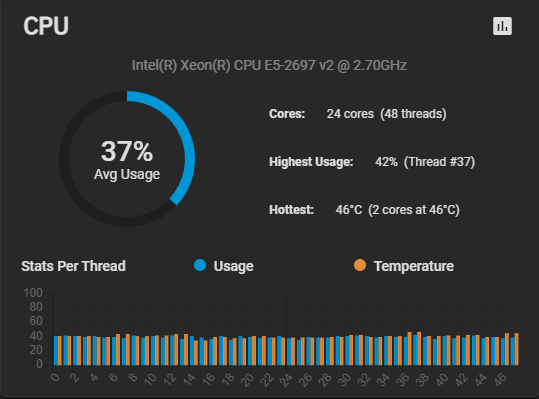
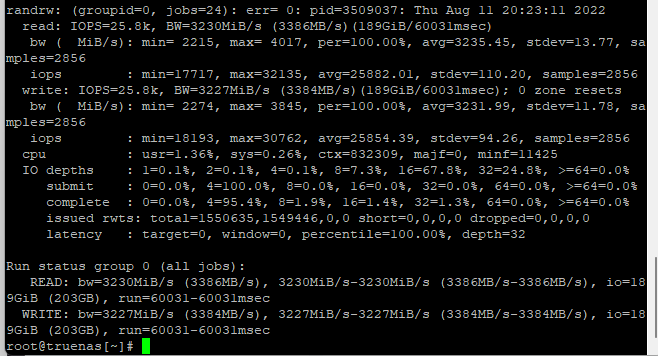
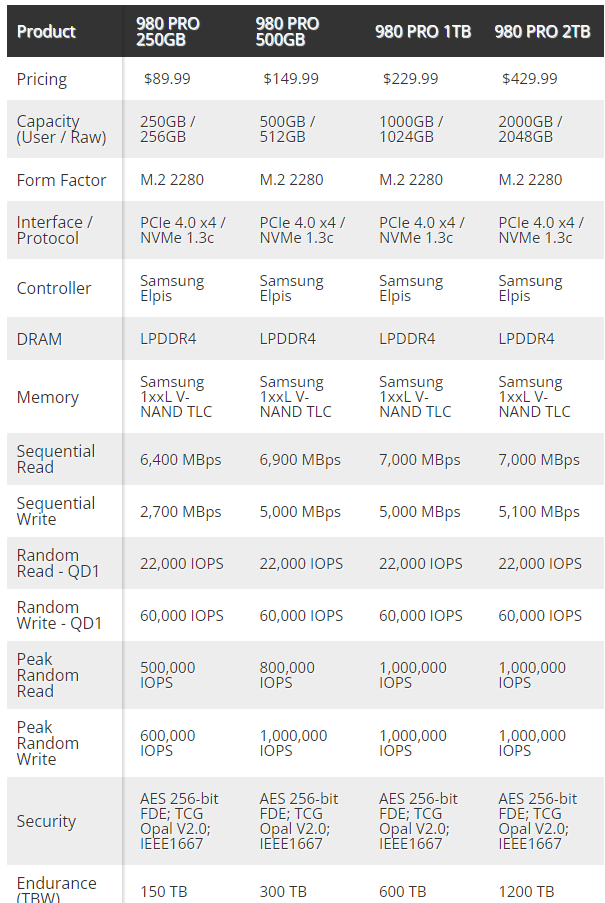
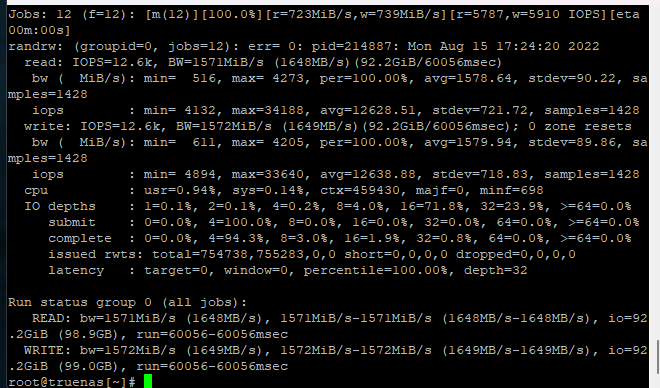
Reviewed content and with the knowledge gained from our testing could understand it better than the first time.
