Is 20 million I/Ops possible on a desktop?
This is a write up for a future video from Level1techs and currently a place I’m gathering my numbers and tests. Work in process. Video soon! Probably around the first week of May 2021
Threadripper Pro to the rescue! Maybe!
We’re talking about random reads. Just a few years ago, regular NAND flash would top out at about 400,000 I/Ops per device, and most devices were more in the 250-350k range.
These days with top-end drives we’re seeing more. Much More.
Of course Intel is at the top end with it’s just recently released P5800x. However the cost per unit storage is astronomical as compared with NAND (and they do not use NAND storage under the hood).
# Intel Optane P5800X, 6 Threads, I/O Monster
...
fio-3.21
Starting 6 processes
Jobs: 6 (f=6): [r(6)][100.0%][r=1264MiB/s][r=2588k IOPS][eta 00m:00s]
onessd: (groupid=0, jobs=6): err= 0: pid=210497: Thu Apr 29 22:30:56 2021
read: IOPS=2589k, BW=1264MiB/s (1326MB/s)(37.0GiB/30001msec)
bw ( MiB/s): min= 1244, max= 1282, per=100.00%, avg=1266.10, stdev= 1.47, samples=354
iops : min=2547804, max=2626604, avg=2592965.76, stdev=3016.38, samples=354
cpu : usr=18.51%, sys=60.26%, ctx=504, majf=0, minf=36
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=77674292,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=1264MiB/s (1326MB/s), 1264MiB/s-1264MiB/s (1326MB/s-1326MB/s), io=37.0GiB (39.8GB), run=30001-30001msec
Disk stats (read/write):
nvme0n1: ios=77343935/0, merge=0/0, ticks=375255/0, in_queue=375255, util=99.98%
It has sequential read speeds of 7.8 gigabytes per second and random queue depth 1 reads are about an order of magnitude faster than the fastest nand-flash based device (under heavy loads). That translates to about 2.5 million IOPs in the best case scenario (!!!) on the 800gb model that I ordered.
Of course, it was also pricey, at around $1.50 per gigabyte.
If just one drive gets us 10% of the way there – imagine what could be done with ten of these drives! But (nervous chuckles) Level1 isn’t doing that well! This is CrazyTown Expensive. Use Sparingly!
Great for SLOGS, great for write cache, great for SQL transaction logs. But, like salt, don’t over do it or you’ll have a heart attack.
Enter Kioxia.
# Kioxia CM6-v
onessd: (g=0): rw=randread, bs=(R) 512B-512B, (W) 512B-512B, (T) 512B-512B, ioengine=io_uring, iodepth=32
...
fio-3.21
Starting 4 processes
Jobs: 4 (f=4): [r(4)][100.0%][r=695MiB/s][r=1424k IOPS][eta 00m:00s]
onessd: (groupid=0, jobs=4): err= 0: pid=230113: Thu Apr 29 23:00:46 2021
read: IOPS=1423k, BW=695MiB/s (729MB/s)(20.4GiB/30001msec)
bw ( KiB/s): min=707939, max=715554, per=100.00%, avg=712508.44, stdev=488.95, samples=236
iops : min=1415878, max=1431108, avg=1425016.85, stdev=977.89, samples=236
cpu : usr=14.22%, sys=65.89%, ctx=375, majf=0, minf=22
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=42693560,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=695MiB/s (729MB/s), 695MiB/s-695MiB/s (729MB/s-729MB/s), io=20.4GiB (21.9GB), run=30001-30001msec
Disk stats (read/write):
nvme11n1: ios=42501644/0, merge=0/0, ticks=3614651/0, in_queue=3614651, util=99.87%
I only have exactly one CM6 drive from Kioxia. It’s fast.
They can manage about 1.3-1.4 million random read IOPs, per drive (depending on capacity), under the most ideal conditions. This is class-leading speed for NAND. And they’re around 40-50 cents per gigabyte (in large capacities), which makes them ideal for bulk storage.
I also have several CD6 and CM5 from Kioxa – these are more bulk-storage oriented parts. I borrowed a few of these drives from Kioxia. We can expect them to operate around 770k iops.
We might not be able to hit 2 million i/ops per device, but we can make up for that with the sheer number of devices.
