@BansheeHero at the step where you had us set up the vm for long term use you had us sudo virsh edit win10 but when I go to add <domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'>
it saves but doesnt apply and changes it back to just <domain type-'kvm'>
Did you use virt-manager to make any changes to the VM after the edit? It has this bad habit / bug where it ignores the namespace attribute and simply put thing as
Also take note that you are supposed to edit the existing <domain tag, not add an entirely new one.
For the qemu:command line, try copy and paste the text into a plain text editor, then copy and paste from that to ensure there aren’t any oddities introduced by HTML. I’ve encountered cases where spaces/quotation marks were not exactly the ASCII equivalent when pasting directly from a HTML enabled source.
Last but not least, double check where you placed the qemu block. It should be outside of the devices block and within the domain block, e.g.
@kacyl1
that seems to have fixed it, I could have swore I had put that in their before. But maybe because I wasn’t putting them in together and trying to save in-between it messed me up.
Now I just need to figure out why my vm isn’t showing my gfx card.
So I performed a fresh install of everything and started over from the beginning of the guide due to me running in to issues with my gpu not being recognized by the kvm. I got up to the step where we modify the vfio.conf and add
after I checked the grep vfio and restarted. The linux os said that it was in emergency mode. I literally followed everything step by step too. Anything I might have been missing to cause that?
Thanks in advance for any help, and happy new year.
In order to properly trouble shoot we’ll need to know why your system booted into emergency mode. You should be able to use the dmesg command to see the boot logs and look for any lines where things seem to have gone wrong.
My bet would be on something missing from the install_items line. Please ensure your system has those files (vfio-pci-override.sh, find, and dirname) and they’re executable.
Happy new year and I hope we can get this working!
When I was following the guide it definitely did not have the vfio-pci-override.sh file. I had to make by myself because it did not exist in the folder. I am running on fedora 31.
Even after adding a blacklist in my grep file for this its still displaying exactly the same as the image above. Not sure exactly why this is happening this way.
If you do not have two identical GPU, it is not necessary to use the vfio-pci-override.sh method. It would be simpler to use the device ID override.
Another thing is try adding vfio_virqfd to your dracut.conf.d/vfio.conf
It is not in the guide but I saw it was in the list at the archlinux PCI passthrough wiki, e.g. force_drivers+="vfio vfio-pci vfio_iommu_type1 vfio_virqfd"
In my case I am not using like hardware. I have intel hd graphics that im gonna use on fedora, thats all for coding, then I will pass through the nvidia to the kvm for gaming. Will that work for me since im fedora and not archlinux?
This is exactly the setup I have and the best way is to use the old fashioned block by IDs.
I will try to repost it here.
The new idea from Wendell was to use the location and not the Vendor IDs, this would allow you to have two exact GPUs and still split them.
For a setup like yours it is not necessary.
Hi, I currently have a working setup using Ubuntu 19.10 server, with 3 GPU’s all passed through (so no GPU is left for the system). Could you let me know what I would need to do differently on Fedora 31 to get this working please?
In case it helps anyone - I’ll just note down here some differences in the required commands for Fedora Silverblue users, compared to the guide’s Fedora Workstation commands.