I could not find the actual fio command Wendell ran during these tests. But later in the thread Chuntzu documented his test cases well.
They were going for max io (instead of max bandwidth in our test). So, the main difference I saw was that they used the smallest block size (4k) and more importantly Chuntzu used a different ioengine.
Let’s try the ioengine. I start by formatting a partition on each 970 pro into ext4 and mounting them.
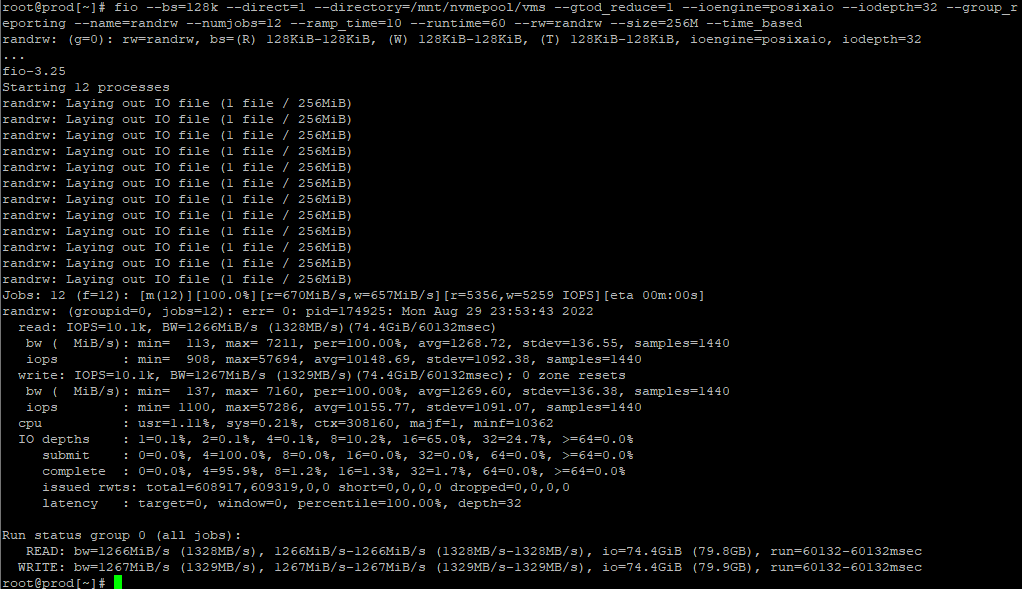
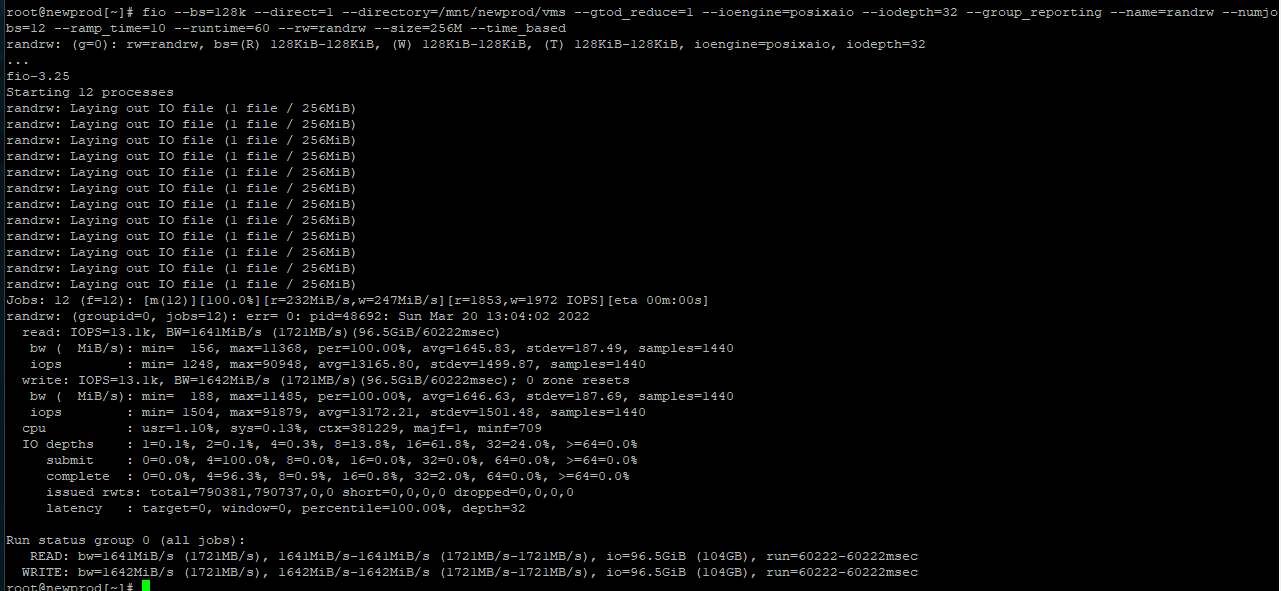
First, test with our current command and setup:
[test]# fio --bs=128k --direct=1 --gtod_reduce=1 --ioengine=posixaio --iodepth=32 --group_reporting --name=randrw --numjobs=12 --ramp_time=10 --runtime=60 --rw=randrw --size=256M --time_based --directory=/mnt/nvme0:/mnt/nvme1:/mnt/nvme2:/mnt/nvme3
randrw: (g=0): rw=randrw, bs=(R) 128KiB-128KiB, (W) 128KiB-128KiB, (T) 128KiB-128KiB, ioengine=posixaio, iodepth=32
...
fio-3.26
Starting 12 processes
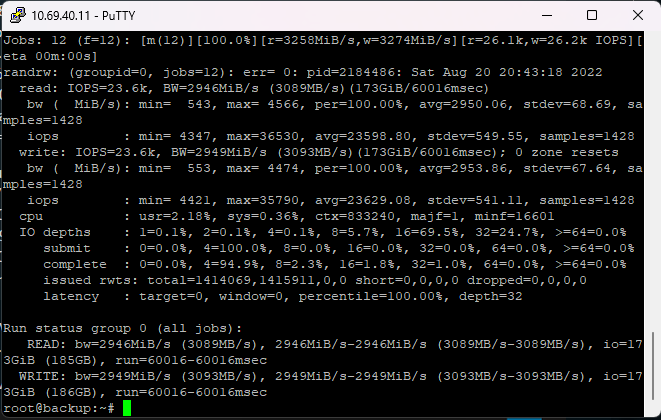
Jobs: 12 (f=12): [m(12)][100.0%][r=3329MiB/s,w=3342MiB/s][r=26.6k,w=26.7k IOPS][eta 00m:00s]
randrw: (groupid=0, jobs=12): err= 0: pid=19615: Sat Aug 13 22:37:10 2022
read: IOPS=26.9k, BW=3364MiB/s (3527MB/s)(197GiB/60022msec)
bw ( MiB/s): min= 3077, max= 3762, per=100.00%, avg=3366.47, stdev=12.98, samples=1430
