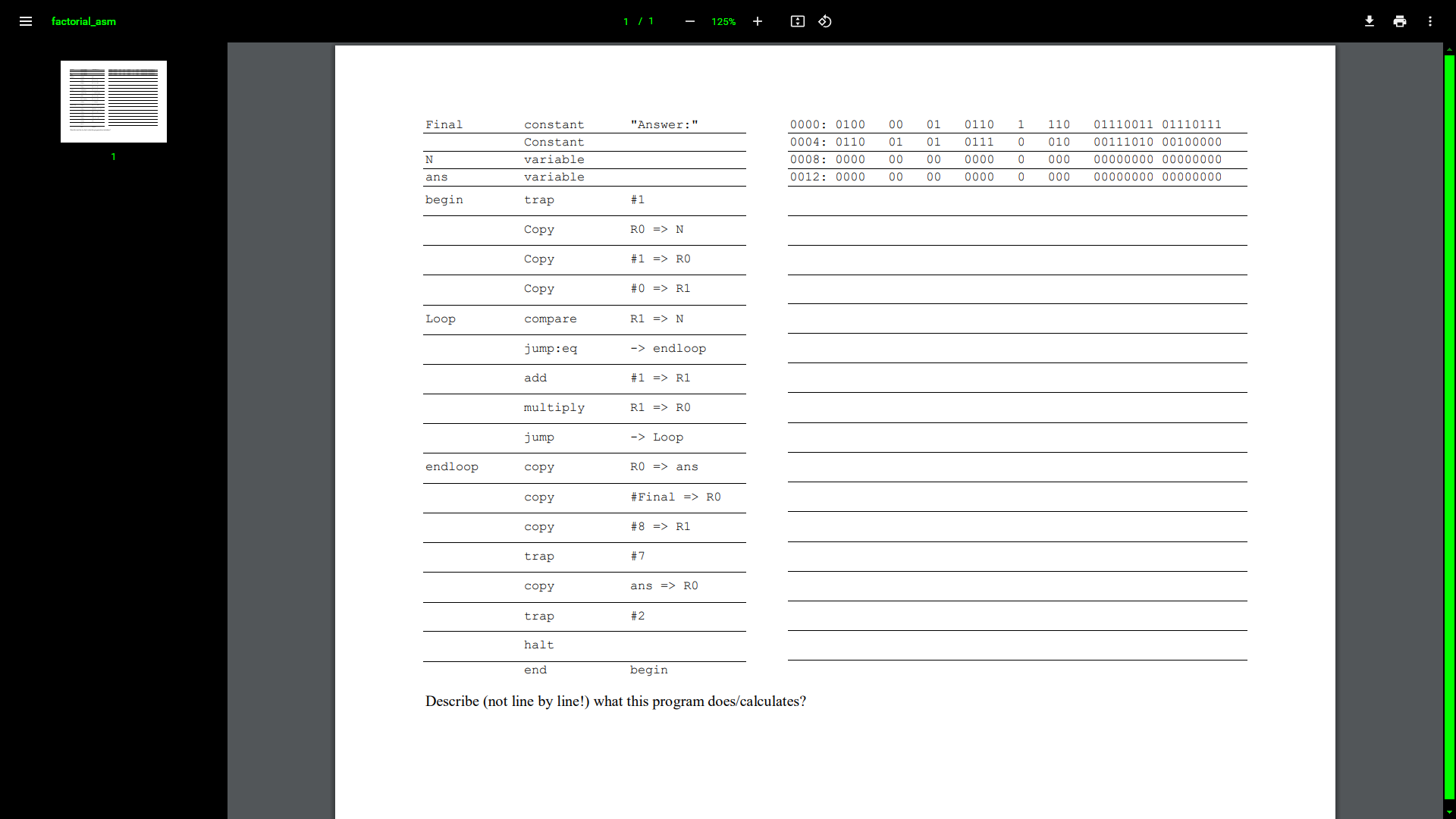
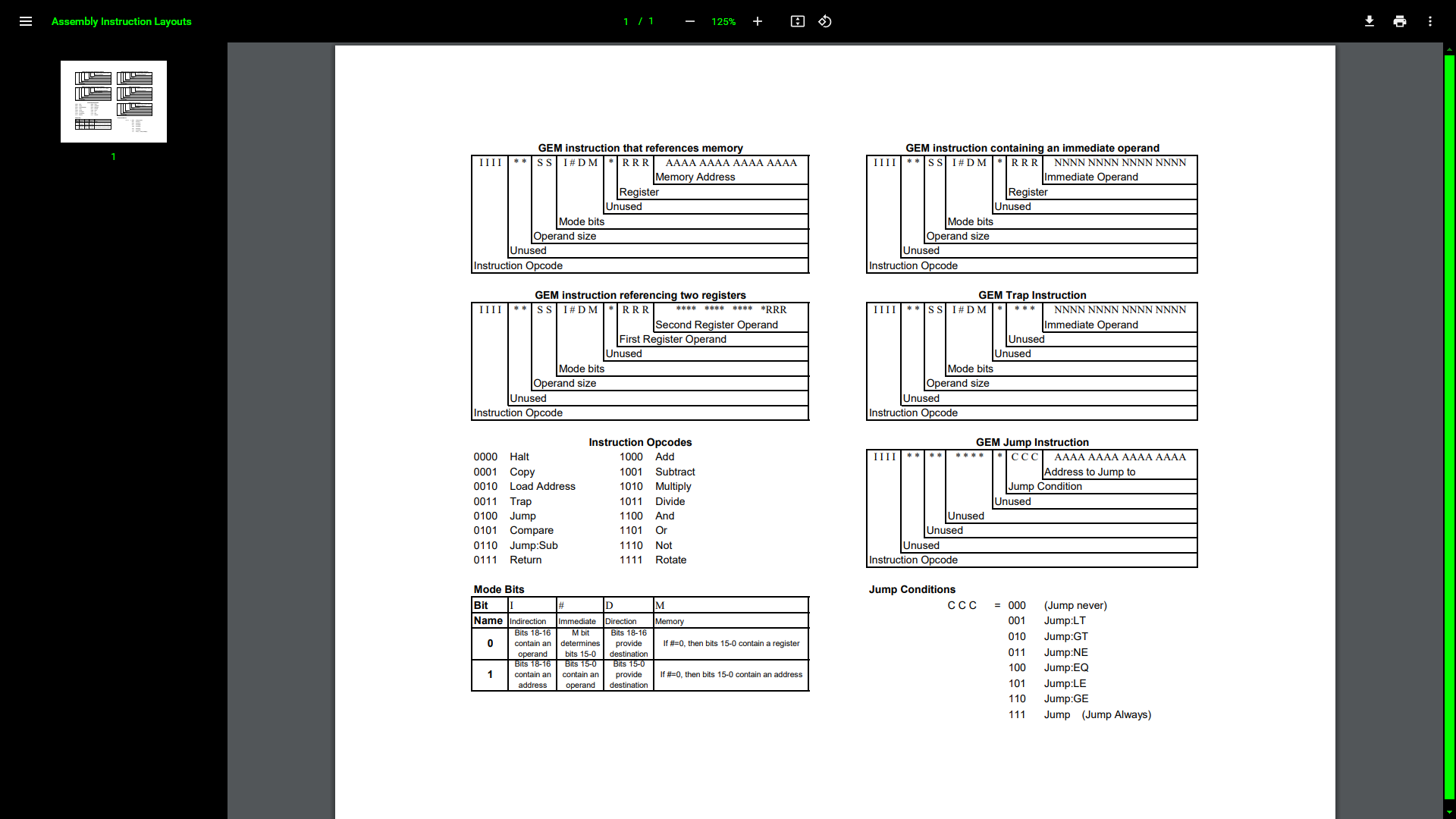
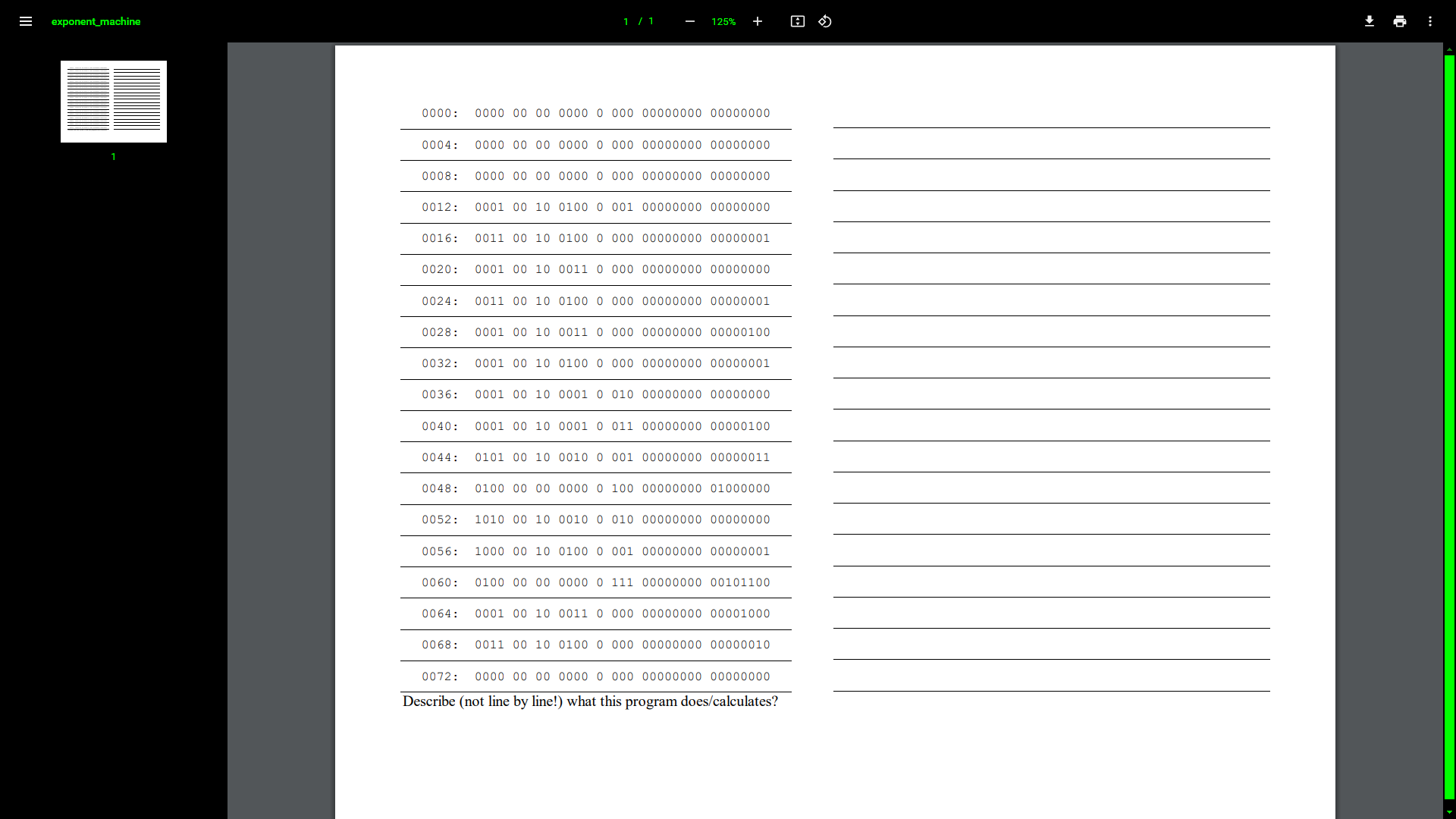
Random Design Note [2021-11-0X]
Architecting an Instruction Set Architecture subsystem:
I didn’t go into detail last year about the ISA subsystem, or why I made some… less then straight forward decisions about how to architect it. Today was that day, until I wrote it out and realized I was half way through what I wanted to say and it’s already too long.
Welp, to start off, lets start with a simple ‘add’ instruction, and assume a spherical cow.
