Well, Intel’s situation is very different for numerous reasons, but that is going off-topic. I’ll try to address it in relation to the problems of fabs and processes.
First, Intel’s problem is mostly not their own, unless they didn’t listen to the one engineer that is claiming he told them to move cannon lake or ice lake to 14nm back in 2015 or 2016. (can’t find the article from around April of this year, but found this longer quote of him in the Anandtech forums - leaving whole quote so that it is not read out of context, the articles I read just mentioned blurbs out of this whole statement, which made him sound a bit disgruntled, so more info for me as well; https://forums.anandtech.com/threads/david-schor-intel-10nm-in-big-problems.2544009/)
"Francois Piednoel said:
You are confusing marketing “naming” of the process and the transistor performance at peak performance level. **There are still no match for intel 14nm++ transistor**,I can bet a lot that you will see a huge increase in idle power of this new 7nm. What Apple ship in 2018 will tell
You guys will did not learn what happen when intel is in trouble? They set up dungeons, super secretive ones, then, they go dark, for Core2Duo, we were 10 with the real story, the rest of the world was predicting AMD taking over.
**Today, I agree that there was management mistake, ICL should have been pull down to 14nm++, process tech should not hold back architecture**, but that should tell you that chipzilla is now planning a double whammy, and when this will come out, that is going to break teeth.
And historically, it is a very bad idea to bid again intel recovering, they always do, because that their scale, there are excellent people, the management of nice guys just need to empower them, instead of protecting their sits. IDC here I come again ...
So, when you “hear” stuffs , you most likely hear from an non inform person, so, value is useless, I remember being in meeting with intel senior fellows and not being able to tell them what was going on with Core2Duo, and being destroyed because Cedarmill was sucking [butt] at SSE3
Few days before we showed Core2Duo to the press for the 1st time, most of intel Top management had no clue. Slowly, those VPs got moved outside intel or retired, I predict this is going to happen again. (Please don’t ask names, they are pretty obvious, but by respect , don’t)