iops : min=24617, max=30102, avg=26931.42, stdev=103.81, samples=1430
write: IOPS=27.0k, BW=3370MiB/s (3533MB/s)(198GiB/60022msec); 0 zone resets
bw ( MiB/s): min= 2987, max= 3863, per=100.00%, avg=3372.22, stdev=15.08, samples=1430
iops : min=23902, max=30911, avg=26977.45, stdev=120.64, samples=1430
cpu : usr=1.42%, sys=0.36%, ctx=804426, majf=0, minf=701
IO depths : 1=0.0%, 2=0.0%, 4=0.1%, 8=25.0%, 16=50.0%, 32=25.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=97.5%, 8=0.0%, 16=0.0%, 32=2.5%, 64=0.0%, >=64=0.0%
issued rwts: total=1615001,1617829,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=3364MiB/s (3527MB/s), 3364MiB/s-3364MiB/s (3527MB/s-3527MB/s), io=197GiB (212GB), run=60022-60022msec
WRITE: bw=3370MiB/s (3533MB/s), 3370MiB/s-3370MiB/s (3533MB/s-3533MB/s), io=198GiB (212GB), run=60022-60022msec
Using Wendell’s command to monitor performance:
---procs--- ----total-usage---- ------memory-usage----- --io/total- ----system----
run blk new|usr sys idl wai stl| used free buf cach| read writ| time
0 11 3.0| 3 4 20 71 0| 22G 101G 187M 1726M|26.9k 27.0k|13-08 22:36:54
2.0 10 0| 3 4 21 71 0| 22G 101G 187M 1726M|26.4k 26.4k|13-08 22:36:55
1.0 10 0| 3 4 19 72 0| 22G 101G 187M 1726M|25.9k 25.8k|13-08 22:36:56
3.0 10 0| 4 4 20 72 0| 22G 101G 187M 1726M|26.1k 26.4k|13-08 22:36:57
