I’m currently running a finite element analysis software which uses a direct, sparse matrix solver on an AMD Ryzen 9 5950x (16 core, SMT disabled)
The solver is reporting that the memory bandwidth within the first chiplet is around 22.1 GB/s whilst the memory bandwidth going to the second chiplet is around 7.45 GB/s.
And then, because I am running this in a 2-node cluster (both nodes have said AMD Ryzen 9 5950X processor, also SMT disabled), over 100 Gbps Infiniband, the bandwidth that the solver is reporting is just shy of 6 GB/s (48 Gbps).
So, which raises the question - does anybody know what the theorectical bandwidth limit is supposed to be, chiplet-to-chiplet? I’m using DDR4-3200 CL22 RAM (4x 32 GB Crucial unbuffered, non-ECC).
I found the article from Anandtech which talks about it in terms of latency, but not in terms of bandwidth. (And their core-to-core latency chart – they also don’t have a version of that for bandwidth neither.)
(I’m not sure if there is a tool that would be able to help accurately measure that (and being able to compare the results against the theorectical limit(s)).)
You have several clocks that deal with it, all are tied to memory clock but can be unlocked and ran independently at a latency penalty
F-clock which is the infinity fabric speed, it’s what everything on the CPU communicates over, even die to die
U-clock is the memory controller clock, raising this lets you get higher memory clocks
L-clock is the l3 cache frequency
5000 Ryzen generally tops out at 3733-3800 ram assuming you’re running everything at a 1:1:1:1 ratio, memory clock being it’s actual mhz and not mt/s (half speed)
The first chiplet is always better binned so it will clock higher, tasks tend to go there more than they do the second, also it’s capable of doing more work sine it is faster which could be why it’s allocated more bandwidth
Here is the literal screenshot of the CPU frequency in MHz as reported by the command watch -n1 "cat /proc/cpuinfo | grep \"^[c]pu MHz\"".
Notice that you have to go to the second decimal place before you’d find a difference, thereby providing the data and the evidence that does not support the statement you made above.
That does not appear to be true in my case.
If your statement were true, then you should expect to see a discrepancy in the CPU clock speeds due to the turbo boost behaviour of the processor, but said discrepancy in CPU clock speed is wholly absent from the picture above.
Based on this statement, and doing the math, 7.45 GB/s divided by 22.1 GB/s = 0.3371.
According to your statement then, this means that the second chiplet is doing 33.71% of the amount of work compared to the first chiplet.
I don’t think that statement is remotely CLOSE to being correct because I can assure you, if the second chiplet was only doing 33.71% of the work of the first chiplet, you’d hear (A LOT) about it.
Something would have to be SERIOUSLY wrong and you would see that in multi-threaded benchmarks like Prime95 where threads 9-16 would be almost 1/3rd the speed of threads 1-8.
Sorry, but I call BS on that one, unless you can provide the data and the evidence to support said statement.
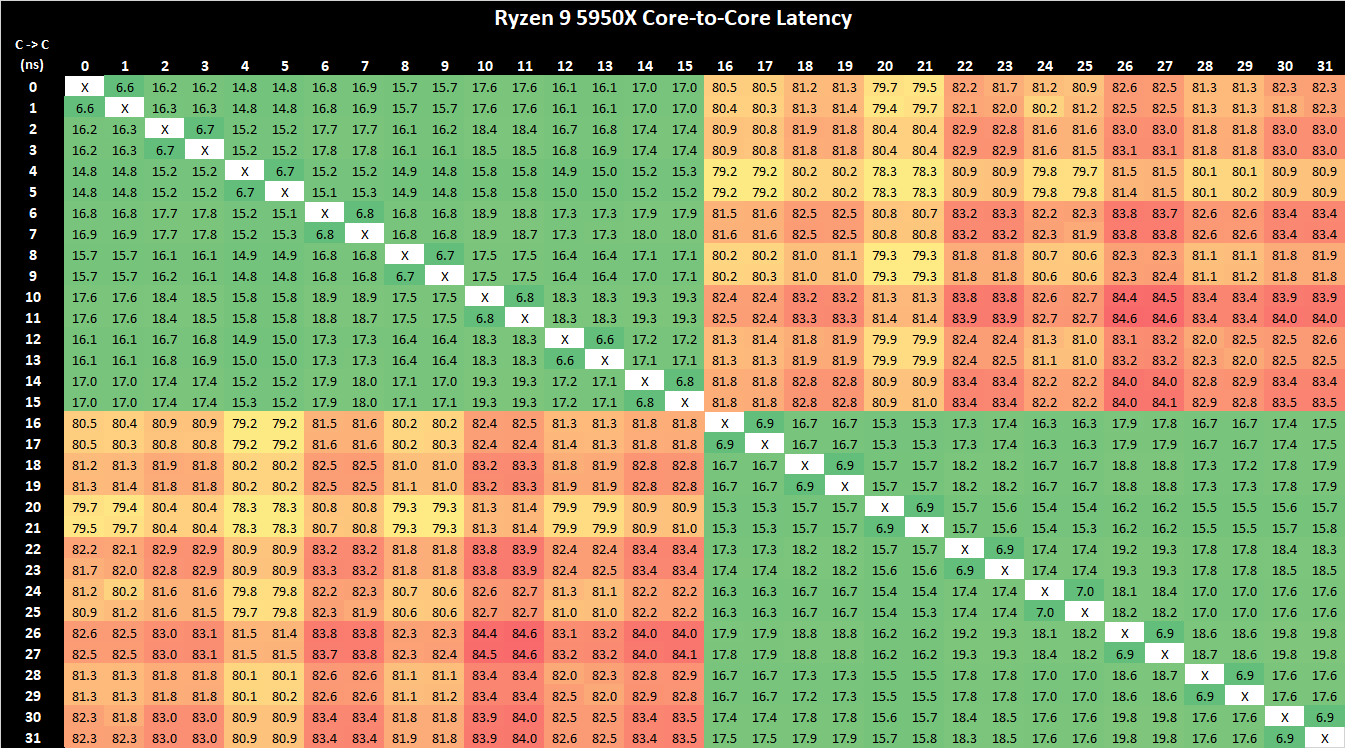
The 5950X core-to-core latency plot from Anandtech:
shows the increase in latency going from core 0 to core 16. (They have SMT enabled, so their plot shows the latency for each logical core pair.)
Even with that, the core0-to-core15 latency is 17.0 ns whilst the core0-core16 latency is 80.5 ns, which is 4.73529411 TIMES increase. Therefore; if it were based on the latencies alone, I should expect a 78.8882% REDUCTION in bandwidth vs. 66.2896% that’s actually realised (or at least as reported by the sparse matrix solver application).
(sidebar: even if I am using a preconditioned conjugate gradient iterative solver, the bandwidth reduction is about the same.)
With the centralised I/O die, I didn’t think that the communication between 100 Gbps to the memory controller would be CPU core dependent. The ironic think is that using Infiniband bandwidth benchmark, it shows that I am able to get 96.58 Gbps max out of the 100 Gbps line speed that 4x EDR IB is supposed to be capable of.
But in an actual, practical application, I’m only barely getting 50 Gbps and I’m trying to figure out if that’s because I need to set the processor affinity for the IB, or if it should be completely agnostic to the CPU core given that it should be communicating with the memory controller on the I/O die directly, and skips the CPU core altogether. (I mean, isn’t that kinda the whole point of RDMA?)
Alright so you are on linux and I am not sure which linux you are using and its ability to boost the cores or select which cores to put tasks on. There is a hierarchy on the system in terms of the best cores vs the worst cores. You have the best cores per chiplet / CCD and then the best cores per CCX (although CCX = CCD in Zen3 so it doesn’t matter).
Heavy tasks are put on the best cores first which reach the best boost clockspeeds. At an all core sustained load; most of the cores just hit the same speed. The higher bursts of speed are on the better cores because all core loads are limited by thermals or power.
Both chiplets should have the same latency and bandwidth. In my years of using these systems, I never noticed a slowdown in my 3900x or now my 3960x in terms of bandwidth to either chiplet. The I/O die connects to each chip directly with the same interconnect.
Each core has lower latency to the core “next to” it just in how the architecture is built (Zen3). The architecture uses what is basically like mini ring busses in between the cores. The Latency for Core 0 to Core 16 is because Core 16 is a virtual SMT Core. 0-15 = 16 physical cores.
I would say that AIDA64 has some tests to show cache latency & bandwidth. I am not sure about Core to Core Bandwidth though. So unfortunately I cannot answer your question. I can run some tests on my Zen2 3960x but it won’t answer your specific question.
Depends on your workload, power limits and temperature, if you’re riding your power limit with a heavy load you won’t see a difference
I also don’t have much faith in any given Linux distro to turbo properly as their drivers play second fiddle to windows in terms of attention and development
Each CCD has a favorite core and each Ryzen 9 will have a favorite die, you can confirm this with Ryzen master software
Many overclocked who have extensive experience will tell you the same thing such as buildzoid or der8uar
The theorectical peak memory bandwidth is OS independent.
(much like how the theorectical peak bandwidth of the Infinity Fabric and/or the PCIe bus (within any given generation) has a theorectical peak bandwidth that you can calculate by width of interface (in bits) * bus frequency = theorectical peak bandwidth)
The question here isn’t whether I can hit that.
The question is how to compute said theorectical peak bandwidth.
(From what I can find on wikichip, it says that the memory controller which resides on the I/O die, says that it is a 128-bit interface, but it’s apparently supposed to be capable of 47.68 GiB/s.)