#very psudocode
program = "add(r[0], 1, 2) \n halt" #The program, a simple two instruction program
executionTree = magicParser(program) #This turns the 'program' into an exectuion tree
ISA = {"add" : add, "halt" : magicHaltFunction} #A lookup table for what to do when encountering an instruction
def add(c, a, b): #The instruction definition
c = a + b
magicEverythingRuns(ISA, executionTree)
The main idea behind this kind of implimentation is to allow for tinkering with the ISA. You can adjust and extend that ‘ISA’ lookup table relativly easily depending on your needs. Lets dive into that idea with a little bit of code from the project. (albeit, mockup code)
#trimmed down code from the project
self.instructionSet = {
("nop",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, : self.opNop(fRead, fWrite, fConfig, EFunc, EStatus)),
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b)),
("mult",) : self.opMultiply,
("twos",) : self.opTwosCompliment,
("copy",) : self.opCopyElement,
("and",) : self.opAND,
("or",) : self.opOR,
("xor",) : self.opXOR,
("not",) : self.opNOT,
("jumpeq",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, pointer, a, b : self.opJump(fRead, fWrite, fConfig, EFunc, EStatus, "==", pointer, a, b)),
("jumpne",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, pointer, a, b : self.opJump(fRead, fWrite, fConfig, EFunc, EStatus, "!=", pointer, a, b)),
("jump",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, pointer : self.opJump(fRead, fWrite, fConfig, EFunc, EStatus, "goto", pointer)),
("shiftl",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a : self.opShiftL(fRead, fWrite, fConfig, EFunc, EStatus, des, a, fWrite("imm", 0, 1))),
("shiftr",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a : self.opShiftR(fRead, fWrite, fConfig, EFunc, EStatus, des, a, fWrite("imm", 0, 1), False)),
("halt",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, : self.sysCallSimple(fRead, fWrite, fConfig, EFunc, EStatus, "halt"))
}
def opAdd(self,
funcRead : Callable[[int or str, int or str], int], funcWrite : Callable[[int or str, int or str], None], funcGetConfig : Callable[[int or str, int or str], dict], engineFunc : Dict[str, Callable[[Any], Any]], engineStatus : dict,
registerDestination : Tuple[int or str, int or str], registerA : Tuple[int or str, int or str], registerB : Tuple[int or str, int or str]):
"""Adds registerA and registerB, stores result in registerDestination"""
a : int = funcRead(registerA)
b : int = funcRead(registerB)
bitLength : int = funcGetConfig(registerDestination)["bitLength"]
c : int = a + b
c = c & (2**bitLength - 1)
funcWrite(registerDestination, c)
This looks like a mess, but there is a method to the madness. So lets focus in on the ‘add’ instruction and break it down (and thus learn what’s behind the assumption of a spherical cow)
#more trimmed down
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b))
}
def opAdd(self,
funcRead, funcWrite, funcGetConfig, engineFunc, engineStatus,
registerDestination, registerA, registerB):
a : int = funcRead(registerA) #reading value from memory/registers
b : int = funcRead(registerB) #reading value from memory/registers
bitLength : int = funcGetConfig(registerDestination)["bitLength"] #getting info on how large the destination register is
c : int = a + b
c = c & (2**bitLength - 1) #this cuts down the value to a size that can fit in the register
funcWrite(registerDestination, c) #writing value to memory/registers
self.instructionSet is a dictionary (the lookup table), the odd part is that the keys are tuples (IE: an array of values), that just happen to be of length(1) in this example. This is mainly done for convinence, as some instruction sets can have similar instructions with different addressing modes. Like for example the Commodore 64, same instruction (Add with Carry), but several different addressing modes.
[Source [2021-11-06] 6502 / 6510 Instruction Set | C64 OS ]
#what implementing the Commodore 64 instruction set could look like
self.instructionSet = {
("adc", "#$") : somefunction immediate value
("adc", "$") : somefunction zero page memory location
("adc", "(") : somefunction indirect memory location
...
