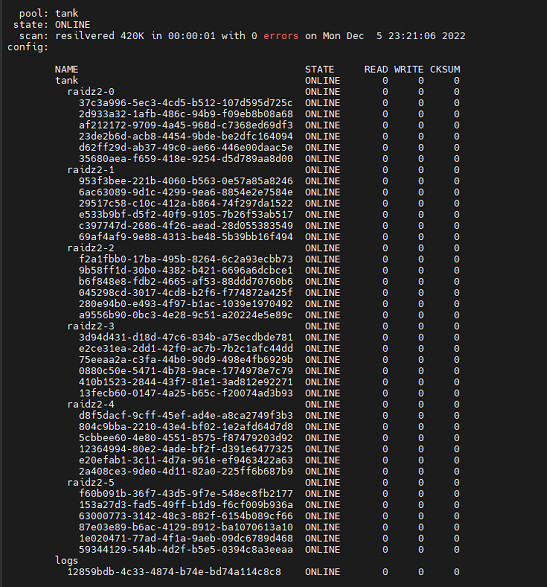
You have a couple of hardware errors in the boot log. I am not sure if these are related to your zpool issue, but it is something you probably want to look into.
These errors happen even before the mpt2sas driver is loaded.
From log
[ 0.807758] swapper/0: page allocation failure: order:12, mode:0xcc1(GFP_KERNEL|GFP_DMA), nodemask=(null),cpuset=/,mems_allowed=0-1
[ 0.811675] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G I 5.15.79+truenas #1
[ 0.815669] Hardware name: HP ProLiant DL380e Gen8, BIOS P73 05/24/2019
[ 0.815669] Call Trace:
[ 0.815669] <TASK>
[ 0.815669] dump_stack_lvl+0x46/0x5e
[ 0.815669] warn_alloc+0x13b/0x160
[ 0.815669] ? __alloc_pages_direct_compact+0xa9/0x200
[ 0.815669] __alloc_pages_slowpath.constprop.0+0xcc3/0xd00
[ 0.815669] ? __cond_resched+0x16/0x50
[ 0.815669] __alloc_pages+0x1e9/0x220
[ 0.815669] alloc_page_interleave+0xf/0x60
[ 0.815669] atomic_pool_expand+0x11d/0x220
[ 0.815669] ? __dma_atomic_pool_init+0x97/0x97
[ 0.815669] ? __dma_atomic_pool_init+0x97/0x97
[ 0.815669] __dma_atomic_pool_init+0x45/0x97
[ 0.815669] dma_atomic_pool_init+0xb9/0x15e
[ 0.815669] do_one_initcall+0x44/0x1d0
[ 0.815669] kernel_init_freeable+0x216/0x27d
[ 0.815669] ? rest_init+0xc0/0xc0
[ 0.815669] kernel_init+0x16/0x120
[ 0.815669] ret_from_fork+0x22/0x30
[ 0.815669] </TASK>
[ 0.815672] Mem-Info:
[ 0.818245] active_anon:0 inactive_anon:0 isolated_anon:0
active_file:0 inactive_file:0 isolated_file:0
unevictable:0 dirty:0 writeback:0
slab_reclaimable:30 slab_unreclaimable:3328
mapped:0 shmem:0 pagetables:3 bounce:0
kernel_misc_reclaimable:0
free:18478151 free_pcp:273 free_cma:61440
[ 9.471321] DMAR: [INTR-REMAP] Request device [01:00.0] fault index 0x27 [fault reason 0x26] Blocked an interrupt request due to source-id verification failure
The driver and drives (28) are identified and get connected fine.
[ 19.122820] ERST: [Firmware Warn]: Firmware does not respond in time.
What firmware is referred to here? Probably not storage related?
It takes another minute for the iscsi system to start ([ 78.583082] to [ 80.942195]) but seemingly without issues.
7 seconds later is what I think leads to the issues you’re seeing in ZFS.
Between [ 87.707695] and [ 102.484660] the system deals with the enclosure and all the drives not being accessible and as a result being removed from the system.
Then the enclosure gets reset and re-attached (starting [ 105.640809] through [ 115.005482]).
About two mins later there is storage related issue.
task txg_sync:7325 blocked for more than 120 seconds
[ 242.527903] INFO: task txg_sync:7325 blocked for more than 120 seconds.