I was in the meeting when we canned Tejas. My friends worked hard on that, it was a cathedral of architecture, sadly, the physic limits killed it, many ideas got recycled in processors you use today. Most people miss-understand what was Tejas, because the fanboys only know the name.
**I know the reason of all of those delays, but I can't say it because I am under NDA. It is fixable, and my estimate is that it should be fixed shortly.**
Yes, the people working on C2D were in IDC, and the information about the performance of C2D was "roomed", non of the Oregon team had any clue of what was coming (except one apple related), because you did not want to discourage the guys trying to make netbust go faster.
Fellows are very smart, very very smart (There are exceptions ... don't ask ;-) , but if they don't need to know, they don't get to know, especially if you plan to wipe competition as C2D did.
My lawyer agree that in 2019, my knowledge of what is going on at intel will be less significant, and I will be allowed to start speaking.
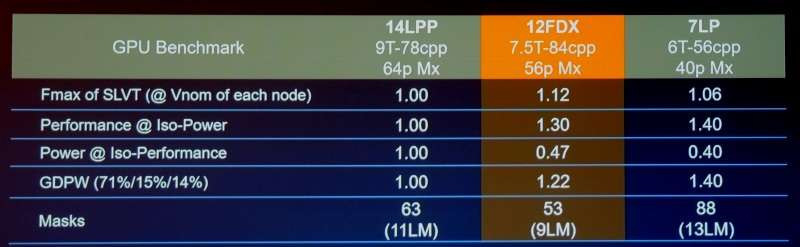
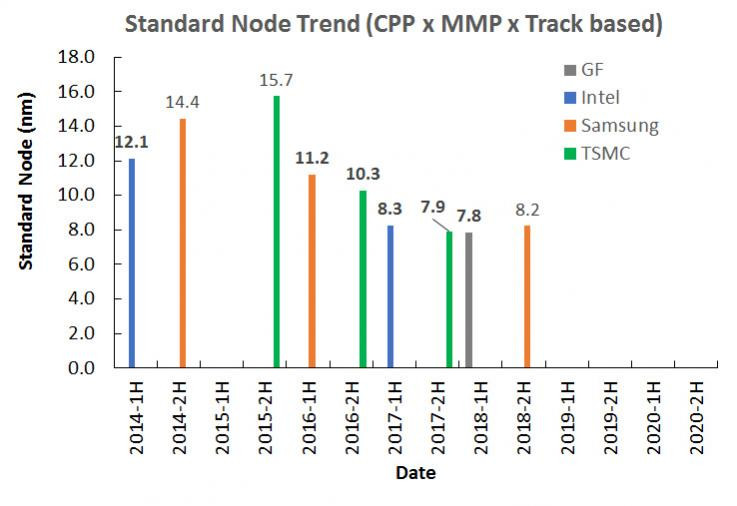
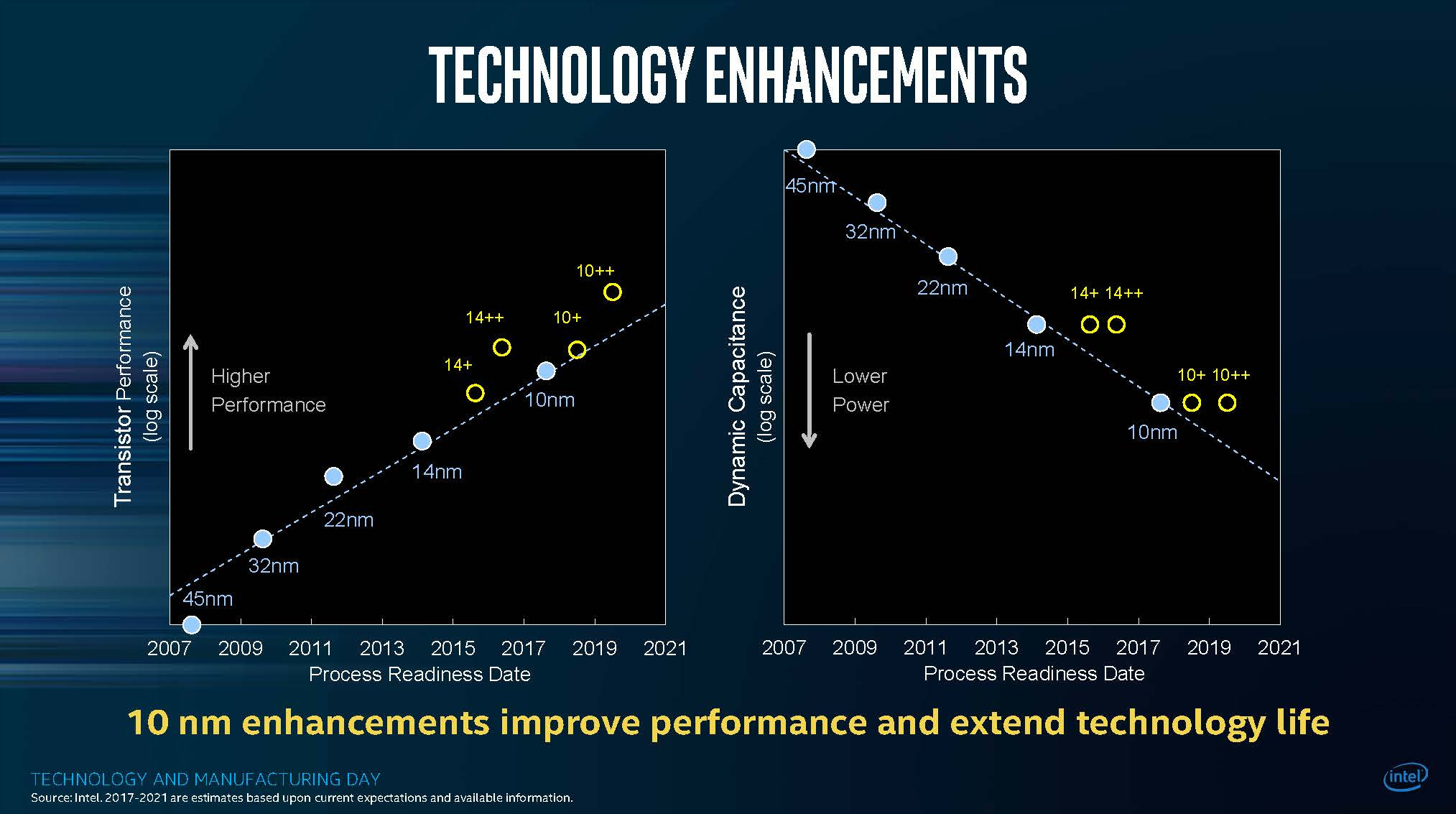
The ARM camps has for sure won the "perception" battle, at least the "nm" naming battle, those 2 slides are comparing and , on the top of this, non of those graph tell you about the Cdyn other important factors, or leakage at high voltage and low voltage, it is to compare
**Keep in mind that increasing IPC is not linear to the increase of transistors,the amount of IPC increase will depend on a lot of simulation, how accurate they are, and the scale of your R&D, this is where IPC increase is going.** Now,chipzilla has 3 years of architecture to release"
Important part there is that the architect supposedly warned Intel to pull in Ice Lake for14nm++ process a couple years ago, which was not listened to. He may be a bit hyperbolic and have strong statements regarding other fabs processes, specifically not looking at TSMC 10nm process, nor that 7nm is now in volume production. This statement was also made before Intel mentioned in Q2 earnings that 10nm chips would not arrive until Holidays 2019, and server in 2020, or that EUV is delayed until 2021. So, please do not judge the bravado or his strong stance on a former employer as misguided, when he made the statement, it was mostly true, considering 10nm TSMC doesn’t have the volume of 14nm, etc. But insight can be gained.