}
opAdd(), the function that is called to carry out the operation. First of note is the funcRead, funcWrite, etc… arguments, these are to allow the function access to the nessccary functions to access memory, the engine, etc. Essentially, those are the communication channels for this fuction. This allows for a lot of flexibility with instructions… arguably too much flexability; you will be able to do things you should not want to do. The final variables are registers. These can be thought of as dictionary keys of length(2), or a memory/register bank/index pair. For an example, lets make a vector add instruction, such that 8 registers get added with a value stored in another register.
def opVectorAdd(self,
funcRead, funcWrite, funcGetConfig, engineFunc, engineStatus,
registerVectorPointer, registerAmount):
amount = funcRead(registerAmount) #read a register
vector_bank, vector_index = registerVectorPointer
for i in range(8):
bitLength = funcGetConfig([vector_bank, vector_index + i])["bitlength"]
result = funcRead([vector_bank, vector_index + i])
result += amount
result = result & (2**bitLength - 1)
funcWrite([vector_bank, vector_index + i], result) #write to a register
#Note while this is possible, it's also flawed, this SHOULD read the value in registerVectorPointer, and then use that to access that index from memory bank 'm'.
#What this actually does is take the register accessed (registerVectorPointer), and uses that register's 'key' as a pointer instead of the value IN the register
#It was a mistake, but I left it in to show you can do the wrong thing if you really wanted to.
#The right way
def opVectorAdd(self,
funcRead, funcWrite, funcGetConfig, engineFunc, engineStatus,
registerVectorPointer, registerAmount):
"""adds an int (from registerAmount) to each of 8 memory bytes pointed to by registerVectorPointer"""
amount = funcRead(registerAmount) #read a register/memory
vector_index = funcRead(registerVectorPointer) #read a register/memory
for i in range(8):
bitLength = funcGetConfig(["m", vector_index + i])["bitlength"]
result = funcRead(["m", vector_index + i])
result += amount
result = result & (2**bitLength - 1)
funcWrite(["m", vector_index + i], result) #write to register/memory
Now lets get back to the self.instructionSet, and all those lambdas.
Note: lambda, for those that aren’t familiar, it’s an ‘unnamed function decliration’. (EX: add a and b; (lambda a, b : a + b))(EX: return input value incremented by one; (lambda a : a + 1)).
By using lambdas in this way, (plus a couple helper functions) we can ‘remap’ the function definitions fairly quickly
#The default, the assembly call looks like "add r[0], r[1], r[2]"
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b))
}
#lets say, rearrange it so the assembly call has the destination as the third argument, instead of the first
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, a, b, des : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b))
}
#what about an immediate value, "add r[0], r[1], 5"
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b))
}
#That's actually the same as default, as 'immediate values' automatically get loaded into an 'immediate register', so as far as the underlying opAdd function is concerned, it's just another register.
#what about if we wanted to make sure the value being added together was between a register and an immediate value? "add r[0], r[1], 5"
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b)),
("addi",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, enforceAccess(b, "imm"))),
}
def enforceAccess(register, bank) -> returns a register iff the register is the correct bank, otherwise raises an error.
#a dedicated instruction that adds 5 to a register? "add5 r[0]"
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b)),
("add5",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, des, makeImmediate(fWrite, 5)))
}
def makeImmediate(fWrite, int) -> uses fWrite to create an immediate value and immediate register which then gets returned (and passed along to opAdd)
#an accumulate instruction that takes a register and adds it to register[0]? "acc r[1]"
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b)),
("acc",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, a : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ['r', 0], ['r', 0], a))
}
#how about a vector add function, that adds an amount (3) to the memory index pointed (stored in r[0])? "addVector r[0], 3"
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b)),
("addVector",) : [
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 0], ["m", fRead(vectorPointer) + 0], amount)),
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 1], ["m", fRead(vectorPointer) + 1], amount)),
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 2], ["m", fRead(vectorPointer) + 2], amount)),
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 3], ["m", fRead(vectorPointer) + 3], amount)),
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 4], ["m", fRead(vectorPointer) + 4], amount)),
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 5], ["m", fRead(vectorPointer) + 5], amount)),
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 6], ["m", fRead(vectorPointer) + 6], amount)),
(lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, ["m", fRead(vectorPointer) + 7], ["m", fRead(vectorPointer) + 7], amount)),
]
}
#As far as the engine is concerned, this instruction simply has a list of functions of length(8) to execute, instead of the usual list of functions of length(1). As long as the arguments match properly, the engine is happy.