[ 242.536657] Tainted: P IOE 5.15.79+truenas #1
[ 242.544577] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 242.554430] task:txg_sync state:D stack: 0 pid: 7325 ppid: 2 flags:0x00004000
[ 242.564925] Call Trace:
[ 242.568902] <TASK>
[ 242.572481] __schedule+0x2f0/0x950
[ 242.577470] schedule+0x5b/0xd0
[ 242.581999] schedule_timeout+0x88/0x140
[ 242.587310] ? __bpf_trace_tick_stop+0x10/0x10
[ 242.593152] io_schedule_timeout+0x4c/0x80
[ 242.598568] __cv_timedwait_common+0x128/0x160 [spl]
[ 242.604953] ? finish_wait+0x90/0x90
[ 242.609798] __cv_timedwait_io+0x15/0x20 [spl]
[ 242.615626] zio_wait+0x109/0x220 [zfs]
[ 242.621017] dsl_pool_sync_mos+0x37/0xa0 [zfs]
[ 242.627014] dsl_pool_sync+0x3ab/0x400 [zfs]
[ 242.632811] spa_sync_iterate_to_convergence+0xdb/0x1e0 [zfs]
[ 242.640268] spa_sync+0x2e9/0x5d0 [zfs]
[ 242.645611] txg_sync_thread+0x229/0x2a0 [zfs]
[ 242.651636] ? txg_dispatch_callbacks+0xf0/0xf0 [zfs]
[ 242.658586] thread_generic_wrapper+0x59/0x70 [spl]
[ 242.664940] ? __thread_exit+0x20/0x20 [spl]
[ 242.670630] kthread+0x127/0x150
[ 242.675139] ? set_kthread_struct+0x50/0x50
[ 242.680680] ret_from_fork+0x22/0x30
[ 242.685564] </TASK>
[ 242.688935] INFO: task agents:9256 blocked for more than 120 seconds.
[ 242.698756] Tainted: P IOE 5.15.79+truenas #1
[ 242.708194] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[ 242.719637] task:agents state:D stack: 0 pid: 9256 ppid: 1 flags:0x00000000
[ 242.731879] Call Trace:
[ 242.737582] <TASK>
[ 242.742977] __schedule+0x2f0/0x950
[ 242.743030] schedule+0x5b/0xd0
[ 242.754461] io_schedule+0x42/0x70
[ 242.754482] cv_wait_common+0xaa/0x130 [spl]
[ 242.767147] ? finish_wait+0x90/0x90
[ 242.767180] txg_wait_synced_impl+0x92/0x110 [zfs]
[ 242.780708] txg_wait_synced+0xc/0x40 [zfs]
[ 242.789230] spa_vdev_state_exit+0x8a/0x170 [zfs]
[ 242.798152] zfs_ioc_vdev_set_state+0xe2/0x1b0 [zfs]
[ 242.807327] zfsdev_ioctl_common+0x698/0x750 [zfs]
[ 242.816286] ? __kmalloc_node+0x3d6/0x480
[ 242.823730] ? _copy_from_user+0x28/0x60
[ 242.831118] zfsdev_ioctl+0x53/0xe0 [zfs]
[ 242.839031] __x64_sys_ioctl+0x8b/0xc0
[ 242.846057] do_syscall_64+0x3b/0xc0
[ 242.852939] entry_SYSCALL_64_after_hwframe+0x61/0xcb
[ 242.861637] RIP: 0033:0x7f310d7326b7
[ 242.868844] RSP: 002b:00007f310c97f308 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
[ 242.880305] RAX: ffffffffffffffda RBX: 00007f310c97f320 RCX: 00007f310d7326b7
[ 242.891329] RDX: 00007f310c97f320 RSI: 0000000000005a0d RDI: 000000000000000d
[ 242.901808] RBP: 00007f310c982d10 R08: 000000000006ebf4 R09: 0000000000000000
[ 242.913141] R10: 00007f310d8a0216 R11: 0000000000000246 R12: 00007f31000425f0
[ 242.924152] R13: 00007f310c9828d0 R14: 0000557bd43a1e30 R15: 00007f3100041730
[ 242.935224] </TASK>
This seems to repeat every 2 mins or so until the end of the log.
So, the enclosure connects fine, then locks up and reconnects. Is there a way for you to stagger the start of your boxes? E.g. start the enclosure about 3 mins before you start the server?