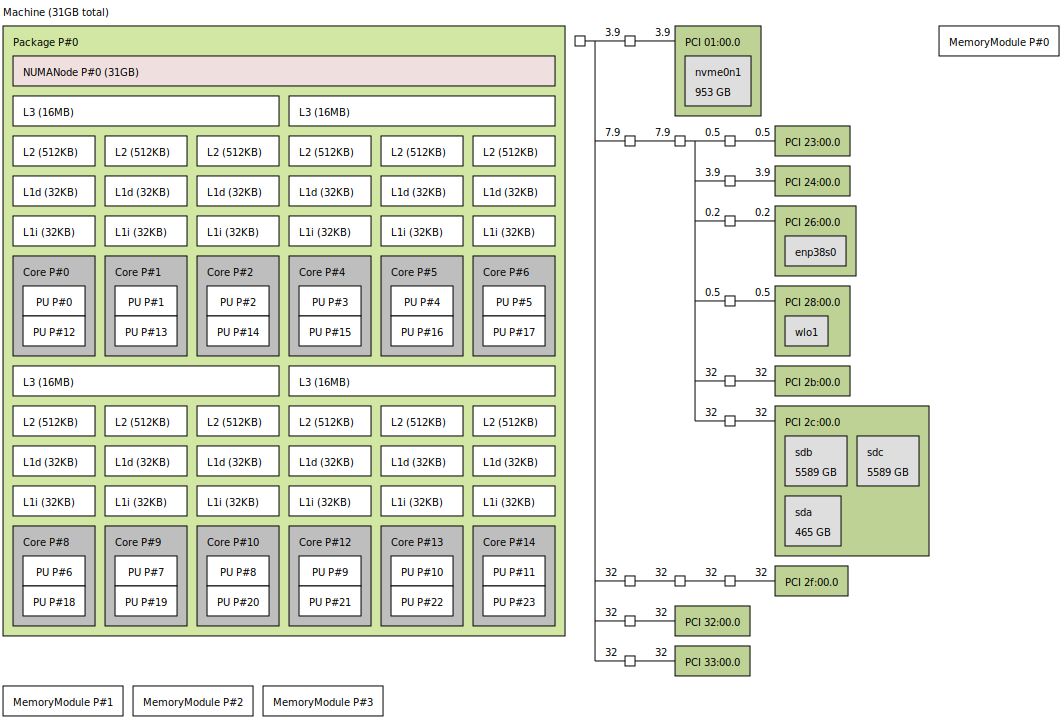
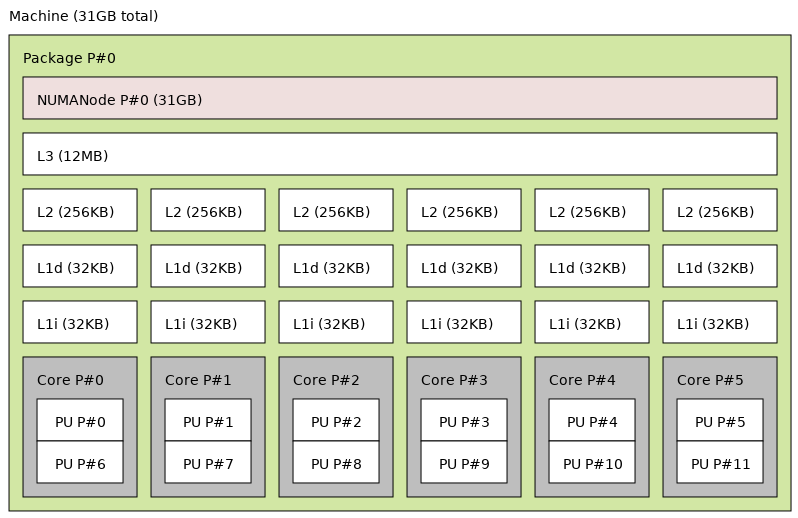
I’m a bit confused with the instructions on checking topology with hwloc. I’ve installed it and then run it via lstopo. This is the output it gives me:
As you can see, it just shows me one single MemoryModule/node. My guest GPU is PCI 2f:00.0 near the bottom right corner. What am I supposed to learn from this?
What cores would be best for the GPU then - or are they just all equivalent on this CPU (3900X)?
What do the numbers on the lines mean (e.g. 32 on the line coming off the guest GPU)?
Would it be better to pass through 9 cores instead of my intended 8 cores, to fully share the L3 cache?
From what I understand, this is less about your GPU and more about maximizing CPU performance. What you’re supposed to learn here is how your cores are numbered so that you can pass through threads which share a core, cores which share cache, etc. The idea is that the less jumping around the die, the better.
I think that anything would be fine for your GPU.
I’m not sure, but I would guess it’s IOMMU groups
You’re fine not saturating the L3 cache.
I would use cores 0-5, 12-17. This will neatly split your guest and host with 12 threads each, and no overlap on cache.
Hopefully this all makes sense, it can be a lot to take in!
These instructions are incomplete and will not work without an additional step.
There is nothing in here causing the script /usr/sbin/vfio-pci-override.sh to execute. To do that, you need to create a file like the following (you see it in the lsinitrd dump in the post):
Open an editor using: sudo vi /etc/modprobe.d/vfio.conf, and paste the following into the file:
Create that file and include it in your initial ram disk (initram), using dracut, as described in the post.
Also note, this step from the beginning of the post is for intel CPUs: dmesg | grep -i -e IOMMU | grep enabled
which should show a line of text with the word “enabled” in it.
For AMD CPUs, this is the command: dmesg | grep -i -e IOMMU | grep "counters supported"
and you should see some text like “AMD-Vi: IOMMU performance counters supported”
I also used this line in my /etc/dracut.conf.d/vfio.conf file: