With AMD EPYC processors scaling first to 64 and now to 96 cores, the novelty of Intel’s many interconnected core (MIC) architecture, better known as Xeon Phi, has faded since it was first released in socketed form in the year 2016.
The second generation of Xeon Phi, Knights Landing, was a product of its time: 64-72 “Airmont” Atom cores clocked at 1300-1700 MHz depending on the SKU, a mere 32-36 megabytes of L2 cache, and support for six channels of DDR4-2400 memory. Offsetting this somewhat is the inclusion of 16 gigabytes of 7200 MHz high-bandwidth on-chip MCDRAM, or GDDR5 memory, similar to a GPU. Moreover, the anaemic Atom cores are each supplemented by two AVX 512 FMA units, a feature retained on Intel server processors to this day. Performance in scalar, SSE, and even AVX code (referred to by Intel documents as “legacy” code) falls far short of even contemporary “Broadwell” mainstream Xeons.
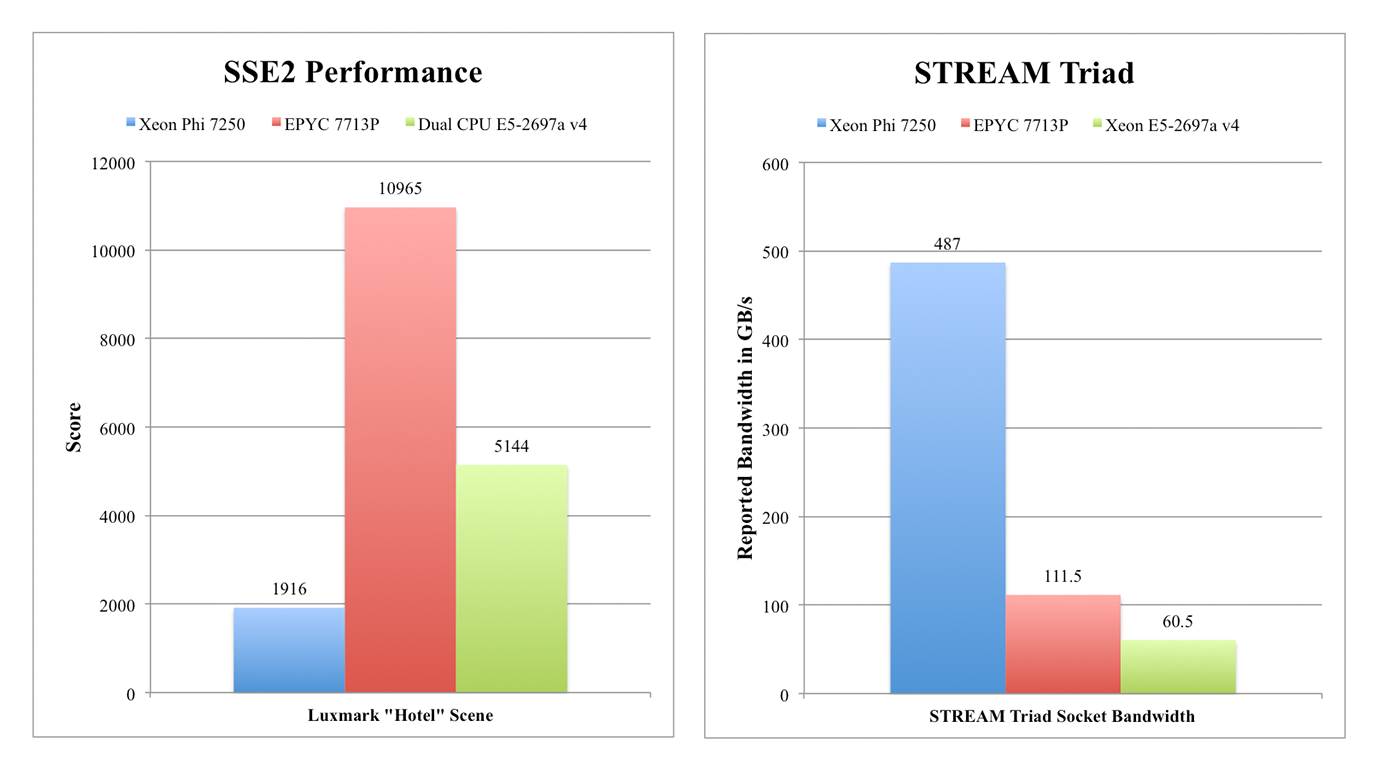
Xeon Phi is often referenced as one of Intel’s greatest hardware failures, up there with Itanium and the i840 chipset, but how bad is it really? And can I, as a consumer, make any use of it today?