But that doesn’t necessarily tell me what the core-to-I/O die can do, so I wasn’t sure if someone else knows where I would be able to find that information.
That’s not true.
" The Ryzen 9 5950X: 16 Cores at $799
…
This processor is enabled through two eight core chiplets (more on chiplets below), each with 32 MB of L3 cache (total 64 MB)"
Yeah, I’m trying to take software out of the equation by calculating the theorectical peak bandwidth.
It doesn’t look like that anybody has this information in terms of the core-to-I/O die bandwidth because I am trying to figure out if part of the reason why the 100 Gbps Infiniband is runinng only at about HALF its theorectical, peak bandwidth/speed is because of the added latency going from core-to-I/O-die-to-core again (vs. Intel’s more monolithic core architecture).
Sadly though, Intel doesn’t have a commerically available 16-(performance) core part available for a direct comparison against hte 5950X for computationally intensive workloads.
(I had a 12900K for a while. It ended up with a severe, catastrophic data corruption issue where I think that the memory controller had a fault on the CPU because it failed to run memtest86 for more than 30 seconds before the system would shutdown and/or reset itself. So I wasn’t able to test just the 8P cores vs. 16 cores doing the same computationally intensive task because the CPU died before I got around to starting those tests. But I digress…)
Uhhh…yes and no.
The min CPU frequency is wrong in the 5.14.15 kernel for the 5950X. (My 5950X drops down to 2.2 GHz instead of 3.4 GHz, but honestly, I kinda don’t really care about what the idle speed is, because since the CPU isn’t doing anything, it doesn’t really matter. The turbo boost clock speed appears to be correct though at ~4.5 GHz all core turbo.)
Yeah, I think HWiNFO 64 also shows this as well in the sensors tool.
But being that I am currently running Linux (again, the theorectical peak bandwidth is OS agnostic), I don’t think those tools are available in Linux, but I can be wrong.
I know, but again, not the point of my post/this question re: theorectical peak bandwidth.
If the core-to-I/Odie-to-core is the reason why there is a reduction in the theorectical peak bandwidth, then it would help to explain why my 100 Gbps Infiniband is only operating at about 50% of its theorectical peak bandwidth/capacity.
But if that ISN’T the case, then I am even more puzzled as to why my 100 Gbps Infiniband is running at half the speed if the core-to-I/Odie-to-core is capable of being a LOT faster than that.
What? Cores 0-15 are the physical cores. Core 16-31 are virtual. The post you shared doesn’t prove or disprove that. People are trying to find out what cores are reported as what in linux. Different people have different results. This may be due to motherboard firmware, linux kernel version or other reasons. Maybe some effort to make linux assign threads better like how cores appear to windows with the proper drivers installed.
I understand this as well. I was just trying to recommend something that you might be able to use to help you on your journey since it doesn’t seem like this information is anywhere. IT MAY be an AMD trade secret, who knows.
HWINFO64 does show this. I am not sure how to see it on linux at this moment. In my tests with my servers; I haven’t found a way to reliably report it. I have a 7402P server and there is no core data.
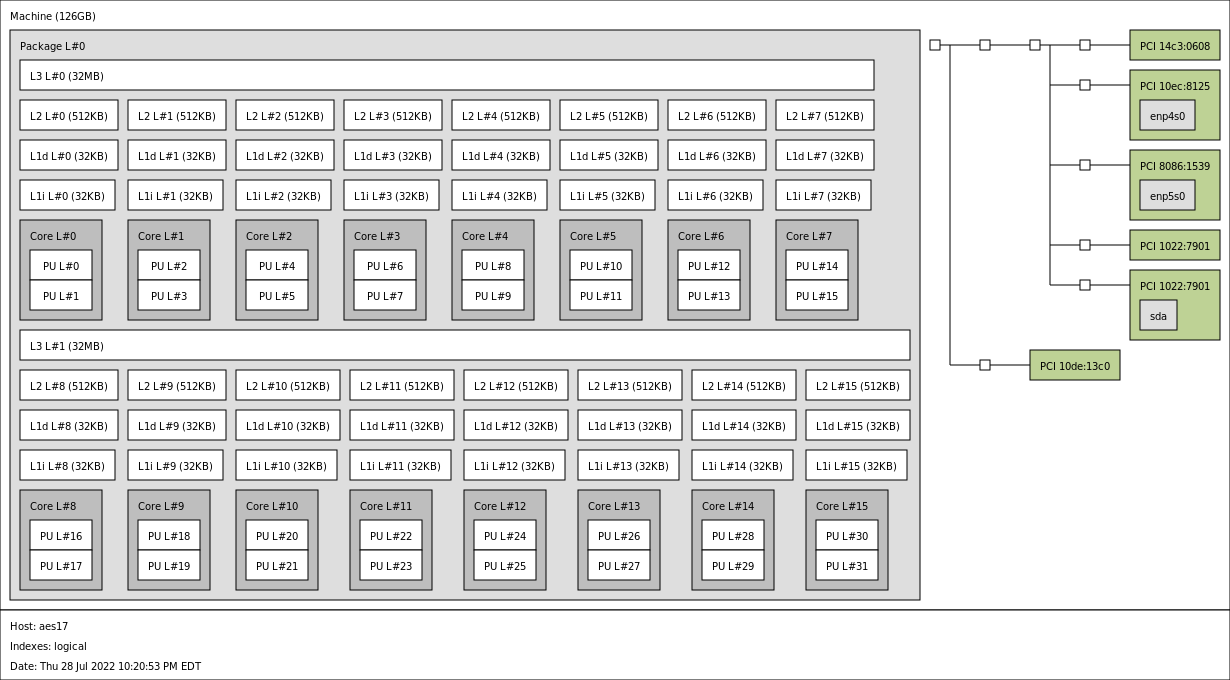
Below shows the output of lstopo -l with the output written to a png file for my 5950X (I re-enabled SMT for this picture, and then turned SMT back off afterwards):
" Should I use logical or physical/OS indexes? and how?
One of the original reasons why hwloc was created is that physical/OS indexes ( obj->os_index ) are often crazy and unpredictable: logical processors numbers are usually non-contiguous (processors 0 and 1 are not physically close), they vary from one machine to another, and may even change after a BIOS or system update. This numbers make task placement hardly portable. Moreover some objects have no physical/OS numbers (caches), and some objects have non-unique numbers (core numbers are only unique within a socket). Physical/OS indexes are only guaranteed to exist and be unique for PU and NUMA nodes.
hwloc therefore introduces logical indexes ( obj->logical_index ) which are portable, contiguous and logically ordered (based on the resource organization in the locality tree). In general, one should only use logical indexes and just let hwloc do the internal conversion when really needed (when talking to the OS and hardware).
hwloc developers recommends that users do not use physical/OS indexes unless they really know what they are doing. The main reason for still using physical/OS indexes is when interacting with non-hwloc tools such as numactl or taskset, or when reading hardware information from raw sources such as /proc/cpuinfo."
(sidebar: In the link that I have provided above, it shows the arbitrarily assigned physical index as well as the sequential logical index in the same plot. As such, you can see that the logical index (which is the index that apparently the OpenMPI group advises users (and developers) to use, because you can actually get a consistent representation of the CPU topology rather than using the arbitrarily assigned physical index.)
Also cf. this example from the linux man pages:
For example, if the first few lines of lstopo -p output are the following:
Machine (47GB) NUMANode P#0 (24GB) + Socket P#0 + L3 (12MB) L2 (256KB) + L1 (32KB) + Core P#0 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#1 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#2 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#8 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#9 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#10 + PU P#0 NUMANode P#1 (24GB) + Socket P#1 + L3 (12MB) L2 (256KB) + L1 (32KB) + Core P#0 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#1 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#2 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#8 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#9 + PU P#0 L2 (256KB) + L1 (32KB) + Core P#10 + PU P#0
In this example, the first core on the second socket is logically number 6 (i.e., logically the 7th core, starting from 0). Its physical index is 0, but note that another core *also* has a physical index of 0. Hence, physical indexes may only be relevant within the scope of their parent (or set of ancestors). In this example, to uniquely identify logical core 6 with physical indexes, you must specify (at a minimum) both a socket and a core: socket 1, core 0.
Your statement/assertion above is true if you use the physical index. But as it is also shown, if you have a dual socket system, you can end up with TWO P# 0s, as shown in the example from the linux man pages above.
