For now I’m not planning to use it for anything critical/work project related.
I’ve already got a liberated ex-mining rig GPU farm running AMD ROCm / HIP code for some of my actual data processing (lots of OCR).
The Xeon Phi I’m first going to experiment on, explore the hardware.
Test the ISA, do some microarchitecture benchmarks. Probably run some blender OpenCL renders (Xeon Phi supports OpenCL) so all sorts of opencl stuff can run on it actually. I also plan on making some OpenCL & OpenMP comparison code. Pitting both old(TeraScale) and new GPU’s against the Phi. Explore the strengths and weaknesses of both.
Possibly do some Java & Python offload experiments someone asked me about.
But mainly I’m going to just explore and document things along the way, so if you’ve got things you’d like to see run on it feel free to make suggestions.
Lastly; just as a precaution to everyone else that might not quite understand what Xeon Phi is… It’s not a graphics card. It’s a big fat CPU with an extended x86 instruction set and big vector registers that comprise some of the ‘GPU-like’ elements.
And oh goody it drinks the power, 100W at idle and already running 64C. I’ve got a delta 16K RPM
(PFM0812HE-01BFY) fan strapped to it running 4500RPM just to maintain the idle temps.
And btw Intel MPSS SDK is horrible.
And just in general the software ecosystem around this is totally not as advertised in all of the marketing and training materials.
I attribute 90% of the failure of Xeon Phi to catch on, to the mess that is the MPSS stack.
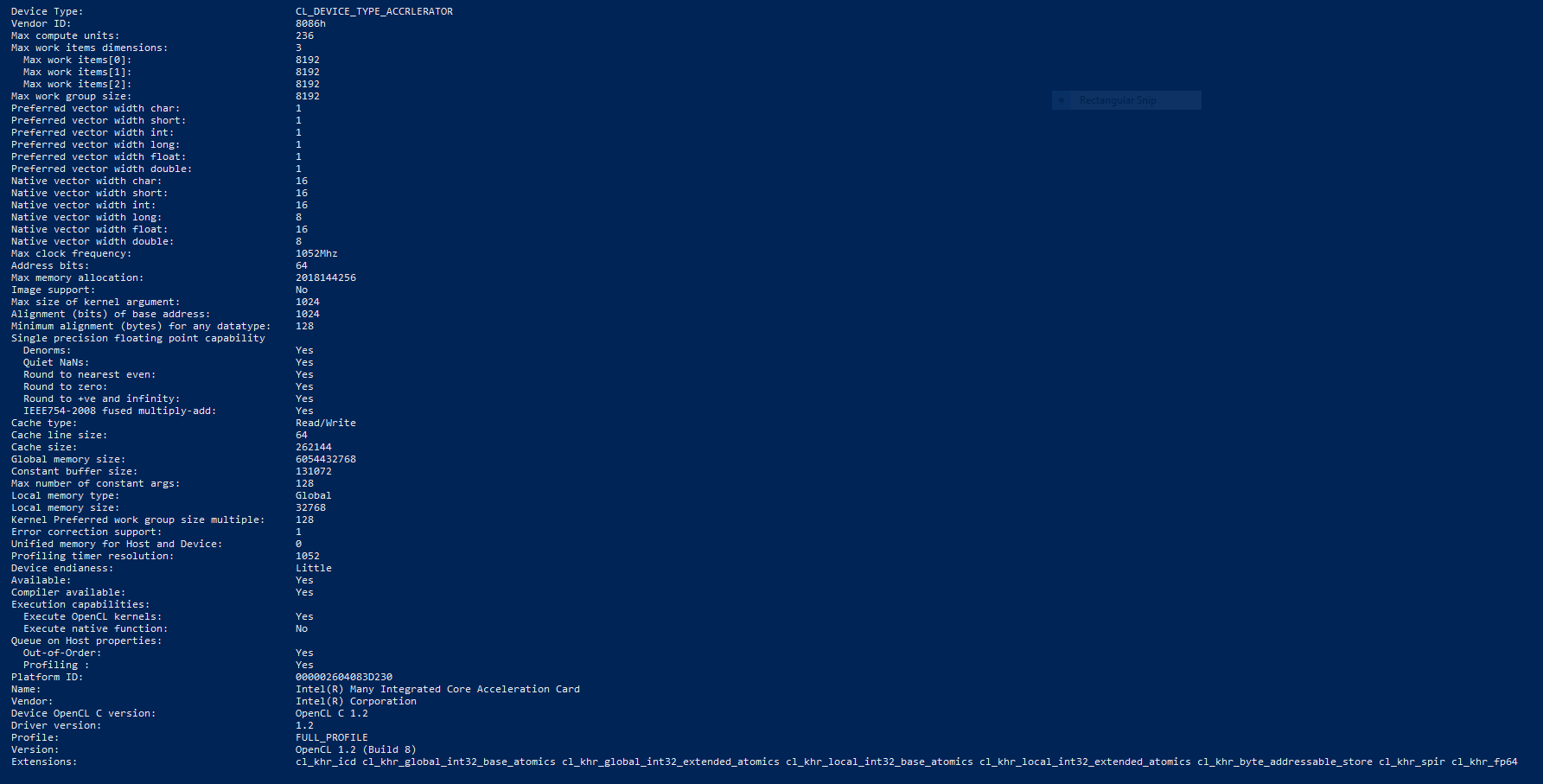
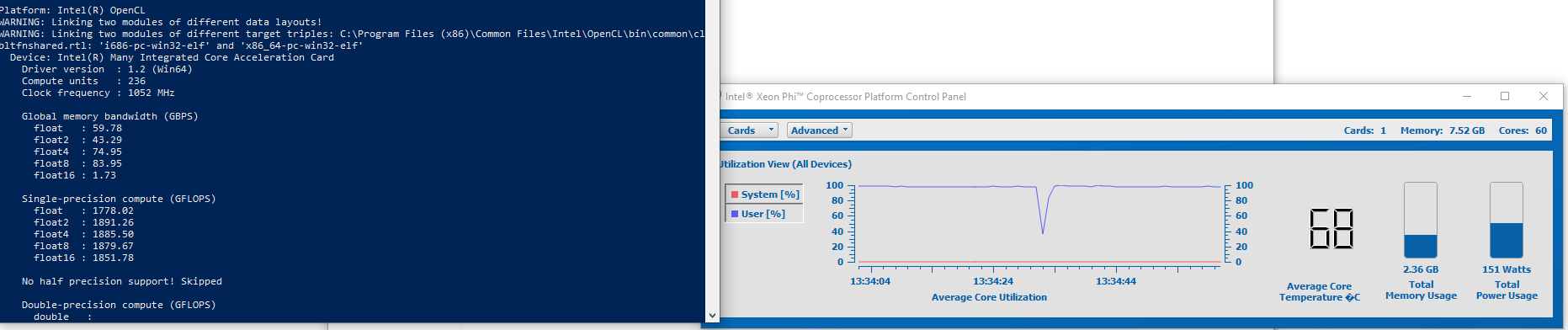
I wanted to run a quick simple OpenCL test
It is definetly not like programming for a desktop CPU
Nothing about this thing is straight forward in any sense
You can’t just install the OpenCL runtime
No you need to then compile it for your machine
Then to compile it you need to install 11GB of Parrallel studio and 8GB of Visual Studio 2012
Then you need to build a new bootable base cpio image for the card because the last released one is missing a bunch of any useful tools and API’s
Then boot the card with that and setup an NFS share with your libraries etc
Then you can run your code
To get it working on Windows I’m gonna have to load Intel Parallel Studio XE