1.0 11 0| 3 4 19 72 0| 22G 101G 187M 1726M|26.2k 26.4k|13-08 22:36:58
1.0 11 0| 3 4 20 71 0| 22G 101G 187M 1726M|26.4k 26.5k|13-08 22:36:59
0 12 0| 3 4 18 73 0| 22G 101G 188M 1726M|26.0k 26.4k|13-08 22:37:00
0 12 0| 3 4 20 72 0| 22G 101G 188M 1726M|26.2k 26.1k|13-08 22:37:01
3.0 10 0| 3 4 19 73 0| 22G 101G 188M 1726M|26.7k 26.5k|13-08 22:37:02
1.0 11 0| 3 4 17 74 0| 22G 101G 188M 1726M|26.7k 26.6k|13-08 22:37:03
0 13 0| 3 4 20 72 0| 22G 101G 188M 1726M|26.8k 26.8k|13-08 22:37:04
0 12 0| 3 4 19 72 0| 22G 101G 188M 1726M|26.4k 26.9k|13-08 22:37:05
0 12 0| 3 4 19 72 0| 22G 101G 188M 1726M|26.5k 26.4k|13-08 22:37:06
0 12 0| 3 4 20 71 0| 22G 101G 188M 1726M|26.4k 26.5k|13-08 22:37:07
2.0 11 0| 3 4 20 72 0| 22G 101G 188M 1726M|26.4k 26.6k|13-08 22:37:08
1.0 12 0| 3 4 20 71 0| 22G 101G 188M 1726M|26.8k 26.8k|13-08 22:37:09
Observation: pretty consistent 26k io, 71% wait time, 20% idle.
Let’s switch ioengine from “posixaio” to “aio”
[test]# fio --bs=128k --direct=1 --gtod_reduce=1 --ioengine=aio --iodepth=32 --group_reporting --name=randrw --numjobs=12 --ramp_time=10 --runtime=60 --rw=randrw --size=256M --time_based --directory=/mnt/nvme0:/mnt/nvme1:/mnt/nvme2:/mnt/nvme3
randrw: (g=0): rw=randrw, bs=(R) 128KiB-128KiB, (W) 128KiB-128KiB, (T) 128KiB-128KiB, ioengine=libaio, iodepth=32
...
