I have a little bit of performance problem with ZFS. I have a system with mixed hard drive and some spare NVMe (although just consumer grade and can be a red flag even though I will be running them in RAID1/mirror), but far as I remember:
ZIL Intent Log (otherwise known as SLOG) is not a cache; it is just a temporary buffer to store sync transaction logs (edit: thanks @Ghan for correction)
L2ARC, now that it was persistent, is an interesting one. However still, the working mechanism of L2ARC requires a long-term use to determine which ARC entries can be evicted to L2ARC (which is optimally Optane/NVMe/Flash storage).
So, in reality L2ARC really just worked more like a tiered read cache and does not have the capability of a traditional sense of writeback cache, which is the thing that I want.
And metadata device is just for storing filesystem information. Not really related to IO at all.
I’m going to evaluate using LVM on ZFS, more specifically ZVOL to see if the performance can be helped. There is an obvious problem though as both the functionalities of LVM and ZFS overlaps so much and I really hope ZFS to bake in something like bcache/dm-cache so much. If that’s so I can have speed up my iSCSI so much better like QNAP/Synology level with NVMe cache that I helped my company to speed up with.
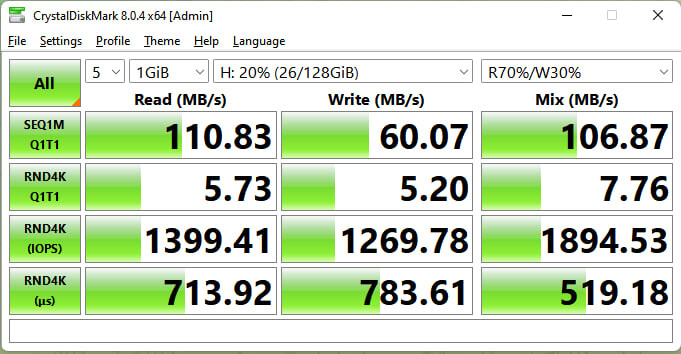
I have tried to setup a 10Gbe home network, directly connecting my 544+FLR, which is originally a 40gbe/50gbe card into a 10gbe connection using a passive DAC cable. It doesn’t work in the beginning well, but now after some tinkering, it worked like a charm! The speed up is phenomenal, and I will have to redesign some of my cable management to cater for the new 10gbe switch. Unfortunately, that 10gbe switch is of TP-Link brand with a rather value-oriented positioning, so I cannot setup LACP to get further speed up by multiplexing the connection. My ZFS setup is untouched after setting up the cards. Here’s a quick CB to show that it indeed had immediate improvement:
Here’s the original speed over 1Gbe:
Here’s the new speed using the setup I mentioned above:
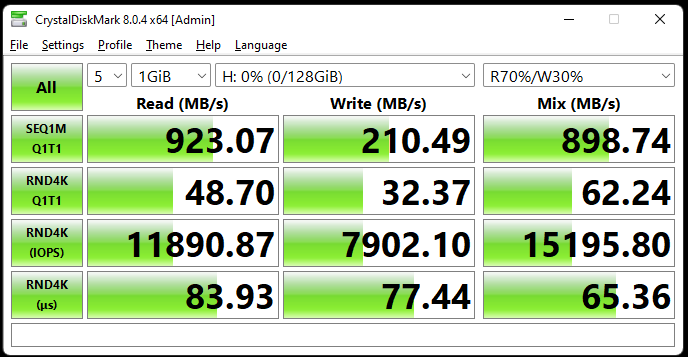
I will be trying to tune ZFS to get the NVMe “wire speed” as much as possible, though this will have many more factors such as SLC caching, memory throughput, TXG time, latency fluctuation… all sorts of stuffs need to taken into account for maximum performance. I don’t have time recently, but I will call this a small victory. The materials shown above is for reference and relative comparison only, and I will try to a more intensive benchmark and research over the coming weeks in free time.
The saga continues…