Which is usually a pain to get and costs an stupid amount of money
No wonder people where hesitant to develop for Xeon Phi
Intel started shoving the 3110P into their faces at $195 + Parallel Studio XE included at some stage in hopes people would use them.
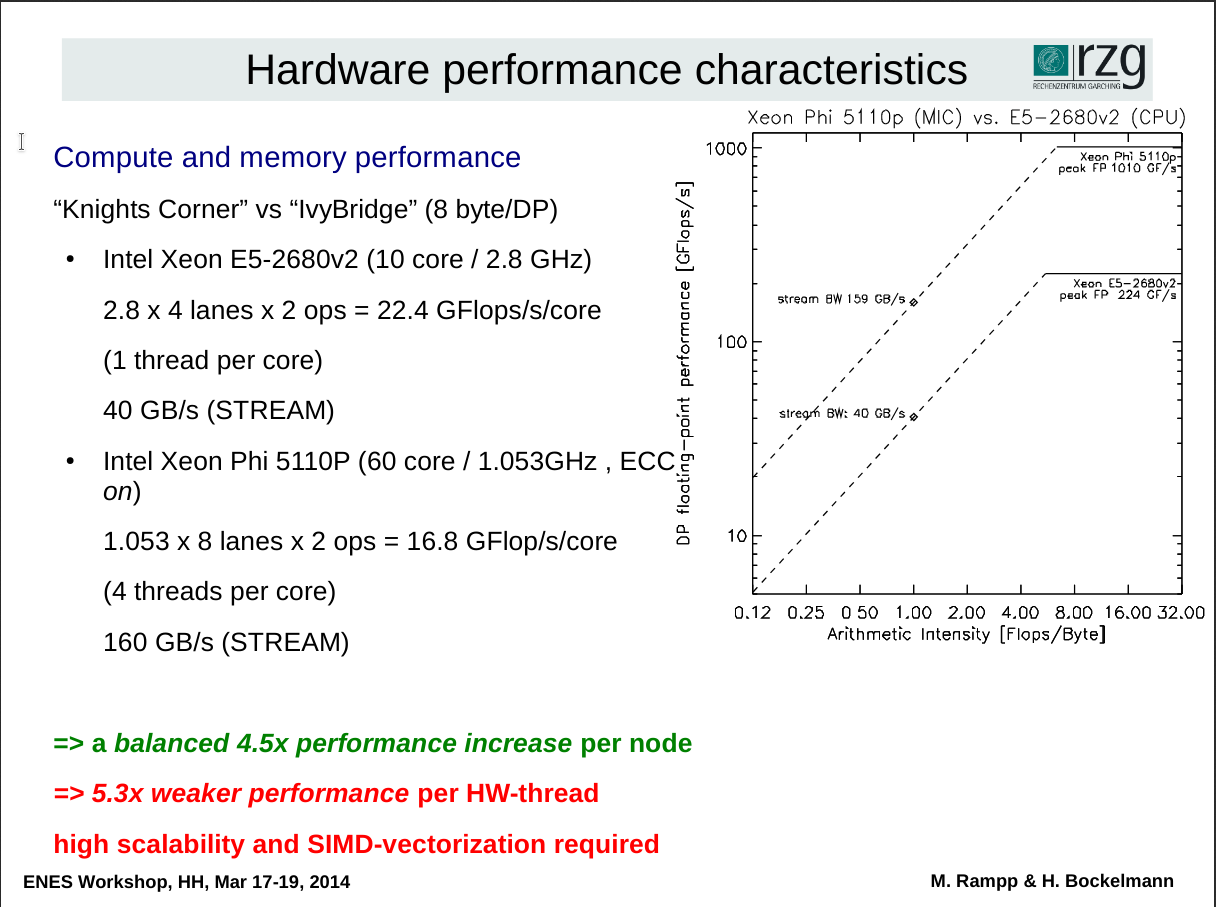
In moderately parallel applications traditional fat multicore CPU’s murder xeon Phi, (Especially Threadripper) in massively parallel applications GPGPUs rule. Xeon Phi is only barely competitive when you can perfectly parallelize AND vectorize your application.
Oof. I’m kind of disappointed. Was hoping something fun would come out of these Phi cards. Obviously not great, otherwise people would use them, but maybe something fun.
Looks like it is hard to even get them up and running, at least on Linux.
Looks like Intel had the same issue with Phi that Sony, Toshiba, and IBM had with Cell BE. It is unfortunate, how ever Cell BE seems to still have some good use cases (even though they are diminishing to niches) compared to Phi.
You’re doing the Lord’s work here sir! I’ve been interested in these Intel coprocessors for years now. I’m really surprised to hear that the software support for them is so unstable.
HPC labs that shelled out the big bucks for these must have had some Intel software engineers on hotline when the scientists were trying to deploy code onto these things. I can picture the conversations now, “We paid you a small fortune for all of these, now get our simulations to f*cking work!”
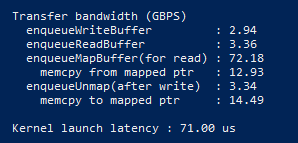
First test run you can see it chugging the power. Getting any sort of memory bandwidth out of it with OpenCL kernels is honestly tough. It fights you every step.
Not a Phi-natic but still interested in how this all comes together. Have you found modern hardware to out perform this or are there still use cases where this setup would be viable in 2023?
I remember reading about Knight’s Corner (or Landing?) many years ago back on the OMPF forum. One of the devs was boasting about “1 billion rays per second” on a test scene rendered with one of these cards.
If it’s not too much trouble, could you try to get a ray/path-tracing benchmark to running? Maybe something like LuxMark.
I’m quite curious to see how they compare to desktop Ryzen or Threadripper CPUs that we have now.