Are you using Windows or Linux? It sounds like that you are running Windows, but I am not sure if that’s the case or not.
edit
Going back to what you said here:
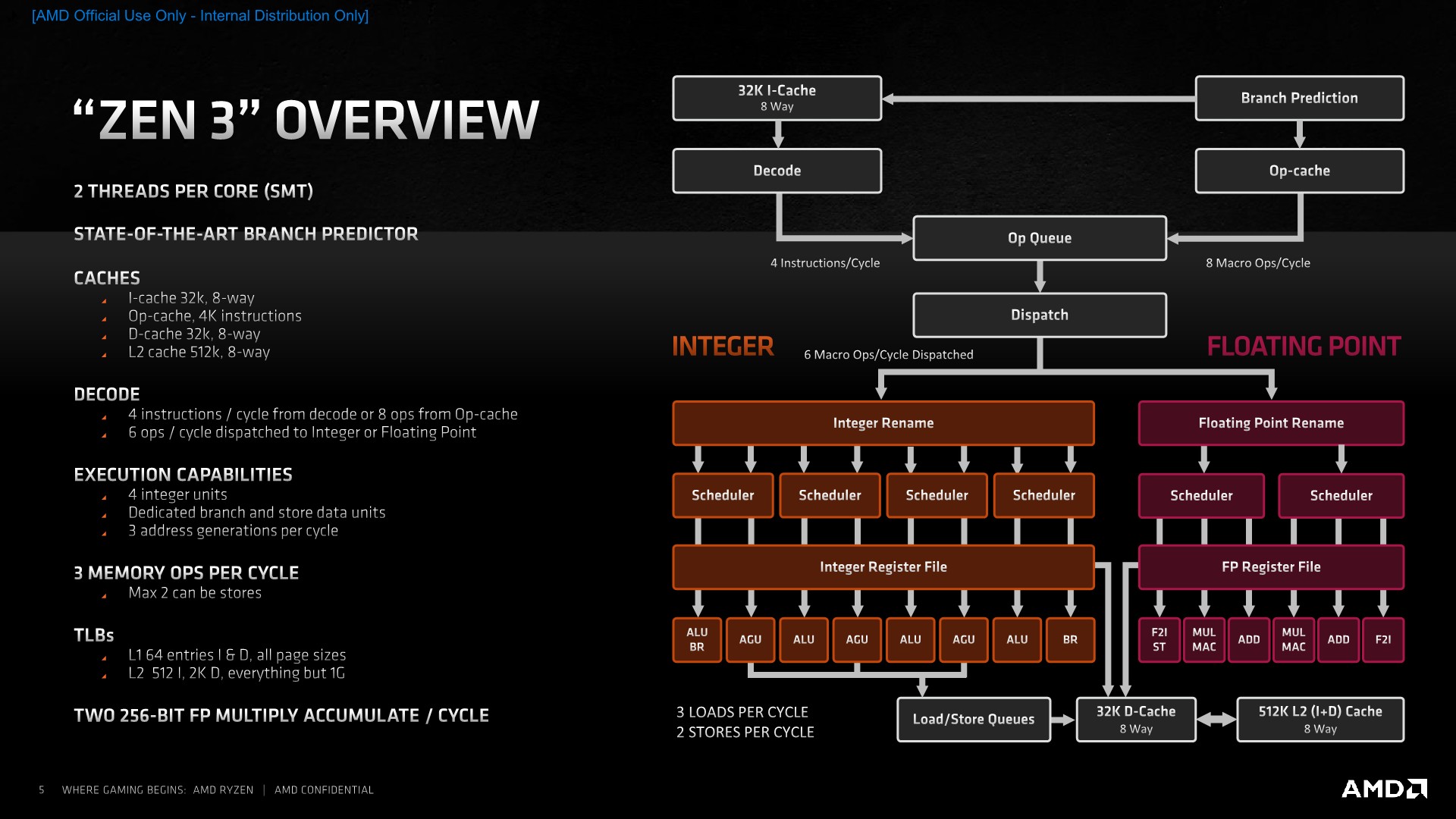
AMD’s own Ryzen 5000-series presentation shows the two CCD/CCX design:
where each CCD/CCX is a unified 8-core/16 thread chiplet.
Therefore; given the logical arrangement of the cores and threads, and going back to the core-to-core latency plot from Anandtech, it makes no sense why the physical core-to-core latencies (based on your explanation) would be VASTLY better than the logical core latencies.
That doesn’t make any sense.
Suppose that core0-core7 is on the CCX0 and core8-core15 is on CCX1.
According to your statement, there is literally no difference in terms of latency, going from core0 to core15 per Anandtech’s latency plot.
But if each of the CPU cores is really a SMT core (cf. https://images.anandtech.com/doci/16214/Zen3_arch_5.jpg) , then why would going from thread0 of core0 to thread1 of core0 incur such a massive latency penalty of 4.735x?
“On the new Zen3-based Ryzen 9 5950X, what immediately is obvious is that instead of four low-latency CPU clusters, there are now only two of them. This corresponds to AMD’s switch from four CCX’s for their 16-core predecessor, to only two such units on the new part, with the new CCX basically being the whole CCD this time around.”
(I’m trying to figure out in what way would your statement be true.)
Why could going to the second CCD/CCX (i.e. CCD1/CCX1) be faster than staying on the same CCD0/CCX0 for the second thread? Why would the virtual SMT core, which literally sits next to or on the same core incur a 4.735x latency penalty?
That doesn’t make any sense to me.
I think about it this way:
you have two arms. Each arm can do something. (an arm = a thread)
You have 16 people, standing on two rows of 8.
Your statement basically says that all of the right-arm-to-right-arm communications is faster between the first person to the eighth person (core0-core15 latency of 17.0 ns) than your right-arm talking to your own left-arm communication, which incurs a 4.735x latency penalty, and so, your right arm talking to your left arm has a 80.5 ns latency (core0-to-core16).
I don’t understand how that can be possible.
Conversely, if you look at the overhead view of the two rows of people and the one group of eight people is facing the second group of 8 people and vice versa – the right-most person in the first row, talking to the left-most person in the second row, I would think, should incur the latency penalty, if for no other reason, this pair is the furtherest from each other.
(Like I said, I’m trying to think of how your statement is true, and I am completely and utterly failing at this task.)
So I think of it as being my right arm vs. my left arm.
I am really struggling to see how the statement that your right arm (core0) talking to your left arm (core16) would incur a 4.735x communication/latency penalty if each core is 2 threads per core per AMD’s own Zen3 overview slide.
I believe the answer you seek is in the block diagram. Multiply bytes/cycle by number of cycles, that’s your per-second bandwidth, no? So, IF=1900MHz would be 60.8GB/s read and 30.4GB/s write between IOD and CCDs? Math is not my strongest feature so forgive me if that doesn’t add up.
asking because this may sound like an interesting GPU workload/TPU workload and a potentially good use case for some nice HBM (expensive and flaky but fast)
I’m using DDR4-3200, so that should put the Infinity Fabric clock speed at 1600 MHz, which would make it 51.2 GB/s read and 25.6 GB/s write.
That might make sense for cores0-7, but for cores8-15, where it’s only getting abour 7.45 GB/s (out of 25.6 GB/s write), it would suggest that it’s getting hit (with latency) elsewhere.
If the die-to-die IF on the CCD is only capable of 16 B/cycle writes, that means that every other read cycle would be empty (in theory), unless it’s pulling data from RAM.
Hmmm…I wonder why they did it that way.
Between the two nodes in my cluster that’s running the job right now, combined it’s about 52 GB for this relatively small case.
I’ve never tried running multiple GPUs in parallel over Infiniband, so that would be interesting to try if I had said multiple GPUs to test it out with.
The problem that I would run into on the Ryzen platform is that the platform itself wants the GPU in the primary PCIe slot, which for the GPU, is fine, but what it means for the 100 Gbps Infiniband card (PCIe 3.0 x16) is that it would be running in the PCIe 4.0 x4 slot, and since the card isn’t a PCIe 4.0 card, that means that it would be running at PCIe 3.0 x4, which means it would be running at a maximum of 25 Gbps (theorectical peak).
So, distributing the problem across multiple GPUs over 25 Gbps IB would make the GPUs really, really slow.
Which means that if I want to remove this barrier, I would need to move up to at LEAST the Threadripper platform, which, I think one Threadripper CPU costs about the same as an entire Ryzen node in the cluster (and then there’s the cost of the GPUs itself). And the official guidance from the ISV is that there should be 8 CPU cores per 1 GPU. Beyond that, the GPU would be starved by the CPU for data, which reduces the utilisation and computationally efficiency if you try to add more GPUs than that ratio.
And then if I want to have GPUs that can actually handle that much data, now I am looking at roughly in the $10,000 USD/GPU range, which is about the same price as five complete Ryzen nodes.
Bottom line: running the solution on a “big enough” GPU is not really cost-effective at this point.
As it stands right now, with two Ryzen nodes in the cluster, the fastest solution (CPU only) is done in about 89 seconds. So…any reduction in time would be marginal at this point.
My servers use linux, mostly Ubuntu these days.
I see your layout, but it isn’t necessarily the same as what Anandtech found. Typically virtual cores have a higher latency, because they are virtual. This is why they don’t scale linearly. Meaning that a 6 core w/o SMT vs a 6 core w/ SMT doesn’t = 100% more performance… more like 1.3-1.5x depending on the workload. Why? Because all virtual cores do is use up EXTRA resources on the core to process simultaneously or pre-load information for the execution ports to immediately process making it a flip/flop process. This is also why IPC goes up with SMT off. Since there is no flip flop or logical core management.
So the latency from core 1 Phy to Core 1 Virt can be much higher because you are putting information in there for the thread manager to process specifically. You also don’t know what operations they used to determine this… all of these things could result in different outcomes.
Overall it is really hard to say, technically the latency from Core 1 to Core 16 should be a bit higher since it has to go through the infinity fabric. However it also wouldn’t make sense that Core’s 8-16 all have high latency just being on the second CCD/CCX because that isn’t how the platform works.
You don’t have one “main CCX/CCD” and then a “second” CCX/CCD that is just doing backup work…
The thing about the ryzen desktop platform is that no matter how you look at it; there isn’t enough PCI-E bandwidth. There are some boards that have dual PCI-E x16 slots where both can run at x8… However if the card is PCI-E 3.0 x16 you have an issue there since Ryzen cannot take 16 PCI 3.0 lanes from 8x 4.0 lanes. Meaning you cannot run the GPU in x8 PCI-E 4.0 and then the GPU in x16 PCI-E 3.0 even if there is enough bandwidth. That type of stuff is handled by the chipset which would incur a greater latency penalty.
I am pretty sure you would face the same issues on Intel as well, unless Alderlake specifically has some new ways of handling PCI-E that would let it do x8 PCI-E 4.0 and x16 PCI-E 3.0 at the same time without latency penalty.