And, just for Giggles, I’m also testing the Samsung 980 Pro. These NAND-based devices can manage sequential I/O parity with the Intel P5800x, and their queue depth 1 performance is among the best of nand-based devices. (But even that still can’t touch the Optane P5800x. )
I have 8 of these to throw into the mix as needed.
# Samsung 980 Pro, following "warmup" prior to initial drive use.
...
fio-3.21
Starting 6 processes
Jobs: 6 (f=6): [r(6)][100.0%][r=538MiB/s][r=1103k IOPS][eta 00m:00s]
onessd: (groupid=0, jobs=6): err= 0: pid=233494: Thu Apr 29 23:06:54 2021
read: IOPS=1095k, BW=535MiB/s (561MB/s)(15.7GiB/30001msec)
bw ( KiB/s): min=538404, max=552030, per=100.00%, avg=548130.22, stdev=366.06, samples=354
iops : min=1076810, max=1104060, avg=1096260.68, stdev=732.08, samples=354
cpu : usr=6.65%, sys=83.98%, ctx=270, majf=0, minf=36
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=100.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
issued rwts: total=32843188,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=32
Run status group 0 (all jobs):
READ: bw=535MiB/s (561MB/s), 535MiB/s-535MiB/s (561MB/s-561MB/s), io=15.7GiB (16.8GB), run=30001-30001msec
Disk stats (read/write):
nvme16n1: ios=32678677/0, merge=0/0, ticks=5566667/0, in_queue=5566667, util=99.77%
Still, at 1.1 million iops, these Samsung drives still offer class-leading nand performance. They’ll hurt your pocket book a bit more at north of 45 cents/gigabyte, though. For the system configuration, I’ve gone as high as 29 NVMe – 116 PCIe lanes dedicated to storage. This system is DENSE. In reality, no one would ever do this, and it is stretching the limits of what Infinity Fabric is capable of.
There is specialty equipment out there like the Liqid Honeybadger which makes more sense – 8 m.2 NVMe slots behind a high-speed PLX bridge. One or Two of these x16 monsters is all you’d ever really want to put in a system.
For me? I’m just pushing the envelope to see what happens.
Process - Working out the Initial Config
With the system, one of the initial configurations we had was:
1x Intel P5800x
3x Intel P4801
1x Kioxia CM6-v
7x Kioxia CD6
In reality, I went through many many permutations of this hardware. Initially, I was having trouble Booting TR Pro with more than 10 NVMe installed. However, after an update from Asus on the SAGE E WX80, I was was able to boot and troubleshoot further. All of my Aorus-branded Add-in Cards that split one x16 PCIe slot to 4 * x4 PCIe slots were causing tons of PCIe errors. This was somehow related to the hard system locks.
In and of itself this is very curious – The Aorus-branded cards feature PCIe4 redrivers. The Asus AIC (which worked fine) does not have redrivers and works fine. It figures Asus would have tested their motherboard with their own add-in card (and this motherboard comes with one). However this took some time to troubleshoot.
I also have a limited number of PCIe4 to U.2 adapters (that work at PCIE4 speeds). PCIE4 cables, risers and splitters are still uncommon and it can lead to headache.
In testing the Kioxia CM6 SSD, PCIE4 vs PCI3 made the difference betwen ~800k iops and ~1.35 million iops, which is quite a large difference. Of course maximum theoretical sequential transfers are also cut from 8 gigabytes/sec on PCIE4 to 4 gigabytes/sec on PCIE3.
As such, I went through several iterations and configs. I shared some of my progress with our subscribers on on Patreon and Floatplane.
Process – Working, but slower than expected
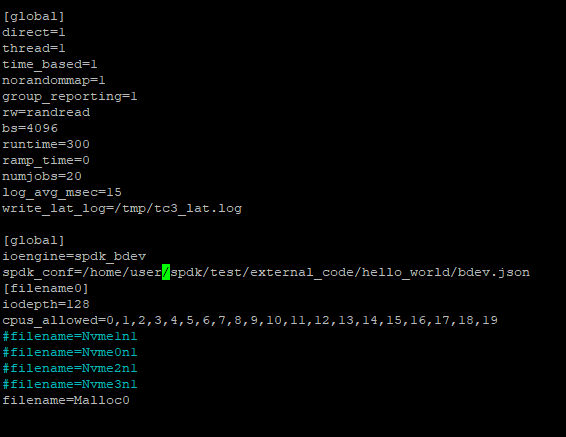
In setting this up, I settled on the fio utility. I have some scripts for it that I have posted here which exactly re-create the numbers one can expect from common utlities like CrytalDiskMark and I find it useful for testing these kinds of storage systems at scale. Building Actual Real Things one should always test to be sure exactly what reality is. Assume nothing.