fio-3.26
Starting 12 processes
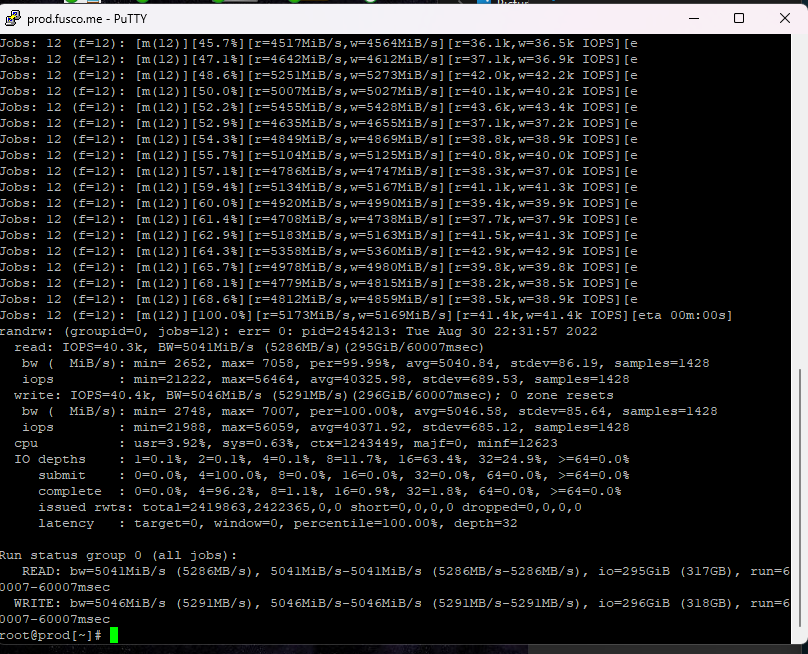
Jobs: 12 (f=12): [m(12)][100.0%][r=5244MiB/s,w=5320MiB/s][r=41.9k,w=42.6k IOPS][eta 00m:00s]
randrw: (groupid=0, jobs=12): err= 0: pid=19694: Sat Aug 13 22:42:23 2022
read: IOPS=42.6k, BW=5331MiB/s (5590MB/s)(312GiB/60015msec)
bw ( MiB/s): min= 4932, max= 5745, per=100.00%, avg=5339.46, stdev=15.05, samples=1428
iops : min=39457, max=45960, avg=42714.58, stdev=120.43, samples=1428
write: IOPS=42.7k, BW=5338MiB/s (5598MB/s)(313GiB/60015msec); 0 zone resets
bw ( MiB/s): min= 4895, max= 5739, per=100.00%, avg=5346.25, stdev=15.19, samples=1428
iops : min=39159, max=45915, avg=42768.93, stdev=121.54, samples=1428
cpu : usr=5.30%, sys=16.02%, ctx=4366045, majf=0, minf=700
IO depths : 1=0.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=2559394,2562837,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=5331MiB/s (5590MB/s), 5331MiB/s-5331MiB/s (5590MB/s-5590MB/s), io=312GiB (335GB), run=60015-60015msec
WRITE: bw=5338MiB/s (5598MB/s), 5338MiB/s-5338MiB/s (5598MB/s-5598MB/s), io=313GiB (336GB), run=60015-60015msec
Wow! That’s much more performance! And the utilization?
---procs--- ----total-usage---- ------memory-usage----- --io/total- ----system----
run blk new|usr sys idl wai stl| used free buf cach| read writ| time
7.0 0 0| 11 17 66 0 0| 22G 101G 193M 1726M|42.6k 42.5k|13-08 22:42:14
4.0 0 0| 12 17 66 0 0| 22G 101G 193M 1726M|42.9k 43.1k|13-08 22:42:15
1.0 0 0| 11 17 66 0 0| 22G 101G 193M 1726M|43.5k 43.3k|13-08 22:42:16
3.0 0 0| 12 17 66 0 0| 22G 101G 193M 1726M|42.9k 43.3k|13-08 22:42:17
3.0 0 5.0| 12 17 66 0 0| 22G 101G 193M 1726M|43.6k 43.2k|13-08 22:42:18
2.0 0 0| 11 16 66 0 0| 22G 101G 193M 1726M|42.7k 42.9k|13-08 22:42:19
4.0 0 0| 11 16 67 0 0| 22G 101G 193M 1726M|42.4k 42.4k|13-08 22:42:20
3.0 0 0| 11 16 67 0 0| 22G 101G 193M 1726M|41.8k 42.0k|13-08 22:42:21
5.0 0 0| 11 17 67 0 0| 22G 101G 193M 1726M|42.3k 42.3k|13-08 22:42:22
4.0 0 0| 11 16 67 0 0| 22G 101G 193M 1726M|41.9k 41.9k|13-08 22:42:23
0 0 0| 5 9 83 0 0| 22G 101G 193M 1721M|21.4k 21.7k|13-08 22:42:24
No wait time, about 30% CPU utilization (hmm - a few percent are missing…). IOs are up to ~42k reads and writes.