So…the runs that finish that quickly, the total volume of data is just over 500 MiB, so it’s not too bad. It will likely take more time for me to transfer the data back and forth to/from the cloud vs. running it locally. (That plus COTS cloud systems that AREN’T designed for this HPC workload - the fastest system interconnect that I’ve found (as a COTS hardware-as-a-service) is 40 GbE. (And those instances aren’t cheap neither.)
For my longer runs (I’ve got two going right now that are expected to take about 2 days, so I’ve got my 5950X nodes working on it as well as two of my own Xeon nodes working on the second job simultaneously as well) – those jobs typically will generate about 375 GiB of data and the inter-node volume of communications traffic would be in the tens, if not hundreds of terabytes (usually) (or at least that’s how much data would pass through the scratch disk).
Unfortunately, that’s under NDA.
Sadly, no.
(I don’t think that there’d be a way for me to get a 100 Gbps Infiniband connection on those systems anyways.)
The text of Anandtech’s article tells you that.
I will never truly understand why people would just ignore the data that doesn’t fit their mental model/pre-determined worldview, rather than updating their mental model/worldview when new data comes in.
[citation needed]
I agree with you re: depending on the workload.
I disagree with what or how you arrived at that conclusion.
If you have a competition of resources, you’re going to slow down. Thread context switching, like moving data around, isn’t actual computational work that’s being performed.
Unfortunately, the data DOES need to be moved around in order for the CPU to be able to act and work on said data, so moving data around is a necessary evil.
In computationally intensive applications (i.e. FPU heavy workloads), SMT/HTT will usually result in about a 7% performance hit (on average) because the two threads are competing for the same FPU on-die resources. (I used to do a LOT of testing with HTT on vs. OFF to see what the impact was going to be. Now, it’s known to have an adverse performance impact that the software vendor/ISV actually WILL NOT allow their software to run if the number of CPU cores requested is > than the number of physical CPU cores available. It will actually spontaneously abort the run and kick itself out of it, and throw that error, informing you that that’s what it did/that’s what happened.)
For my HPC workloads, it’s about a 7% hit on average (on older versions of the software before they put that lock into their code).
I wouldn’t necessarily characterise it as an “extra” resource, but rather, just using what you’ve got, more often (higher level of utilisation by shoving another thread into the pipe). (The first page from this Anandtech article which cites a really old Intel slide re: HTT, visually shows how HTT/SMT works: Investigating Performance of Multi-Threading on Zen 3 and AMD Ryzen 5000)
I would disagree with how you arrived at this conclusion.
You can test it out for yourself where if you have an idle system and you run a single-process application on a physical core and then you run the same single-process application on a logical (read: “virtual”) core, and you compare the execution time result – you know what…I won’t spoil the ending for you. I’ll wait for you to report your results back.
(Like I said, I’ve done a LOT of internal testing in regards to this.)
Again, [citation needed].
(Please cite your sources of where you are getting this information from.)
If what you are saying is true, then it ought to be physically and logically IMPOSSIBLE for the 5950X to get a 25.1% benefit with SMT on, given your proposed increased latency.
You are telling me that things should be slower because of quote “So the latency from core 1 Phy to Core 1 Virt can be much higher because you are putting information in there for the thread manager to process specifically.” and yet, the data clearly shows a BENEFIT ranging from 25.1% for Blender, 45.5% for Corona, 15.4% for POV-Ray, and 26.0% for V-Ray.
How does THAT work?
You’re telling me that the increase in latency should slow things DOWN. But the OPPOSITE is the result - it actually got FASTER.
That would be like having another football player clinging onto a linebacker as he’s running down the field, trying to score a touchdown and you’re telling me that by adding said other football player, who’s clinging onto the linebacker (added latency) would produce a result that is FASTER than if the same linebacker, running for a touchdown, would be WITHOUT said added latency (i.e. the other football player clinging onto said linebacker)???
How does THAT work?
(That’s NOT passing even the “sniff test”. Something’s definitely “off” with your statements here. The results CAN show that SMT helps to make applications/workloads run faster. But your statement is telling me that the increase in latency should actually be SLOWER. And as the latency plot from Anandtech shows, it’s the latency is not just a LITTLE bit slower. It’s 4.735 TIMES slower. (17.0 ns vs. 80.5 ns).
How do you get a 25.1% performance UPLIFT in Blender with SMT on when the latency has increased by 4.735 TIMES??? That doesn’t make ANY sense whatsoever.
Think about what it is that you’re actually saying.
Does that make sense to you?
Let’s say that speed = distance / time. Let’s say that you travelled 100 km/17 hours = 5.882 km/h.
And let’s say in scenario B, that you travelled 100 km in 80.5 hours = 1.2422 km/h.
In what universe would increasing the time it takes to do something, produce a FASTER result than if you DIDN’T have said time increase to complete that task???
That makes no sense to me whatsoever.
[citation needed]
Why? Why would it?
Here is the latency plot for Intel’s Core i9-11900K:
Notice that the maximum latency never exceeds 30.7 ns, which is less than HALF of the latency of going to the second CCX/CCD on the 5950X (at 80.5 ns).
We KNOW that Intel has a monolithic die design, and therefore; as such, the intercore communication is faster than if you have to leave your core to go to another core to fetch data. (We know this from even Intel’s own multi-socket computing platforms like my Supermicro 6027TR-HTRF which has dual Socket 2011 for dual Xeon E5-2000-series CPUs.)
(This was the same for AMD Opterons, both in the 2000 series as well as the 200- and 800- series.)
"Now suppose that we have a 2-socket system, meaning two memory nodes, and that we have not specially architected our database in a manner to achieve higher memory locality than expected from random access patterns. Any memory access is equally likely to be in either node. The local node memory continues to be 67ns. Let us suppose remote node memory access is 125ns. Average memory access is now (67+125)/2 = 96ns, or 288 cycles "
The latency to its adjacent thread “core” is a LOT lower than any other pairwise core measurement.
This again, provides further evidence which contradicts your statement in terms of the latency topology of physical vs. “virtual” cores.
And you will note that in the latency plot for the 5950X, this pattern also is shown as well. (e.g. core0 to core1 has a latency of 6.6 ns. core2 to core3 has a latency of 6.7 ns. core4 to core5 has a latency of 6.7 ns. etc., etc.)
Therefore; once again, the data that is shown does not support your statements that core16-31 are virtual cores based on the latencies measured in ns. (e.g. core16 to core17 is 6.9 ns latency).
Like I said in my analogy where you have two groups of 8 people facing each other. Your statement proposes that your right arm talking to your left arm has a 80.5 ns latency. But your right arm, talking to the right arm of the person furthest from you, has a 17.0 ns.
That makes NO sense whatsoever.
Why WOULDN’T the latency of your right arm talking to your left arm be 6.6 ns?
Wouldn’t that make more sense that your right arm talking to your left arm would have a LOWER latency as opposed to a HIGHER latency?
Think about it.
I don’t understand where you got your data from which would lead you to conclude that your right arm talking to your left arm = 80.5 ns latency, but your right arm talking to the right arm of the FURTHEST person from you, would have only a 17.0 ns latency.
I have completely and utterly failed to grasp/see how this can PHYSICALLY be possible.
I’ll need to read your sources of data to be able to get there.
Why not?
You have to leave your physical, on-die package, exit through the IF connector to IF connector on the cIOD, and the leave said IF connector on the cIOD to the IF connector on the second CCD, before it can fetch the data and reverse through the entire path. So, why wouldn’t that be the case?
We know that the IF connector on the first CCD can only write to the IF connector on the cIOD at 16B/cycle, meanwhile, the IF connector on the CCD can read from the IF connector on the cIOD at 32B/cycle. (it can read twice as fast as it is able to write.)
You don’t have this latency with on-die communications going between core0-through-core7 in pairwise configurations.
Here is the core configuration (without SMT on one of my 5950X nodes):
Latency time from master to core 1 = 0.495 microseconds
Latency time from master to core 2 = 0.473 microseconds
Latency time from master to core 3 = 0.472 microseconds
Latency time from master to core 4 = 0.466 microseconds
Latency time from master to core 5 = 0.464 microseconds
Latency time from master to core 6 = 0.469 microseconds
Latency time from master to core 7 = 0.466 microseconds
Latency time from master to core 8 = 0.707 microseconds
Latency time from master to core 9 = 0.710 microseconds
Latency time from master to core 10 = 0.723 microseconds
Latency time from master to core 11 = 0.710 microseconds
Latency time from master to core 12 = 0.713 microseconds
Latency time from master to core 13 = 0.710 microseconds
Latency time from master to core 14 = 0.716 microseconds
Latency time from master to core 15 = 0.709 microseconds
And here is the bandwidth:
Communication speed from master to core 1 = 20710.95 MB/sec
Communication speed from master to core 2 = 23530.03 MB/sec
Communication speed from master to core 3 = 23572.79 MB/sec
Communication speed from master to core 4 = 25452.80 MB/sec
Communication speed from master to core 5 = 24961.42 MB/sec
Communication speed from master to core 6 = 25813.86 MB/sec
Communication speed from master to core 7 = 23913.58 MB/sec
Communication speed from master to core 8 = 7773.75 MB/sec
Communication speed from master to core 9 = 7719.62 MB/sec
Communication speed from master to core 10 = 7801.67 MB/sec
Communication speed from master to core 11 = 7705.42 MB/sec
Communication speed from master to core 12 = 7741.28 MB/sec
Communication speed from master to core 13 = 7734.97 MB/sec
Communication speed from master to core 14 = 7628.75 MB/sec
Communication speed from master to core 15 = 7551.40 MB/sec
So…why WOULDN’T haven’t to exit the on-die package of the first CCD to go to the second CCD – why wouldn’t it have a higher latency???
(Again, the data provided above comes directly from the solver itself, which clearly shows an increase in latency starting with core0-core8 communication (vs. core0-core{1…7}.)
The data doesn’t support your statement above.
Please cite your sources which provides the data which leads you to draw the conclusions that you’ve drawn.
Agreed. Correct.
They’re all used, at the same time, simultaneously.
Therefore; your statement about how the second grouping of increased latency is because all of those cores are virtual cores would fly in the face of the statement you just made here, that you don’t have a primary CCD/CCX and a secondary, “backup” CCD/CCX. You have the two CCDs/CCXs and they both work together, at the same time, to work on your data that you’re throwing at it for it to work on.
Therefore; it given your statement, it would be impossible for cores 16-31 to be virtual cores because like you said, you don’t have a second CCD/CCX “that’s just doing backup work”.
Yeah, I know.
This is why my micro cluster headnode uses an Intel Core i7 4930K because it has 48 PCIe 3.0 lanes from the CPU.
The last of that relic.
All of the processors newer than that only have 20-24 PCIe lanes at best.
(Sidebar: this is where the Intel SKUs with the integrated GPUs sometimes is useful because then it doesn’t take up said precious PCIe lanes for a dedicated GPU and the upcoming AMD AM5 processors which are also all slated to have some kind of an iGPU, will also help with this. But this is also the crap market segmentation that companies do, because Threadripper would provide an abundance of PCIe lanes, but a single Threadripper CPU can cost as much as an entire Ryzen 5950X system. The Threadripper 3955WX is a 16-core part, and that’s currently going for $1489.65 on Newegg. (So ALMOST the cost of an entire Ryzen 5950X node with 128 GB of DDR4-3200 RAM.))
Trust me, I’ve ran the analysis to see which platform/system would be a better bang for the buck.
Yes, but if you aren’t running anything on the main thread and instead are running it on the logical thread; then they are almost the same speed. If something is occupying the main thread, then the second thread isn’t as fast. Because the second thread is not magic, it is based on using the same physical resources.
you are assuming that latency is literally everything, it is not everything. In many cases it doesn’t matter. It only depends on how fed the core is. Not everything is latency intensive. This is how they improved latency with Zen3 and gaming performance shot up immensely vs Zen2 without a massive performance uplift (at the same clockspeeds) vs Zen2 unless it was for latency intensive workloads (like gaming).
Your sources don’t back up the shit you are claiming either. This is a picture of communication from Core 0 to Core 8 (on the second CCD) having higher latency. Of course it would have higher latency because you are crossing the I/O die.
I’m talking about the latency from Core 8 to Core 9 being the same. However if you are not using Hyper Threading, then you aren’t dealing with the HT core latencies.
The Anandtech diagram shows 16 cores/threads with higher latency. However they are doing a plot of CORE TO CORE latency, not Core 0 to each other core. So in this diagram it shows that Ryzen cores are connected directly with the core next to them. It also shows that all the Virtualized cores have higher latency to each other and to the non-virtualized cores. Not that the latency of every single operation on the second CCD is just 5x higher than the first CCD. Since that makes no sense, and it is not how the CPUs are designed. This is what I have been trying to point out since the beginning. Instead you decided to write a fucking huge wall attacking everything that I said trying to help you.
Outside of this, the rest of your responses are just condescending jackassery.
You can just go fuck yourself and contact AMD to figure out the latency of the chips. I’m done wasting my time to try to help you get to the bottom of this.
Because none of your cited resources tell you the answer, you came here to try to find it out.
if you are using only 16 threads instead of 32 and are still hitting the latency penalty then you have either uncovered a design flaw or you are doing something wrong.
To claim that the second CCX somehow has 1/4th the bandwidth of the first CCX is just nonsense to say the least. No tests hold water in that scenario as the performance of any cores on a second CCD/CCX would be destroyed, and yet they aren’t.
That is an HEDT chip on an HEDT platform with a similar cost to Threadripper.
Threadripper PRO is even more expensive and it doesn’t make sense for most workloads, but your workloads are indeed what Threadripper is made for. Much larger PCI-E workloads which need max bandwidth to all cores at all times. Welcome to the literal reason that Threadripper was created.
however you don’t want to pay for Threadripper and instead want to cry about why the desktop platform for consumer use doesn’t fit your use case and then talk about how you are using a non-consumer HEDT platform as your main node because it does have enough bandwidth.
Good luck to you in figuring out the latency issues.
I’m done here.
I was wondering if your finite element thing is tensorflow based by any chance - or if it can be somehow made to compile down to TPUv4, are you at least using COO for your sparse matrices?
… but that’d probably cost a ton to rent, simply for the novelty factor.
Alternatively you could steal the TPUv4 ML training pods architecture, but do it cheaper/slower without programmable fiber chip-chip interconnects, e.g. get older single socket Rome epyc CPUs for cheaper per core than the 5950x (slower CPUs but tons of lanes) and build 100Gbps infiniband cuboids with multiple nics and GPUs in each host - and daisy chain/mesh the host machines into either a 2d mesh or make it wrap around into a torus and do static routing for data between non-directly connected nodes.
That doesn’t make any sense and/or your statements are not internally consistent.
Per your statement:
"
You can use process affinity mask to literally test that and check the veracity of your statement.
According to you, the virtual cores would have a higher latency than the physical cores.
Therefore; pursuant to that statement, if you are running a single process application, you can use the process affinity mask (i.e. taskset if you’re using Ubuntu) to set/force the core that your process will run on and then you can time how long it would take for the process to complete on a low(er) latency physical core vs. the high(er) latency virtual core, again, pursuant to your own statement.
Therefore; pursuant to your own statement, running the same process twice – once on the physical core, and the second time on the virtual core – because you said that the latency on the virtual core will be higher because it is a virtual core, not a physical core, therefore; you should EXPECT that the time it would take the virtual core to complete this process would be HIGHER than the time it would take said physical core to complete the same process.
This is all based on the statements that you’ve made.
It’s a simple experiment that you can create, and execute in order to generate the data that will either confirm (or deny) your hypothesis/the statements that you’ve made.
Like I said, I’ll wait here (for you to report back your findings).
It is a part of it when you are trying to calculate the theorectical peak bandwidth limit as it “physically” (electrically?) tells you what’s the maximum pace that data can be transmitted multiplied by the bit width of the bus/interface.
1 / (80.5 ns) = 12.4223602 MHz.
1 / (17.0 ns) = 58.8235394 MHz.
if the width of the bus/interface is 128 bits, then:
128 bits * 12.4223602 MHz = 1590.0621056 Mbps.
128 bits * 58.8235394 MHz = 7529.4130432 Mbps.
So, yes, the latency plays a SIGNIFICANT role in the bandwidth.
If you want the 80.5 ns latency to be able to have a higher bit rate/bandwidth capacity, the only way that you would be able to achieve that is by increase the width of the bus/interface itself.
e.g., if you increased the width of the bus/interface from 128 bits to 512 bits, then:
512 bits * 12.4223602 MHz = 6360.2484224 Mbps
start to get you closer towards the 7529.4130432 Mbps bandwidth that you were able to attain with the lower latency.
Bandwidth and latency are inter-related where bandwidth = bus/interface width * 1/latency.
You can increase the bandwidth by increasing the width of the bus/interface and/or you can increase the bandwidth by reducing the latency.
(Again, this is just the computer engineering theory (and a bit of computer science theory), where we’re not even talking about the different technology types yet. This is more fundamental and more basic than the specific technology or implementation of these fundamentals of computer engineering.)
You DO realise the irony in your statement here, right?
You write quote “In many cases it doesn’t matter…Not everything is latency intensive” and then go on to cite the gaming example, which per your own statement “…unless it was for latency intensive workloads (like gaming).” (which followed your statement: “This is how they improved latency with Zen3 and gaming performance shot up immensely”, whereby you wrote that, AFTER you had just written about how “in many cases it doesn’t matter…not everything is latency intensive.”)
To that end, that also depends on the type of workload, yes, I agree.
For example, if you short-stroke a CPU cycle in one second (i.e. the CPU can perform x number of floating point operations per second, and the task that you are trying to perform does not required said x number of operations before the task is complete, then based on CPU clock speed pacing, you’ll finish that task before the next “round” of operations can be executed.
If say, your processor is capable of 100 GFLOPs of single precision computations, and you only need 75 GFLOPs, then you will only use 75% of the CPU’s compute capability for that second.
Conversely, if you have an application which depends on you being able to get data into and out of the CPU core, then the rate at which you can get said data into and out of said core would be highly dependent on bandwidth, which as I’ve stated in the fundamentals of computer engineering about, is a function of the bus/interface width * 1/latency (e.g. frequency).
Therefore; if you kept the bus/interface width the same (which is what happened between the cIOD of Zen2 and cIOD of Zen3), then the way that you would be able to improve on the bandwidth would be by reducing the latency, which is exactly the same thing that you said.
In other words, you are making statements that actually are internally inconsistent to some of the other statements that you are making, whilst at the same time, agree with the statements that I’ve also, already made.
a) At least I am providing sources with respect to the statements that I’m making, which you aren’t.
b) Yes, my sources DO back up what I am stating:
Take a look at the 5950X latency plot again:
Your statement is that the reason why the latency going from core0 to core16 is because it is going to the virtual core.