The tests are posted above – but restarted
1x Intel P5800x – 2.5 million iops (wow!)
3x Intel P4801 – ~800k iops
1x Kioxia CM6-v – ~1.4 million iops
7x Kioxia CD6 – ~770k iops, each
Testing each drive individually in the working setup (some PCIE4 errors detected, but not a huge amount, and they were all corrected. PCIE4 is fast, ok?)
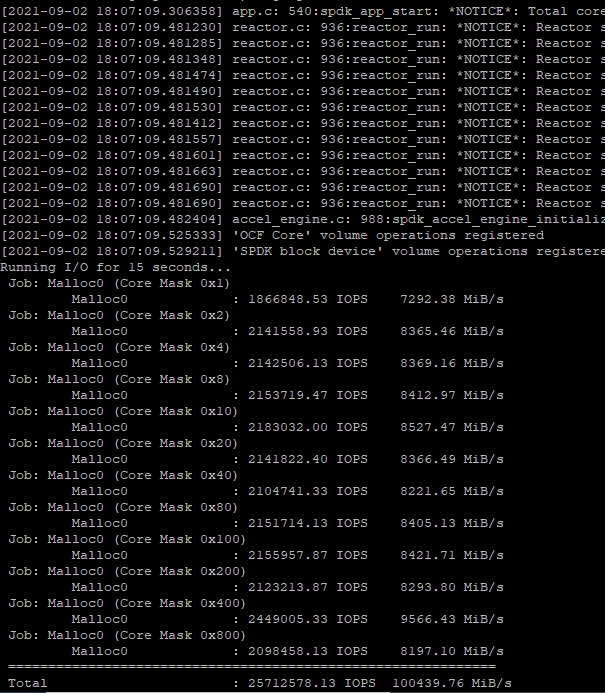
As I said in the video, if we do the math, that’s 11.6 million iops. But with the fio test? The output was 6.8 million.
What’s going on? This has already been a black hole of time. Ulgh.
Process – Troubleshooting
The first clue was in the output of lstopo. This is a handy command that will graphically show you how stuff in your system is connected. It’s a logical diagram (not a physical diagram) so you can understand which devices are tied to what pcie root complexes and this will help visualize the arrangement of things in the system.
Here we can see that all my NVMe is hanging off one PCIe root complex. This isn’t good because it can be a bit of a bottleneck. It takes so many fio threads to fully saturate each device that many i/o requests end up having to traverse the infinity fabric and everything gets all jammed up on this one node. Think hallway analogy from the video.
So, just physically re-arranging the cards gives me a little more headroom by redistributing the traffic across multiple root complexes. (Instead of everyone going into and out of the hallway at one end, we can now go in and out of the hallway at both ends and in the middle.)
AMD/Asus also provide two important tunables in the system bios:
Tunable - Preferred I/O
This one I don’t see documented very much but these root complexes have numbers. That’s the I/O bus number. You could actually pick one to priortize the traffic from this root complex will be prioritized across infinity fabric. In the liqid honey badger use case, this would be the fix for you. The reason is because you have this one single device that can deliver the full PCIE4 bandwidth and shuffling the card around the system isn’t going to help you (unless you have other devices also generating traffic on that node). In our case I will leave this alone for now (though one could argue I should prioritize the node that has all the Optane on it just because Optane is So Darn Fast).
Tunable – NPS1, NPS2, NPS3, NPS4.
Buried in the memory controller options is a very important tunable. By default TR Pro presents to the system as a single unified NUMA node. This is the best way. Astute thinkers may realize that the chiplet architecture of Threadripper (Pro, Epyc and even most Ryzen desktop CPUs) that this isn’t technically true. Chiplets that are farther from the I/O die are going to have slightly different performance. The time it takes to get data from CPU complex to CPU complex (and from I/O complex to I/O complex and from memory controller to memory controller (!!)) is also going to be somewhat variable. Imagine the scenario where a chiplet is doing I/O on the farthest possible memory controller and I/O node on the I/O die. Not only is this sub-optimal, it potentially creates a storm of traffic on infinity fabric which would negatively impact other data traffic that needs to get from A to B. If the system were smarter about which core, memory controller and I/O node were closer and which were father, the process scheduler could make smarter choices about where to run code.