In essance, this allows for quickly rewiring/rewriting an instruction set without having to rewrite every instruction, because you can reuse functions by combining them with helper functions. It’s almost like microcode (except it isn’t). Actual microcode would allow you to have loops, branches, etc. This doesn’t actually allow that. To fully impliment that, there needs to be a system to jump the program counter to a separate memory bank full of actual microcode.
#IE: something like this, assuming instead of addVector working on any set of memory, it only works on the lower 8 registers
program = "addVector r[0], 3"
microcode = """
0xF0:
add r[0], r[0], arg[1]
add r[1], r[1], arg[1]
add r[2], r[2], arg[1]
add r[3], r[3], arg[1]
add r[4], r[4], arg[1]
add r[5], r[5], arg[1]
add r[6], r[6], arg[1]
add r[7], r[7], arg[1]
exitMicro
0xFF:
#Some other microCode function
"""
self.instructionSet = {
("add",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, des, a, b : self.opAdd(fRead, fWrite, fConfig, EFunc, EStatus, des, a, b)),
("addVector",) : (lambda fRead, fWrite, fConfig, EFunc, EStatus, vectorPointer, amount : self.microCode(0xF0, vectorPointer, amount)
}
def microCode() -> a kind of system call that functions more like a specialized jump to a memory bank storing microcode, and then back
Now for a quirk of the execution engine. It’s not evaluating an op-code, it’s evaluating a node tree. Which theoretically allows for greater flexibility that I haven’t quite fully explored yet.
BUT
It does allow for Very Long Instruction Word support (VLIW)(which is intended), since the execution engine will (more or less) execute instructions ‘line by line’
program = """
add(r[0], r[1], r[2])
halt
"""
#Gets turned into the following by the parser
Root
line
add
r
[
0
r
[
1
r
[
2
line
halt
#Then each 'line' is loaded into individual memory elements
memory index 0
line
add
r
[
0
r
[
1
r
[
2
memory index 1
line
halt
memory index 2
None
...
So in effect, you can relatively easily support Very Long Instruction Word (VLIW), without too much effort as it’s done by the engine by default
program = """
add(r[0], r[4], r[5]), add(r[1], r[6], r[7]), add(r[2], r[4], r[5])
halt
"""
#Gets turned into the following by the parser
Root
line
add
r
[
0
r
[
4
r
[
5
add
r
[
1
r
[
6
r
[
7
add
r
[
2
r
[
4
r
[
5
line
halt
Now for the part no one was expecting… At no point during talk about the instruction set, modifying instructions, adding new instructions, parsing programs, etc… did I actually mention op-codes, or binary.
All of the above is done without ever actually converting to binary or back.
*The instructions aren’t converted into binary machine code, and machine code isn’t decoded into an execution tree.
*The instruction definitions (EX: add instruction) are done while using regular python ints.
*The instruction definitions (EX: add instruction) are implemented without a set register length, they are operating on registers of known, but arbitrary bitlength.
*Shown above is how to make vector instructions AND Very Long Instruction Word instructions without ever having to worry about how it’s encoded into machine code.
*MicroCode is just another program, that got compiled and stored without converting to machine code. (though implementing this functionality is a far off)
*You CAN have instructions that convert their inputs into binary, do some operations, and back to ints #That’s how the two’s compliment instruction is implemented
*You CAN have a compiler that turns the instructions into machine code
*You CAN have a decoder that turns machine code into an execution tree
But you don’t need to, to tinker with the instruction set, it’s optional
I wanted to go into details about other CPU ISAs, like Intel’s x86, and Intel’s EPIC [ Explicitly parallel instruction computing - Wikipedia ], and the TIS-100, etc… But I already wrote more then I intended.
TLDR: wanted to talk about fancy computing, ended up talking about how weird my project is instead. Take 1d4 sanity damage now, 1d4 sanity damage next turn



 (here its the 31st in ten miniutes so maybe you have 2 days left)
(here its the 31st in ten miniutes so maybe you have 2 days left)