Nice! 
Man! The ioengine used in our tests was a serious bottleneck.
Just for giggles: what’s the max io we can get from this setup?
Changing to block size 4k
]# fio --bs=4k --direct=1 --gtod_reduce=1 --ioengine=aio --iodepth=32 --group_reporting --name=randrw --numjobs=12 --ramp_time=10 --runtime=60 --rw=randrw --size=256M --time_based --directory=/mnt/nvme0:/mnt/nvme1:/mnt/nvme2:/mnt/nvme3
randrw: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=32
...
fio-3.26
Starting 12 processes
Jobs: 12 (f=6): [m(2),f(1),m(1),f(2),m(1),f(2),m(1),f(2)][100.0%][r=2915MiB/s,w=2920MiB/s][r=746k,w=748k IOPS][eta 00m:00s]
randrw: (groupid=0, jobs=12): err= 0: pid=20126: Sat Aug 13 23:07:54 2022
read: IOPS=748k, BW=2920MiB/s (3062MB/s)(171GiB/60001msec)
bw ( MiB/s): min= 2728, max= 3031, per=100.00%, avg=2922.61, stdev= 3.89, samples=1434
iops : min=698602, max=775935, avg=748185.33, stdev=996.78, samples=1434
write: IOPS=748k, BW=2921MiB/s (3063MB/s)(171GiB/60001msec); 0 zone resets
bw ( MiB/s): min= 2732, max= 3039, per=100.00%, avg=2923.01, stdev= 3.86, samples=1434
iops : min=699577, max=778066, avg=748289.12, stdev=987.63, samples=1434
cpu : usr=19.39%, sys=51.05%, ctx=38317315, majf=0, minf=700
IO depths : 1=0.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=44857655,44863973,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=2920MiB/s (3062MB/s), 2920MiB/s-2920MiB/s (3062MB/s-3062MB/s), io=171GiB (184GB), run=60001-60001msec
WRITE: bw=2921MiB/s (3063MB/s), 2921MiB/s-2921MiB/s (3063MB/s-3063MB/s), io=171GiB (184GB), run=60001-60001msec
That’s 1.5M iops: 750k read and 750k write. Total bandwidth: about 3GB/s read and write.
A quick look at the resources:
---procs--- ----total-usage---- ------memory-usage----- --io/total- ----system----
run blk new|usr sys idl wai stl| used free buf cach| read writ| time
14 0 0| 39 60 1 0 0| 22G 101G 216M 1726M| 750k 750k|13-08 23:06:58
14 0 0| 38 61 1 0 0| 22G 101G 216M 1726M| 749k 750k|13-08 23:06:59
15 0 3.0| 38 60 2 0 0| 22G 101G 216M 1726M| 747k 746k|13-08 23:07:00
16 0 0| 38 61 1 0 0| 22G 101G 216M 1726M| 752k 752k|13-08 23:07:01
13 0 0| 38 60 2 0 0| 22G 101G 216M 1726M| 747k 748k|13-08 23:07:02
16 0 0| 38 60 1 0 0| 22G 101G 216M 1726M| 749k 751k|13-08 23:07:03
14 1.0 0| 38 60 2 0 0| 22G 101G 217M 1726M| 747k 747k|13-08 23:07:04
15 0 0| 38 60 2 0 0| 22G 101G 217M 1726M| 750k 748k|13-08 23:07:05
13 0 0| 38 61 1 0 0| 22G 101G 217M 1726M| 751k 752k|13-08 23:07:06
Now all the CPU resources are used, only -2% idle, no wait time.
Can we wring even more performance out of the SSDs? Can we use that brand new efficient io_uring kernel structure? Sure!
[test]# fio --bs=4k --direct=1 --gtod_reduce=1 --ioengine=io_uring --iodepth=32 --group_reporting --name=randrw --numjobs=12 --ramp_time=10 --runtime=60 --rw=randrw --size=256M --time_based --directory=/mnt/nvme0:/mnt/nvme1:/mnt/nvme2:/mnt/nvme3
randrw: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=io_uring, iodepth=32
...
fio-3.26
Starting 12 processes
Jobs: 12 (f=12): [m(12)][100.0%][r=3180MiB/s,w=3177MiB/s][r=814k,w=813k IOPS][eta 00m:00s]
randrw: (groupid=0, jobs=12): err= 0: pid=20034: Sat Aug 13 23:03:01 2022
read: IOPS=820k, BW=3202MiB/s (3358MB/s)(188GiB/60001msec)
bw ( MiB/s): min= 2988, max= 3328, per=100.00%, avg=3204.54, stdev= 5.03, samples=1440
iops : min=764945, max=852100, avg=820359.95, stdev=1288.78, samples=1440
write: IOPS=820k, BW=3203MiB/s (3358MB/s)(188GiB/60001msec); 0 zone resets
bw ( MiB/s): min= 2985, max= 3323, per=100.00%, avg=3205.01, stdev= 5.01, samples=1440
iops : min=764213, max=850812, avg=820481.23, stdev=1283.09, samples=1440
cpu : usr=14.24%, sys=53.69%, ctx=40252736, majf=0, minf=699
IO depths : 1=0.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=49185925,49193186,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=3202MiB/s (3358MB/s), 3202MiB/s-3202MiB/s (3358MB/s-3358MB/s), io=188GiB (201GB), run=60001-60001msec
WRITE: bw=3203MiB/s (3358MB/s), 3203MiB/s-3203MiB/s (3358MB/s-3358MB/s), io=188GiB (201GB), run=60001-60001msec
That’s >1.6M iops: 820k read and 820k write. Over 3.3GB/s read and write.
---procs--- ----total-usage---- ------memory-usage----- --io/total- ----system----
run blk new|usr sys idl wai stl| used free buf cach| read writ| time
14 0 0| 33 64 3 0 0| 22G 101G 210M 1726M| 824k 824k|13-08 23:01:58
18 0 3.0| 34 63 3 0 0| 22G 101G 210M 1726M| 823k 824k|13-08 23:01:59
15 0 0| 32 63 4 0 0| 22G 101G 210M 1726M| 817k 818k|13-08 23:02:00
15 0 0| 33 64 3 0 0| 22G 101G 210M 1726M| 821k 821k|13-08 23:02:01
14 0 0| 34 63 3 0 0| 22G 101G 210M 1726M| 817k 813k|13-08 23:02:02
14 0 0| 33 63 3 0 0| 22G 101G 210M 1726M| 824k 823k|13-08 23:02:03
14 0 0| 34 62 3 0 0| 22G 101G 210M 1726M| 816k 817k|13-08 23:02:04
14 0 0| 34 63 3 0 0| 22G 101G 210M 1726M| 826k 824k|13-08 23:02:05
12 0 0| 33 63 3 0 0| 22G 101G 211M 1726M| 819k 818k|13-08 23:02:06
15 0 0| 34 63 2 0 0| 22G 101G 211M 1726M| 823k 823k|13-08 23:02:07
15 0 0| 33 63 3 0 0| 22G 101G 211M 1726M| 822k 825k|13-08 23:02:08
15 0 0| 33 63 3 0 0| 22G 101G 211M 1726M| 818k 818k|13-08 23:02:09
Still all CPU resources consumed.
