Hey Guys,
I have recently started upgrading and migrating my current workstation. I am now running Arch on Zfs and so far I am loving it  .
.
So I want to add a storage pool with two 12TB hard drives in RAID 1 and a 1TB SSD. I would like to use the SSD to store data that is more frequently used. Basically tiered storage. I did some research I see two solutions:
- use 2 pools one for hard drives and one for the ssd and then use autotier.
or 2.
use zfs pool on hard drives and the SSD as L2ARC.
From this post it looks like zfs restores L2ARC on boot with would make 2. my preferred solution, because then the SSD may die without me having to restore data from backup. But I am A bit concerned about the RAM usage of L2ARC. I have 32GB in my system, which I don’t really use so maybe it is fine. A RAM upgrade would require me to update my platform which I will do in the future, but not now.
What do you guys think?
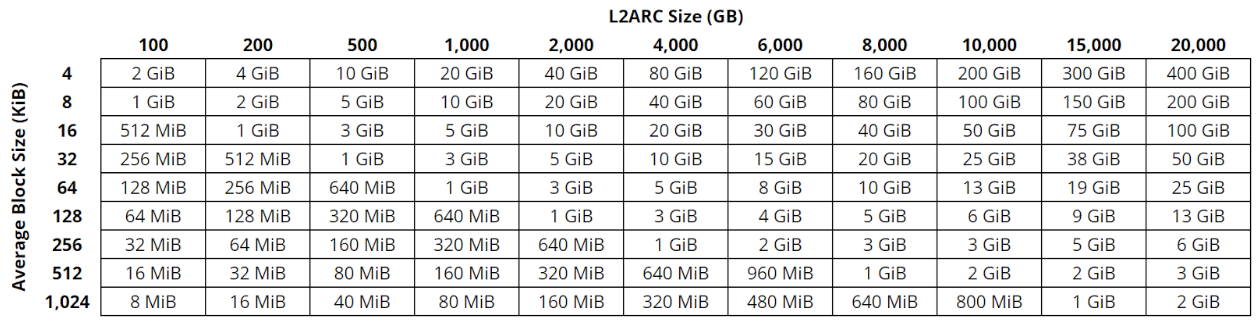
This is table to get a picture of how much memory the L2Headers inside the ARC will use. It is a fixed amount of bytes per record/block and thus scales linearly with recordsize/block size
As you can see…it’s fairly trivial for anything other than low blocksize (zvols).
2 Likes
Thank you, that table is really helpful. So basically I can just choose a blocksize to the level of RAM usage I am comfortable with.
That might mean giving up some space, but nothing really that would be hurtful to my requirements.
No, that’s not how you do things. You set the recordsize and blocksize for your datasets depending on what data is stored. Default is 128k and I wouldn’t tinker too much with it for a start. But VMs/databases/zvols generally want much lower recordsize while media files are fine with 256k or more.
With a default of 128k you end up with 640MiB according to the table which may vary in practice because of ZFS storing 16k files in a 16k record, not 128k. But I wouldn’t expect over a GB as “tax” for the L2ARC, which is fine because you traded 1GB of superfast cache for 1TB of still reasonably fast cache.
1 Like
Thanks for the clarification. For me it basically boils down to just media files. So I will probably be fine with the default.
I have my movies on a 1024k (1M) dataset and photos and smaller media stuff on 256k. Will not only reduce the amount of metadata, but also the L2ARC overhead in ARC.
It’s basically like packaging your car into 100 big containers instead of 10.000 smaller containers. Each container needs labeling and shipping informations. The less containers, the less overhead.
But you also don’t want to use large containers to send your mail, because this wastes space and you always need a truck to pickup your mail 
A rough and generalized analogy when talking about recordsizes.
2 Likes
I’ll keep it in mind. And play around a bit, that is what I use my workstation for mostly anyways. So thank you very much and have a great day