Thanks for demystifying how this hardware works! I’ve enjoyed reading your posts on it.
I include LuxMark results in this post, and it is not favorable to Xeon Phi because it targets SSE2, and so is using only a fraction of Phi’s 512 bit wide vector units. Intel’s OpenCL driver produces even less favorable results.
Mitsuba 2 shows very good results, although it is a pain for artistic use. You also have to be using the Intel compiler, modify some make files, and so on.
Untrue, if used with properly vectorized software. Though examples are admittedly few and far between. Generally if you’re making use of Intel libraries like MKL or Embree, you’ll see good scaling.
That requirement is no different from a GPU, or for any HPC application. Spaghetti code is going to turn out poor performance numbers no matter where you run it; consumer x86 processors and applications are less sensitive in this regard.
Itanium’s performance was not convincing due to compiler shortcomings, and its technologies vanished once it failed to gain significant market share. In contrast:
AVX 512 is still included in Enterprise-grade processors and offers tangible benefits to software that takes advantage of its extensions.
The Knights Landing core-to-core “mesh” type interconnect formed the basis of Skylake and later Intel processors, supplanting the previous ring-bus interconnect.
The implementation of the MCDRAM on-chip memory caching scheme has been reused for the recently released Xeon Max series of processors.
Because Phi’s performance is convincing, and because technologies pioneered with Phi are still in active use, it is undebatably unlike Itanium in significant ways. Just like a GPU, “specialized hardware” is not synonymous with “bad hardware.”
I don’t do HPC yet, but I cannot agree with that statement. I have seen Itanium in the wild until about 2017. The same arguments were made. Don’t get me wrong, it was a cool experiement and a lot of lessons learned from Itanium went into future technologies. Compilers only benefited.
But thanks for the information. It is all really neat. I am doing a masters’ degree in computer vision, machine learning, and artificial intelligence. It would lile to get into research eventually, so HPC actually interests me.