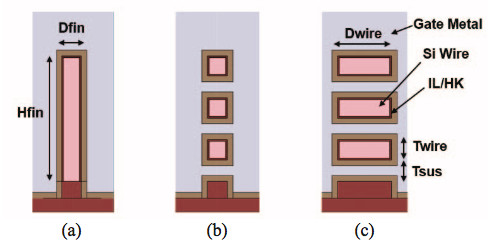
Intel’s issues come in defect densities related to SAQP, which is quad patterning, and certain decisions on cobalt (going to the smaller end for the same that every fab was looking at for their 7nm, which is equivalent to Intel 10nm density), contact over active gate (COAG), and on moving to a single dummy gate (discussed above in the iedm/isscc link, as well as the March 29, 2017 press day materials for their scaling). It is my belief not that the engineering is bad, just that the quad patterning is causing too many defects and that because of the physical limitations they are running into due to expecting EUV back in 2015 or 2016, they did not plan accordingly. So, insofar as EUV delay is involved, I do not fully blame Intel as EUV readiness was beyond their control. With that said, not changing direction or taking advice internally IS something that I can blame them for and will do so readily. No real excuse for not listening to those engineers and architects on the front line, so to speak.
Because of that, and EUV not being ready, and likely quad patterning or sextuplet patterning, and defect densities, I think Intel is removing some of the density to get it out the door, which is what semiaccurate has discussed and is linked, in part, above on the 12nm comments about Intel’s 10nm. With the rumors that it will be gutted to get out the door, with 10nm expected next christmas time frame (could be anywhere in Q4), and the announcement of not using EUV until 2021, we could see the Intel 10nm be a lesser process compared to 7nm at TSMC and potentially Samsung, but certainly after EUV adoption, which simplifies it from quad patterning and above down to dual patterning and allows for some designs that would not otherwise be possible. Intel then having EUV 7nm in 2021 needs discussed, such as whether it will keep the current density calculations or if it needs adjusted due to the gutting of 10nm. Intel’s 7nm is more comparable to around 3nm for other nodes, which also, coincidentally, meets the timelines for Samsung and TSMC, roughly, on getting to 5nm-3nm, meaning Intel may not ever have the process lead again, instead being on par with two other fabs that have larger volumes than Intel does.
But that gets into a discussion of the fight and timelines to 3nm, which should be discussed because that is where current means of producing chips breaks down, where we examine Gate All Around (IBM patented and Samsung has their own version), which can use nanowires and nanosheets, we examine III-V materials, copper trace doping, etc., to fight electromigration and quantum tunneling. This is the bleeding edge (along with nano-vacuum tubes, graphene (like learning how to inject the band gap, growing the film on substrate, etc.), optical interposers and light based solutions including photonic ram, quantum q-dot scaling and production on silicon transistor lines (great article on that, but I’d have to find it), and all that fun stuff). Other problems faced is cooling, stacking with TMV (through media VIAs, with through silicon VIAs being the most common to speak of), etc.
But, back to the point, Intel may be able to save it from doing a spin-off with the release of another high performant part, like the GPU they are planning for 2020-21. One reason they did not want it open in the past, and why competitors did not want to use it, was the process lead and the IP transfers needed to do so from all parties concerned. Now that the lead is gone, and may remain gone moving forward, the reason for keeping it close evaporates, which then requires keeping the production levels high while sinking R&D to be on the bleeding edge, etc.
But, I think I’m rambling now. Great points, hope this gives more context and information. Also, here is an article about cobalt and ruthenium in the new Intel 10nm chips, which continues the discussion on new materials and cobalt use. https://fuse.wikichip.org/news/1371/a-look-at-intels-10nm-std-cell-as-techinsights-reports-on-the-i3-8121u-finds-ruthenium/