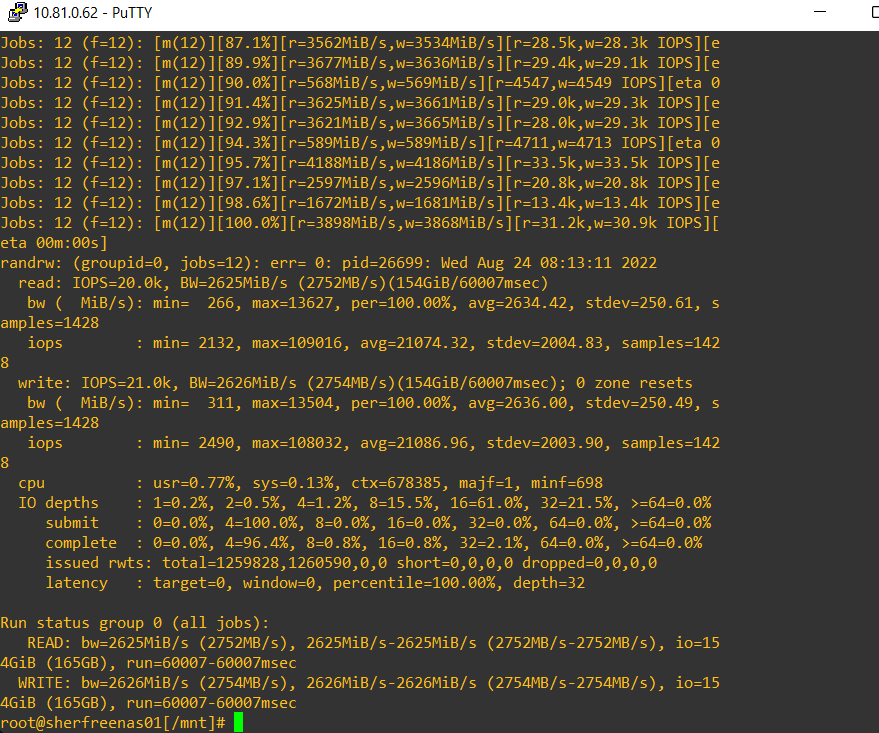
What happens when we change our test to read-only - same as Wendell did?
]# fio --bs=4k --direct=1 --gtod_reduce=1 --ioengine=io_uring --iodepth=32 --group_reporting --name=randrw --numjobs=12 --ramp_time=10 --runtime=60 --rw=randread --size=256M --time_based --directory=/mnt/nvme0:/mnt/nvme1:/mnt/nvme2:/mnt/nvme3
randrw: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=io_uring, iodepth=32
...
fio-3.26
Starting 12 processes
Jobs: 12 (f=11): [r(11),f(1)][100.0%][r=8118MiB/s][r=2078k IOPS][eta 00m:00s]
randrw: (groupid=0, jobs=12): err= 0: pid=20215: Sat Aug 13 23:15:04 2022
read: IOPS=2076k, BW=8108MiB/s (8502MB/s)(475GiB/60001msec)
bw ( MiB/s): min= 8031, max= 8164, per=100.00%, avg=8115.97, stdev= 1.79, samples=1439
iops : min=2056007, max=2090046, avg=2077685.78, stdev=459.40, samples=1439
cpu : usr=16.58%, sys=53.25%, ctx=11217210, majf=0, minf=701
IO depths : 1=0.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=124546903,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=8108MiB/s (8502MB/s), 8108MiB/s-8108MiB/s (8502MB/s-8502MB/s), io=475GiB (510GB), run=60001-60001msec
Wow! over 2M read iops, over 8GB/s bandwidth. Now, your PCIe Gen2 slot would be bottlenecked.
---procs--- ----total-usage---- ------memory-usage----- --io/total- ----system----
run blk new|usr sys idl wai stl| used free buf cach| read writ| time
10 0 0| 37 51 5 0 0| 22G 101G 224M 1726M|2076k 0 |13-08 23:14:28
12 0 0| 36 52 5 0 0| 22G 101G 224M 1726M|2076k 0 |13-08 23:14:29
12 0 0| 36 52 5 0 0| 22G 101G 224M 1726M|2077k 0 |13-08 23:14:30
10 0 0| 36 52 5 0 0| 22G 101G 224M 1726M|2078k 0 |13-08 23:14:31
11 0 0| 36 52 5 0 0| 22G 101G 224M 1726M|2076k 0 |13-08 23:14:32
9.0 0 0| 36 52 5 0 0| 22G 101G 224M 1726M|2078k 0 |13-08 23:14:33
12 0 0| 36 52 5 0 0| 22G 101G 224M 1726M|2079k 0 |13-08 23:14:34
11 0 0| 36 52 5 0 0| 22G 101G 224M 1726M|2076k 1.00 |13-08 23:14:35
Interesting: still almost full CPU utilization, but with a higher ratio in user space.
There you have it: inefficiencies in ioengine (posixaio) and file system (zfs) limit performance.


 ’
’