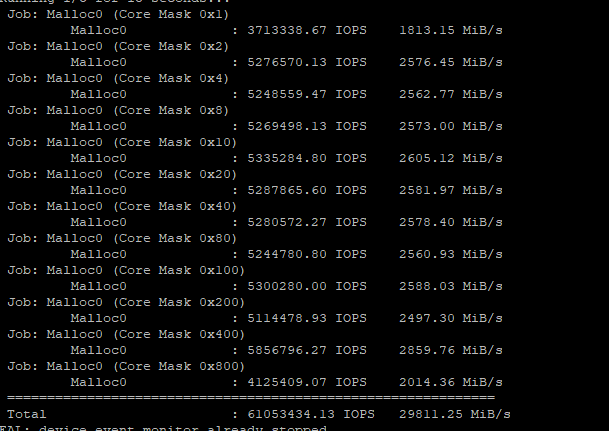
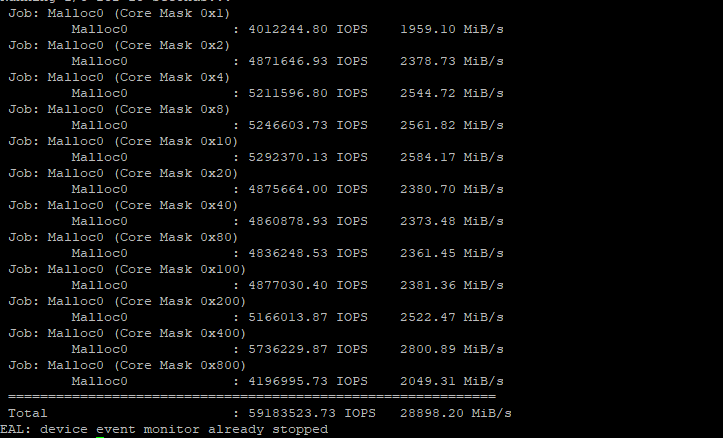
I set NPS4 chasing more than 14 million I/OPs. With that, and careful CPU pinning, I was able to get from ~14.1 million iops to 15 million I/OPs, but overall I don’t think it would be worth it to change from the default NPS1 (even for this scenario).
From 6.8 million iops to 10 million to 15 million iops
TODO
Isolating just NPS4 Benefits
So here’s the same system and benchmark with NPS1:
--procs--- ----total-usage---- ------memory-usage----- --io/total- ----system----
run blk new|usr sys idl wai stl| used free buf cach| read writ| time
67 0 | | 22G 477G 63M 21G| |09-05 12:42:59
67 0 9.0| 32 68 0 0 0| 22G 477G 63M 21G|13.6M 0 |09-05 12:43:00
67 0 6.5| 32 68 0 0 0| 22G 477G 63M 21G|13.6M 3.00 |09-05 12:43:01
67 0 10| 32 68 0 0 0| 22G 477G 63M 21G|13.6M 0 |09-05 12:43:02
68 0 4.0| 31 68 0 0 0| 22G 477G 63M 21G|13.8M 0 |09-05 12:43:03
67 0 9.0| 31 69 0 0 0| 22G 477G 63M 21G|13.9M 0 |09-05 12:43:04
68 0 5.0| 32 68 0 0 0| 22G 477G 63M 21G|13.9M 0 |09-05 12:43:05
3.0 0 72| 27 63 9 0 0| 20G 480G 63M 20G|12.1M 0 |09-05 12:43:06
vs. the 14.8-15.2 million IOPs we saw in NPS4. In reality what’s happening here is the kernel and interrupt machinery is tending to have cores physically more near the SSDs service the interrupts. That better distributes the I/O load across infinity fabric, and that’s good for another million IOPs or so. Your specific application may suffer in other ways from NPS1 vs NPS4, so it’s up to you to test. Generally I recommend sticking with NPS1 in the real world. Still, this is useful knowledge in understanding how it works behind the curtain.
What else is there for tuning? What about _______ ?
Look, I am still chasing that 20 million iops white whale. I haven’t given up. Will Zen3 do it? Epyc Milan? I’m 95% sure it’ll be no problem on Dual Socket Epyc (whether that’s Rome or Milan, sounds like a future video…)… but one socket? I’m not so sure. It is true there will be less infinity fabric traffic for core-to-core communications on the same chiplet. Hmmm…
For the software end of things we have here, this is kernel 5.12. And a recent distro (Fedora 33/34 for this testing). It is already pretty well-tuned out of the box. I love that! Linux has really moved as fast as the state of the art here and that’s great for users.
It uses the new hybrid polling right out of the box (low cpu overhead, low latency, and less overhead than a storm of interrupts in this kind of workload). Technically that is ‘none’ for the i/o scheduler.
The reason is that a proper i/o scheduler has cpu overhead. We’re on the order of about 10k cpu cycles to service a 4k I/O request with any of these devices. At ~4.2GHz this is a vanishingly small amount of time to worry about anything. ‘None’ really does make the most sense here.
It is possible to go straight polling and maybe improve the overall latency, but the CPU usage would then be astronomical. It doesn’t make good logical sense to do this for real-world usage. Hybrid polling in the Linux Kernel really is the cleanest and most brilliant solution here.
Read-ahead is, maybe, another thing that could go away, or not. In reality I think you’d want it.
smartctl -a /dev/nvmeX and read ahead can be disabled. Conventional wisdom is that it isn’t needed for SSD-based systems but I’ve found there is so little penalty from reading “a little bit more” on fast disks that it mostly doesn’t matter. Still, for benchmarking purposes, we can disable it here and maybe squeeze out a few extra i/ops.
Of course the CPU performance governor should be set to performance. It’s probably not worth checking, but be aware that nvme have different power modes. In at least one instance in my career I’ve seen either the backplane or bios of the system set the NVMe to a lower power teir (which was worse performance). The NVME CLI utilities on Linux will unambiguously tell you about those variables.
Conculsion
As for now, the question remains unanswered. 10+ million? E-Z. 15 Million? Achieved, but we’re starting to see that exponential fall-off curve and we’re having to look at the physical system topology to make sure NVMe devices are evenly distributed across all our possible PCIe resources. The CPU usage is kind of high and we might be looking at excessive spinlock contention within the kernel. Further investigation is required. Stay tuned for part 2! And if you have any ideas for performance tuning, let me know.
# Fifteen high-speed PCIE4 NVMe devices + One P5800X Optane
# dstat -pcmrt
---procs--- ----total-usage---- ------memory-usage----- --io/total- ----system----
run blk new|usr sys idl wai stl| used free buf cach| read writ| time
85 0 9.0| 32 67 0 0 0| 23G 476G 168M 21G|14.1M 142 |29-04 22:53:30
85 0 4.0| 33 68 0 0 0| 23G 476G 168M 21G|14.1M 0 |29-04 22:53:31
85 0 9.0| 33 67 0 0 0| 23G 476G 168M 21G|14.1M 0 |29-04 22:53:32
85 0 3.0| 33 67 0 0 0| 23G 476G 168M 21G|14.1M 0 |29-04 22:53:33
14.1 million IOPs! wow!
Of course, I’m not doing anything useful. Yet.
I need to know what I’m up against, in terms of main memory bandwidth. Do I have enough storage to saturate how fast the processor can do stuff with main memory? Let’s find out:
# sysbench --test=memory --memory-block-size=8M --memory-total-size=400G --num-threads=32
409600.00 MiB transferred (111097.22 MiB/sec)
General statistics:
total time: 3.6861s
total number of events: 51200
Latency (ms):
min: 0.29
avg: 2.24
max: 15.62
95th percentile: 3.07
sum: 114538.23
Threads fairness:
events (avg/stddev): 1600.0000/0.00
execution time (avg/stddev): 3.5793/0.08
So it looks like yes, that’s something to worry about. While on the EPYC server platform I could potentially have two sockets and 16 memory channels to work with, Threadripper Pro is 8 memory channels. That’s a theoretical 200 gigabytes/sec at 3200MT/s, but real world? This is what you see from sysbench. ~115 gigabytes/sec. I can work with this, though.
Update: After a bit of tuning