To answer these questions, I compiled EPFL’s highly-parallel Mitsuba2 physically-based renderer with each vendor’s respective compiler tools (OneAPI C++ Compiler targeting -march=knl and AOCC targeting -march=znver3), and compared the results across a selection of my own 3D scenes using the path tracing integrator.
Path tracing models the flow of light by calculating the interaction of light paths with objects and materials within a scene. Mitsuba2 has the distinction of being one of the few easily-accessible path tracers with an AVX 512 code path, and it makes use of Intel’s Embree path tracing kernels, so the heavy lifting of Xeon Phi-specific code optimization has already been done through Intel’s “avx512knl” kernel. The AMD EPYC system makes use of the generic AVX 2 optimized kernel.
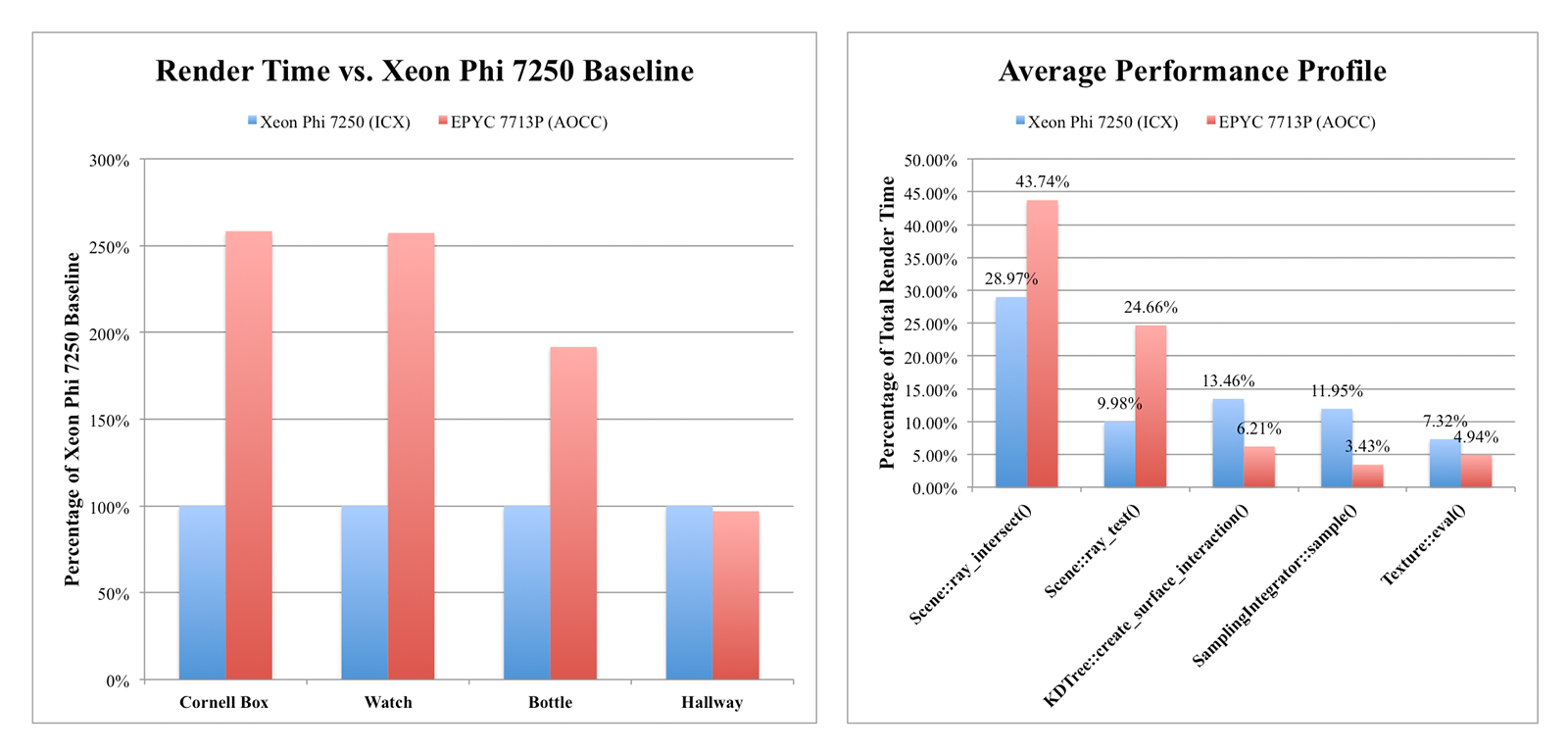
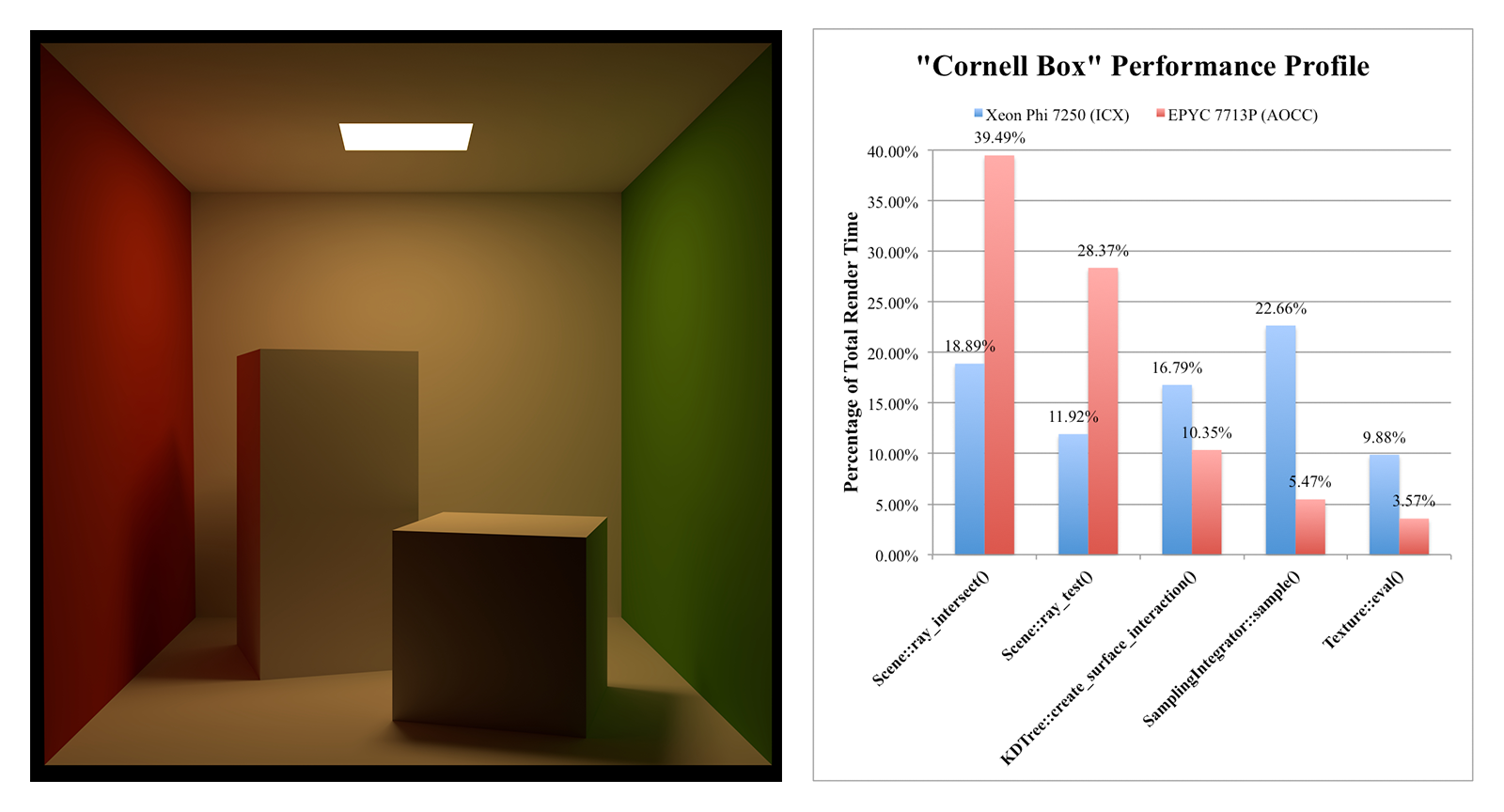
Performance in the first three scenes is impressive: Xeon Phi 7250 completes the render in less than half the time across these tests (average render time, 2.73 minutes) compared to EPYC 7713P (average render time, 6.72 minutes). The performance profiles for these scenes show that Xeon Phi is able to spend a significantly lower percentage of compute time in the Scene::ray_intersect() and Scene::ray_test() functions, presumably owing to the highly optimized Embree kernel and wide vector units. However, Xeon Phi spends much longer in the scalar SamplingIntegrator::sample() and Texture::eval() functions, which rely on the Atom cores.

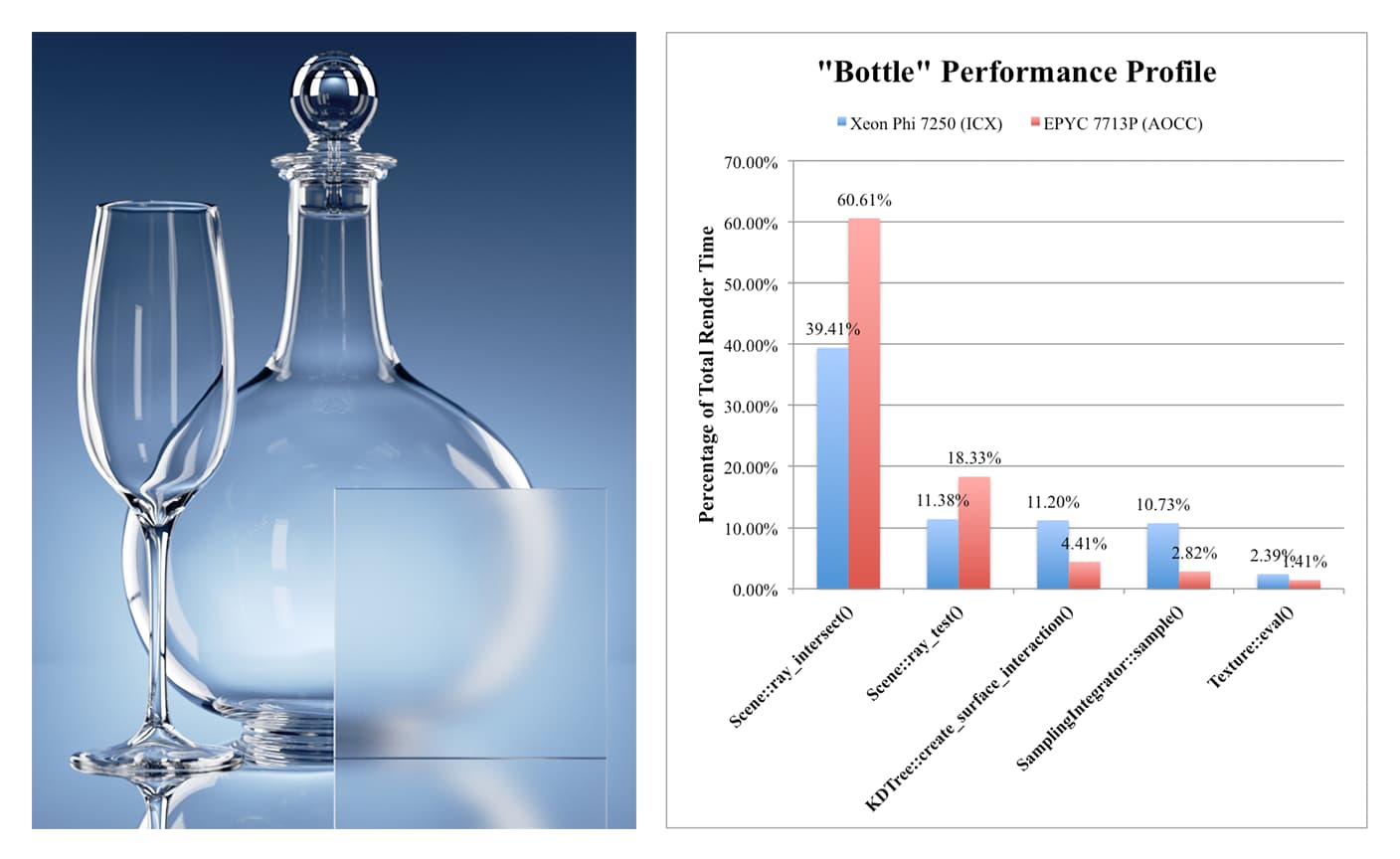
Finally, in the complex “Hallway” scene, which makes use of over seven gigabytes of high-resolution 4096x4096 bitmap textures (such as the wood floor) and complex shading effects, Xeon Phi becomes slower than EPYC 7713P, as a significantly larger amount of time is expended on the texture evaluation and sampling functions. The slow Atom cores become a limiting factor to overall throughput, and this trend becomes even more exaggerated in larger scenes with higher resolution textures and more complex shaders.