And yet, if you look at the latency of going from core0 to core 1, it’s 6.6 ns.
Going from core0 to core2, it’s 16.2 ns.
Going from core0 to core3, it’s 16.2 ns.
Going from core0 to core4, it’s 14.8 ns.
Going from core0 to core5, it’s 14.8 ns.
Going from core2 to core 3, it’s again, 6.7 ns.
The 5950X has two core chiplet dies (CCDs), and each CCD has a Core Complex (CCX), where for the 16-core/32-thread 5950X, each CCX only has 8 cores, and each core is capable for SMT2.
But your statement is that the reason why the latency going from core0-to-core16 is 4.735 TIMES higher is because core16 is a virtual core.
That’s what you said here:
You further acknowledge the fact that the data/communications have to cross the I/O die here:
Therefore; given the fact that each CCX/CCD only has 8 cores, the first CCD/CCX, ought to have core0-7, and the second CCD would have core8-15.
And yet, if you look at the latency of going from core0 to core8, it’s 15.7 ns.
That’s a LOWER latency than what it takes core0 to go to core2 (recall: 16.2 ns).
How can that be?
You just said, quote:
CCD/CCX0 would have core0-7
CCD/CCX1 would have core8-15
Therefore; core0-to-core8 communications would have to traverse the I/O die, per your statement, which, also per your statement, is supposed to have a HIGHER latency BECAUSE it has to traverse the I/O die.
And yet, core0 on CCD/CCX0 communicating over the I/O die to get to core8 on CCD/CCX1 has a LOWER latency (15.7 ns) compared to core0 talking to another core on the SAME CCD/CCX0 core0-to-core2 communication, has a HIGHER latency of 16.2 ns.
How is that REMOTELY possible, pursuant to the statements that you’re making???
The data LITERALLY does not support your statement in that the communication of core0 (on CCD/CCX0) talking to core8 (on CCD/CCX1) which traverses the I/O die, does NOT result in an increase in latency, in direct contravention to the statement that you’ve made above.
You said that the communication which needs to traverse through the I/O die will have a higher latency.
You said that core16 through core31 are virtual cores, according to your own statement here:
And yet, the actual, measured latency of the communications going from core0 to core8 is LESS than the latency of the communications which does NOT need to traverse the I/O die of going from core0 to core2 (as core2 resides on the SAME CCD/CCX0 as core0).
How is that REMOTELY possible?
You bitch about quote “Your sources don’t back up the shit you are claiming either” and yet, between the two of us, I am the ONLY one out of the two, that’s actually providing ANY source citations at all (whereas, so far, you’ve provided ZERO sources/citations for the claims that you are making), AND the fact that LITERALLY, the sources that I have provided does a MUCH better job of backing up what I am saying than it does in regards to backing up what you are saying.
core0 is on CCD/CCX0
core8 is on CCD/CCX1
to get to core8, you will need to traverse through the I/O die.
You said:
core0 (on CCD/CCX0)-I/O die-core8 (on CCD/CCX1) latency is 15.7 ns
core0 (on CCD/CCX0)-core2 (on CCD/CCX0) latency is 16.2 ns.
Therefore; core0-I/O die-core8 does NOT have a lower latency than core0-core2 communications.
Therefore; my sources does NOT support your statement, but rather supports the statements that I am making.
You have argued here:
And yet, so far, you have completely and utterly failed to provide ANY source that actually supports your claim/assertion.
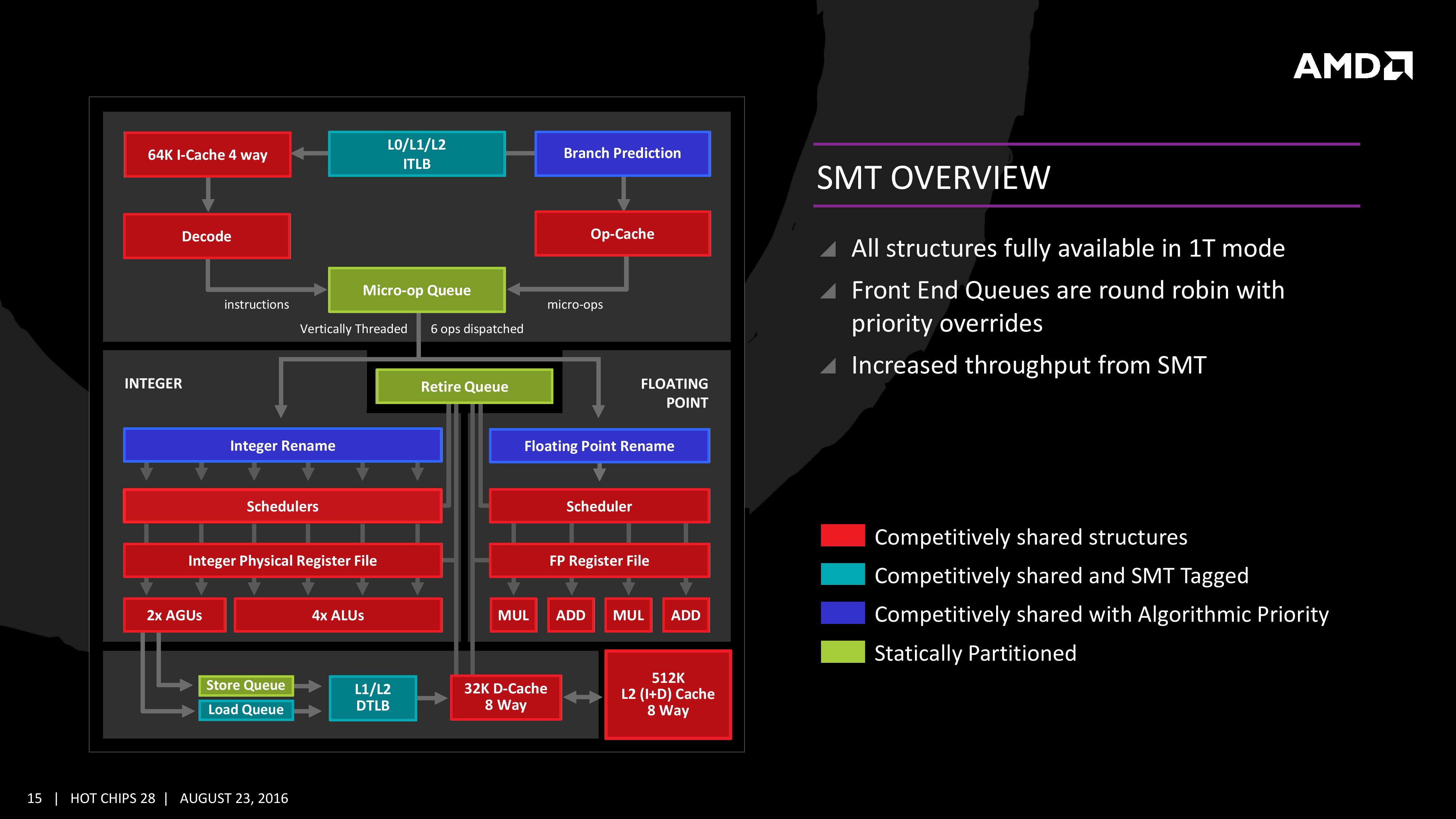
In fact, AMD’s own slide, from the original Zen(1) architecture presentation talks about AMD’s SMT implementation:
Therefore; if each physical core is SMT2, why in the world would core16-core31 be quote “a virtual core” which would have a latency into the 80+ ns range? when the LOGIC is LITERALLY shared between the threads, according to AMD’s own architecture presentation/slides.
Why would the execution of the second thread incur a 373.5% latency penalty, when, according to AMD’s own architecture presentation/slides, the second thread PHYSICALLY lives on the same PHYSICAL core as the first thread?
You have FAILED to explain this.
You have FAILED to provide ANY sources which confirms your statement that core15-core31 are virtual cores, which is why it has a 373.5% latency penalty.
You have FAILED to be able to explain why core0-core1 has a latency of 6.6 ns.
You have FAILED to be able to explain why core0-core2 has a latency of 16.2 ns.
You have FAILED to be able to explain why core0-core8 has a latency of 15.7 ns.
You have failed to explain why in each pairwise configuation how there will ALWAYS be two results out of the four whereby the latency would be < 7 ns.
(e.g. look at the latencies of core0-core1, core2-core3, core4-core5, core6-core7, core8-core9, core10-core11, etc. – they’re ALL < 7 ns.)
All other latencies that’s on the same CCD/CCX are > 14 ns.
Therefore; if core15-core31 are virtual cores, then how in the world is the latency between core0-core2 and core0-core3 IDENTICAL?
More importantly than that, where would the virtual cores PHYSICALLY reside that would produce a 373.5% latency penalty?
(Again, your statements are LITERALLY arguing against AMD’s own architecture presentation/slides. That seems like it would be a TERRIBLE idea to argue against AMD ABOUT AMD’s own processors.)
“1.7.1 Features
Family 17h Models 00h-0Fh are a microprocessor System-On-a-Chip (SOC) featuring AMD x86 cores. It also
introduces integrated IO, and integrated southbridge control hub, SCH where no supporting chipset is necessary.
ï CPU:
ï 2 Core Complexes (CCX). The Core represents the x86 ISA core from AMD designed for FX and
7th generation APU offerings.
ï Supports Simultaneous Multithreading over previous generations clusters.
ï Each core complex consists of:
ï 4 cores where each core may run in single-thread mode (1T) or two-thread SMT mode (2T)
for a total of up to 8 threads per complex”
So far, you’ve made a lot of statements, but you haven’t been able to provide ANY sources/citations to back up ANY of your claims.
Unlike you, at least I’m citing my sources, which is, of course, more than what I can say in regards to you.
As I’ve said before, I enabled SMT to generate the lstopo picture which shows the logical layout, which conforms to the AMD technical documentation/specification, as published, by AMD.
“Description: For Family 17, Model 1, Revision 1 and later:
CoreId = ({2’b0, DieId[1:0], LogicalComplexId[0], LogicalThreadId[2:0]} >> SMT).”
“2.1.10.2.1.3 ApicId Enumeration Requirements
Operating systems are expected to use Core::X86::Cpuid::SizeId[ApicIdCoreIdSize], the number of least
significant bits in the Initial APIC ID that indicate core ID within a processor, in constructing per-core CPUID
masks. Core::X86::Cpuid::SizeId[ApicIdCoreIdSize] determines the maximum number of cores (MNC) that the
processor could theoretically support, not the actual number of cores that are actually implemented or enabled on
the processor, as indicated by Core::X86::Cpuid::SizeId[NC].
Each Core::X86::Apic::ApicId[ApicId] register is preset as follows:
ï ApicId[6] = Socket ID.
ï ApicId[5:4] = Node ID.
ï ApicId[3] = Logical CCX L3 complex ID
ï ApicId[2:0]= (SMT) ? {LogicalCoreID[1:0],ThreadId} : {1’b0,LogicalCoreID[1:0]}.”
If you want “core0 to each other core”, all you LITERALLY would have to do is read across the plot, look for core0 on the first row, and read across the plot.
Like…how the fuck do you not know how to read a plot???
LOL…LMAO…
This means that you can look up ANY pairwise configuration, and find the latency in nanoseconds.
Are you fucking for real???
LOL…BWAHAHAHAHA…
Bullshit.
Once again, you have LITERALLY provided ZERO sources that even REMOTELY show that core16-core31 are the virtualised cores and that core0-core15 are the physical core.
In fact, you can literally email Dr. Ian Cutress so to whether your statement is correct.
You know what?
Since you seem to be incapable and incompetent enough NOT to cite ANY sources for the claims that you are making, I’ll email Dr. Ian Cutress for you, asking him directly, whether your interpretation of their plot is correct or not.
Make this so much easier/faster for the both of us.
(This is of course, where you are LITERALLY completing neglecting what Dr. Ian Cutress and Andrei Frumusanu has already written in the article in regards to how to read and interpret the results from said plot:
"On the new Zen3-based Ryzen 9 5950X, what immediately is obvious is that instead of four low-latency CPU clusters, there are now only two of them. This corresponds to AMDís switch from four CCXís for their 16-core predecessor, to only two such units on the new part, with the new CCX basically being the whole CCD this time around.
Inter-core latencies within the L3 lie in at 15-19ns, depending on the core pair. One aspect affecting the figures here are also the boost frequencies of that the core pairs can reach as weíre not fixing the chip to a set frequency. This is a large improvement in terms of latency over the 3950X, but given that in some firmware combinations, as well as on AMDís Renoir mobile chip this is the expected normal latency behaviour, it doesnít look that the new Zen3 part improves much in that regard, other than obviously of course enabling this latency over a greater pool of 8 cores within the CCD.
Inter-core latencies between cores in different CCDs still incurs a larger latency penalty of 79-80ns, which is somewhat to be expected as the new Ryzen 5000 parts donít change the IOD design compared to the predecessor, and traffic would still have to go through the infinity fabric on it."
But hey. Reading, right? Who fucking does that anymore??? LOL…LMAO…
(If I don’t write it, that’s my fault. If you don’t read it, it’s yours.)
You can measure idle load latency.
“If you are a regular reader of AnandTechís CPU reviews, you will recognize our Core-to-Core latency test. Itís a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.”
Therefore; if you have a lightly loaded CPU, the latencies that your load will incur will more than likely, be closer to the idle, latent, latencies rather than any load-dependent latencies introduced as a result of competition of the same physical, hardware resources, which is something else entirely.
(I’m not sure if you’d even HAVE a way to be able to accurately measure any sort of load-dependent latencies, and to be able to do so is a deterministic, statistically significant manner where you’d be able to draw any meaningful conclusions from performing such a test.)
The PROBLEM with this statement is that your fundamental assumption about what you think is fact re: core16-core31 are the virtualised cores is principally and fundamentally flawed.
This assumption of yours forms the entire basis of your argument.
Therefore; when your assumption is critically and catastrophically flawed to such an extent/degree, then EVERYTHING that you’ve argued that DEPENDS on this assumption to be true, would likewise, crumble to the ground.
As I have stated, so far, you have provided ZERO sources/citations that actually SUPPORTS your claim and assumption that core16-core31 represents the virtualised cores.
In fact, again, according to AMD’s own technical presentation on the Zen architecture itself, they TELL you that each PHYSICAL core is capable of simultaneously multithreading, running two threads per core (SMT2). It’s in their architecture presentations and it’s also found in AMD’s own technical and developer documentation (about how to program and/or read, for example, APIC ID).
You posit the statements that core16-core31 are the virtualised cores and yet you have provided ZERO sources and citations to actually back up this claim of yours.
You then posit that you DON’T have a “main” CCD/CCX and a “second” CCD/CCX to do “backup” work, and yet you haven’t been able to explain what is the PHYSICAL layout of the virtualised core16-core31 such that it would produce an almost 5x higher latency JUST because quote “it’s a virtualised” core.
You have FAILED to explain how, even at idle, (which is how Andrei Frumusanu has written the code, because if all it is doing is just measuring latency, you DON’T need to load up the cores to be able to do that), that there can be an almost 5x increase in latency.
Your entire argument relies on your assumption that core16-core31 are the virtualised cores.
YESSS!!! Because:
a) you have FAILED to provide any source or citation that actually supports your claim that core16-core31 are actually, indeed virtualised cores.
Again, your claim LITERALLY ignores the write-up that Dr. Ian Cutress and Andrei Frumusamu has written where Andrei Frumusamu was the one who WROTE the core-to-core latency program, and therefore; their write-up would be written LITERALLY by the same person who WROTE the software that was used to obtain these core-to-core latency test results.
and b) EVERY other source that I have cited/sourced CONTRADICTS your claim that core16-core31 are virtualised cores.
It LITERALLY makes NO sense whatsoever.
It’s not my fault that you aren’t able see/recognise/understand this.
Again, you argue that core16-core31 are the virtualised core, and yet, you have FAILED to be able to explain how said virtualised cores would be PHYSICALLY arranged, on-die, that would produce this result where the latency compared to the PHYSICAL cores will be almost 5x HIGHER.
I want you to stop and THINK about what you’re actually saying for a moment.
How would the VIRTUALISED cores be arranged PHYSICALLY in order to be able to create this result?
Just stop and THINK about it for a moment.
Your argument is getting attacked because it is quite clear and evident that you AREN’T stopping and thinking about what it is that you are actually saying and how what you are saying would ACTUALLY be (physically) possible.
Think about it.
AMD’s own architecture presentation/slides TELLS you that each PHYSICAL core supports two threads via SMT2, which means that each PHYSICAL core will show up as two LOGICAL cores. Your use of the nomenclature of “PHYSICAL” vs. “VIRTUALISED” cores suggests, in your mental model, that you can somehow PHYSICALLY separate the PHYSICAL core from the VIRTUAL core despite the fact that there is literally ZERO evidence that you’ve provided that that can be PHYSICALLY possible, in the on-die CPU package.
Therefore; given how a “virtual” (e.g. logical core) ACTUALLY operates (again, cf. the old Intel slide on how HTT works), how in the world can you produce a PHYSICAL (as measured by time) 5x increase in latency (as measured by time)?
Your arguments are being attacked because you have FAILED to be able to defend the arguments and statements that you are making.
You should’ve learned how to defend your position by being able to provide sources and citations that will provide supporting documents and evidence that would be able to corroborate the claims and statements that you’re making. You have FAILED to do that. You should’ve learned how to do defend the arguments that you’re making, in ELEMENTARY school.
It’s not my fault that you can’t defend the shit that you’re saying with TWO hands and a flashlight. I can’t help you with that, if you aren’t able to see how stupid your arguments are given the fact that you can’t explain how this is PHYSICALLY possible GIVEN all of the documentation that I have already sourced and cited.
If you don’t want to read, that sounds like it’s a you problem to me.
Without your sources and citation, there is no way that anything that you’ve said is helpful in any way, shape, nor form.
If you were really sure of your argument, then you should have no problems being able to find the AMD technical documentation to support your claims and the statements that you are making, and that way, I can read your source information and learn from it.
But you HAVEN’T done that.
In fact, the only that you’ve done is the opposite whereby I would provide the sources and evidence to you, and you would make statements like “your evidence/sources doesn’t prove shit” and then you would FAIL to defend your position and explain how and/or why my sources/citations DOESN’T prove shit (i.e. what’s wrong with my sources and citations?) Anybody can say that other people’s sources and citations is shit.
Unlike you, I’ve been able to claim that your arguments are shit, and then tell you and explain to you precisely WHY and HOW your arguments are shit, by sourcing and referencing the TECHNICAL presentation, where the information on said architecture/technical presentation comes DIRECTLY from AMD, the manufacturer of the CPU itself; whom you have DELIBERATELY chosen to ignore.
It’s not my fault that you’re too dumb to see how stupid your argument DESPITE all of the data and evidence that has already been provided to you where every single time I share something with you, the evidence that is shared DIRECTLY contradicts your preceding statements that you’ve made.
If you’re too stupid to be able to see and recognise this and/or your apparent INABILITY to be able to explain why the evidence is what it is, in the CONTEXT of the statements that you’re making, then it just further shows just how bad you are at defending the statements and arguments that you’re making.
NONE of your responses answer my question neither, so I don’t know where you think you’re going with that statement.
In fact, NONE of your responses here has ANYTHING to do with my actual OP, and therefore; everything that you’ve said here is completely useless with respect to my actual OP.
Read my OP again and then read each and every single one of the responses that you’ve provided so far, and ask yourself how your responses even remotely related to my actual OP?
(Hint: They don’t. NONE of your responses do.)
Nothing you’ve said has helped in the slightest.
core16-core31 AREN’T virtualised cores.
You argue that they have a higher latency because they’re virtualised cores.
And yet, if you actually look at the core30-core31 latency, its 6.9 ns.
According to you, core16-core31 are virtualised cores.
You’ve stated that virtualised cores have higher latencies. And yet, going from core30 (virtualised) to core31 (virtualised), is has about the same latency as core6 (non-virtualised core) to core7 (non-virtualised core) of 6.8 ns. According to your statements, virtualised core would be slower that the non-virtualised cores, and yet, the LITERAL data shows that the latency going from a virutalised core to another virtualised core is about the same as the latency going from a non-virutalised core to another non-virtualised core.
According to your statement about how virtualised cores have a higher latency and/or should be slower, the data does NOT show that.
You claimed that core16-core31 are virtualised cores. And yet, the latency going from core16 to core31 is 17.5 ns, which is FASTER than going between core0(non-virtualised) to core10(non-virtualised) which has a latency of 17.6 ns.
The data and the evidence LITERALLY disproves your statement.
I thought you said that the virtualised cores would be slower and/or have higher latency?
I thought you said that core16-core31 were virtualised cores?
Then how do you resolve the fact that the latency of core16-to-core31 is 17.5 ns (which is virtualised core to virtualised core, which according to you, should be slower), and yet, the core0-to-core10 latency is 17.6 ns (which is the latency between two non-virtualised cores).
You argue that my sources doesn’t prove my point, and yet the same data DEFINITIVELY shows how your statements is a PHYSICAL impossibility and DOES NOT reflect or how the data rejects the hypotheses of your statements.
You have literally FAILED to explain these “anomalies” in the data with respect to the statements that you’ve made; and those aren’t just “one-off” anomalies neither. There are many, multiple instances where the data doesn’t jive with your statements.
It is for these reasons:
a) you have failed to provide ANY sources/citations to back up what you’re saying, because if your what you’re saying is true, you should have NO problems providing said sources and/or citations in order to support your points of argument and
b) because you have FAILED to explain how the data actually confirms your statements/claims that you’ve made
these are the reasons why your argument is shit.
It’s not my fault that you’re too dumb to be able to see/recognise this discrepancy between the data and your statements.
…OR…if you’ve actually READ the Anandtech article, where they LITERALLY, explicitly tell you:
“On the new Zen3-based Ryzen 9 5950X, what immediately is obvious is that instead of four low-latency CPU clusters, there are now only two of them. This corresponds to AMD’s switch from four CCX’s for their 16-core predecessor, to only two such units on the new part, with the new CCX basically being the whole CCD this time around.
…
Inter-core latencies between cores in different CCDs still incurs a larger latency penalty of 79-80ns, which is somewhat to be expected as the new Ryzen 5000 parts don’t change the IOD design compared to the predecessor, and traffic would still have to go through the infinity fabric on it.”
Tell you the answer to that.
I’ve sourced the article when I shared the core-to-core latency plot.
If’s your fault if you didn’t bother to read it.
And yet, the Communication speed bandwidth results as shown from the solver LITERALLY shows that going to the second CCD/CCX from the first CCD/CCX is about 32% of the bandwidth (on average) compared to the bandwidth WITHIN the same (first) CCD/CCX (7707.1075 MB/s (going to CCD/CCX1 from CCD/CCX0) vs. 23993.6329 MB/s (going to CCD/CCX0 from CCD/CCX0)).
The results LITERALLY aligns and is consistent with what Dr. Ian Cutress and Andrei Frumumasu wrote in their article about the 5950X:
"Inter-core latencies between cores in different CCDs still incurs a larger latency penalty of 79-80ns, which is somewhat to be expected as the new Ryzen 5000 parts don’t change the IOD design compared to the predecessor, and traffic would still have to go through the infinity fabric on it.
For workloads which are synchronisation heavy and are multi-threaded up to 8 primary threads, this is a great win for the new Zen3 CCD and L3 design…AMD still has a way to go to reduce inter-CCD latency, but maybe that something to address in the next generation design."
Dr. Ian Cutress/Andrei Frumumasu already TELLS you the answer to your point.
The data from the ACTUAL solver LITERALLY aligns to Dr. Cutress’ and Andrei Frumumasu’s conclusions that they’ve made, in regards to this.
And so far, you’ve only been able to bitch about how my sources/citations/data because it doesn’t conform to your mental model/pre-determined worldview in regards to how this actually works/what the data ACTUALLY shows.
You have consistently and repeatedly fail to explain why the results are what they are, GIVEN what all of my sources, authored by a VARIETY of people, INCLUDING AMD themselves, and instead, the most that you’ve been able to do is bitch about it, but falling short of being able to explain the HOW or the WHY the results are why they are.
You claim that core16-core31 are virtualised cores.
And yet, the output from lstopo from my 5950X system (where I purposely enabled SMT to be able to take the picture, and then turned SMT back off again so that I can run my simulation), LITERALLY tell you how the APIC ID/CPUID is assigned LOGICALLY (as explained to you by the linux man page itself, and also from the OpenMPI FAQ page re: hwloc.)
The lstopo output tells you that core16-core31 is NOT the virtualised core and yet, you REFUSE to accept the ACTUAL data which EXPLICITLY shows and proves that your statement is wrong.
The linux man page tells you that you’re wrong, and you refuse to accept that as well.
The OpenMPI FAQ about hwloc further tells you that your statement that “core16-core31 are virtualised cores” is also wrong and you refused to accept that as well.
I don’t give a fuck if you don’t want to agree with me. That’s your fucking perogative.
But if you want to ignore the linux man page, the OpenMPI group, AMD itself, the solver ISV, Andrei Frumumasu, and Dr. Ian Cutress (and anybody else whom I might have missed in this list who are the respective authors of the sources that I have cited along the way), now you’re just being a dumbass.
it’s one thing if you want to ignore me – that’s fine. That’s your perogative. But to ignore at least SIX other people who have written about this, and who’s work that they’ve authored says what you’re claiming are wrong, then you’re just a fucking dumbass.
And I can’t help you if you aren’t willing to change your mental model/pre-determined world view when you are presented with new data.
There is NOTHING that I can do nor say, and the presentation of any data or evidence is going to be ignored anyways. That’s just fucking stupid, but there’s nothing that I can do nor say is going to help you realise how fucking stupid the statements and the claims that you’ve made are.
The fact that the latency time output which comes DIRECTLY from the solver, shows you that the latency within the first CCD/CCX is around 0.47 microseconds and the latency going to the second CCD/CCX is around 0.71 microseconds – the fact that the DATA is LITERALLY telling you this, and you STILL are refusing to abide by what the DATA is telling you, and instead, you’re hanging on to your claims which I’ve already DEFINITIVELY demonstrated as being wrong/false – there’s nothing that I can do about that.
Latency time from master to core 1 = 0.495 microseconds
Latency time from master to core 2 = 0.473 microseconds
Latency time from master to core 3 = 0.472 microseconds
Latency time from master to core 4 = 0.466 microseconds
Latency time from master to core 5 = 0.464 microseconds
Latency time from master to core 6 = 0.469 microseconds
Latency time from master to core 7 = 0.466 microseconds
Latency time from master to core 8 = 0.707 microseconds
Latency time from master to core 9 = 0.710 microseconds
Latency time from master to core 10 = 0.723 microseconds
Latency time from master to core 11 = 0.710 microseconds
Latency time from master to core 12 = 0.713 microseconds
Latency time from master to core 13 = 0.710 microseconds
Latency time from master to core 14 = 0.716 microseconds
Latency time from master to core 15 = 0.709 microseconds
The latency results from the solver ISV output file for a simulation that I’ve ran CLEARLY shows that latency is higher going to the second CCD/CCX.
You even wrote, yourself:
This shows that even within your own argument, you can’t stay internally consistent within your own argument.
You are a literal fucking moron. As I mentioned before, go fuck yourself and figure out the issue yourself. If you can’t then too bad, you don’t honestly deserve to figure it out. Since you seem to spend hours writing messages to attack people trying to help you. Not only that, you can’t even read. So it doesn’t matter how many articles you think you read, you can’t comprehend anything you are reading.
Therefore I’m done. Go write 50 more walls of text if you want. I didn’t even read this 35 paragraph monologue of garbage you wrote up.
At the end of the day, you don’t know what you are talking about. You can’t learn because you can’t read and you want to harp on a single point that somehow makes you think you are correct. When the reality is that, you came here asking for help. I tried to help (nobody else really did) and you just proved you are a degenerate not worth helping.
Good luck with your desktop hardware as pro gear cluster processing project. Hope it fails on you.
Man. Imagine writing a post asking for help on a forum and then spending so much effort in writing absolute walls of horseshit.
Why the fuck would anybody help you now? Good luck on your project, seems you’re on your own. But hey, you’re the smartest guy here so shouldn’t be a problem eh?




{kind=link}