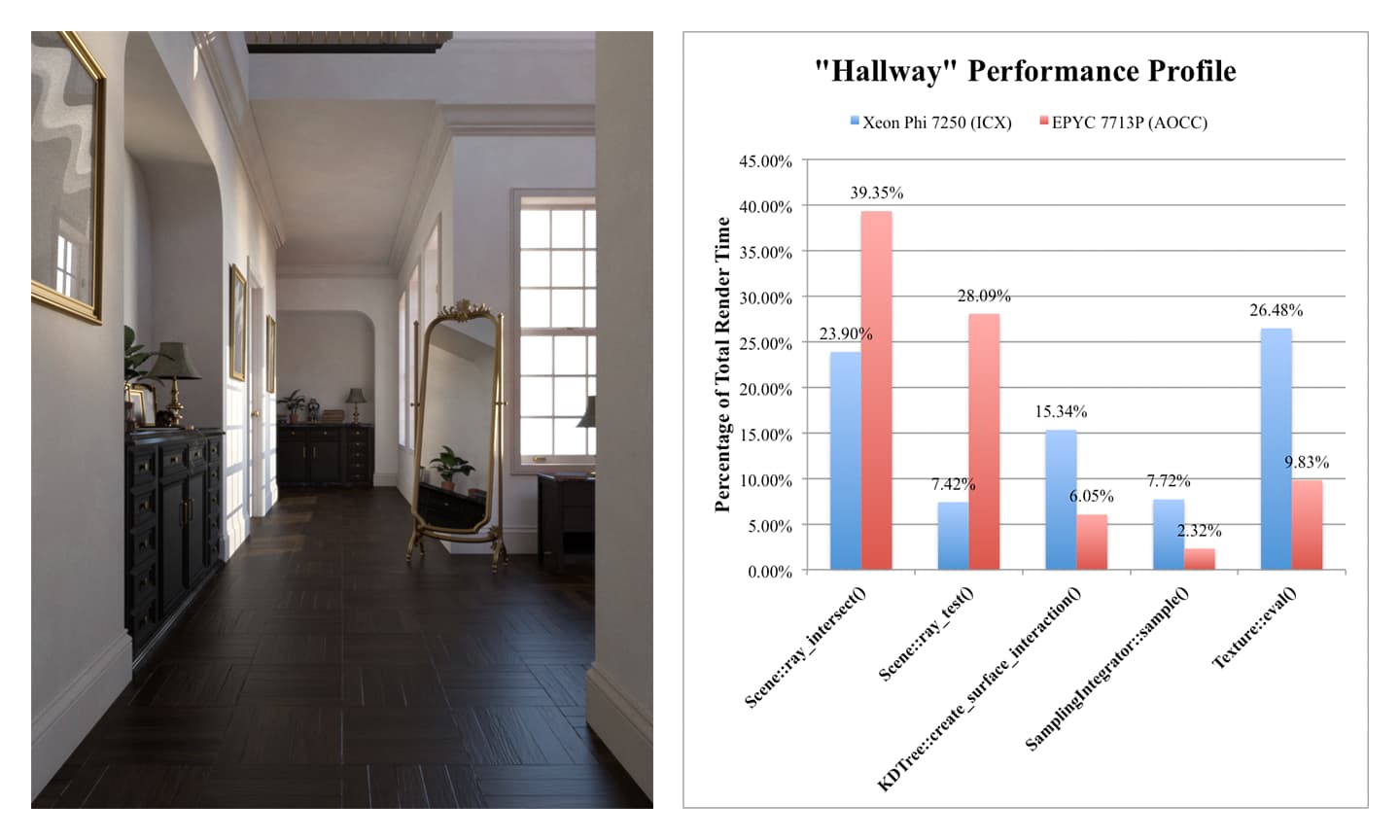
The conclusions? First, Atom cores running at 1.4 GHz are still really, really slow, to the point where they become a bottleneck if even a portion of the workload is not highly parallel and AVX 512 optimized. Second, as path tracing is sensitive to memory bandwidth and latency, large on-chip caching solutions as implemented in AMD’s 3D V-Cache approach and Intel’s recent Xeon Max line will probably benefit computer graphics workloads in the future. Third, wide(r) vector units absolutely have a place in CPU architectures for certain workloads.
Testing was conducted using the respective compilers under Debian 11 with the latest version of the Mitsuba2 rendering system, freely available here: GitHub - mitsuba-renderer/mitsuba2: Mitsuba 2: A Retargetable Forward and Inverse Renderer.
Mitsuba2 was compiled with the option -DMTS_ENABLE_EMBREE=TRUE to enable Embree acceleration, and the packet_spectral variant was used for all tests.

