A hand full of sources reached out to ask me if I would check and see if Windows Insider Build 18885 is able to better utilize the 32-core Threadripper 2990WX in the same way that Linux is able to unleash the full performance of that beast.
The short answer is no, it cannot.
If this is news to you, please check out my last video on this:
But it wouldn’t be much of an article if it was just “Nope” and “Why is this taking so long?” without some new information, right?
There is a small performance uplift in 7-zip of up to 9% best case scenario. It seems as though NUMA is still not handled properly though.
Edit: I’ve just learned the small performance bump is because of the ccx-aware scheduler changes to windows. This is GREAT news for all zen owners. Everyone on windows will see some performance uplift from this for any latency sensitive task. Kudos to the AMD and OSV teams respobsible.
Coming up for Level1 is a lengthy refresh guide to VFIO on Windows, and some performance tuning tips.
In that video we showed that mucking about with some internal Windows structures related to scheduling would improve performance of the Indigo rendering program.
We also showed that, clock for clock, Linux with the 2990WX and Epyc CPUs in UMA mode performed about the same (which meant we’re not memory bandwidth limited on Windows). It sure does look like a bug in Windows.
Today I’ve got the final nail in the coffin to demonstrate that – a VFIO Windows Virtual Machine running on a Threadripper 2990WX, under Linux.
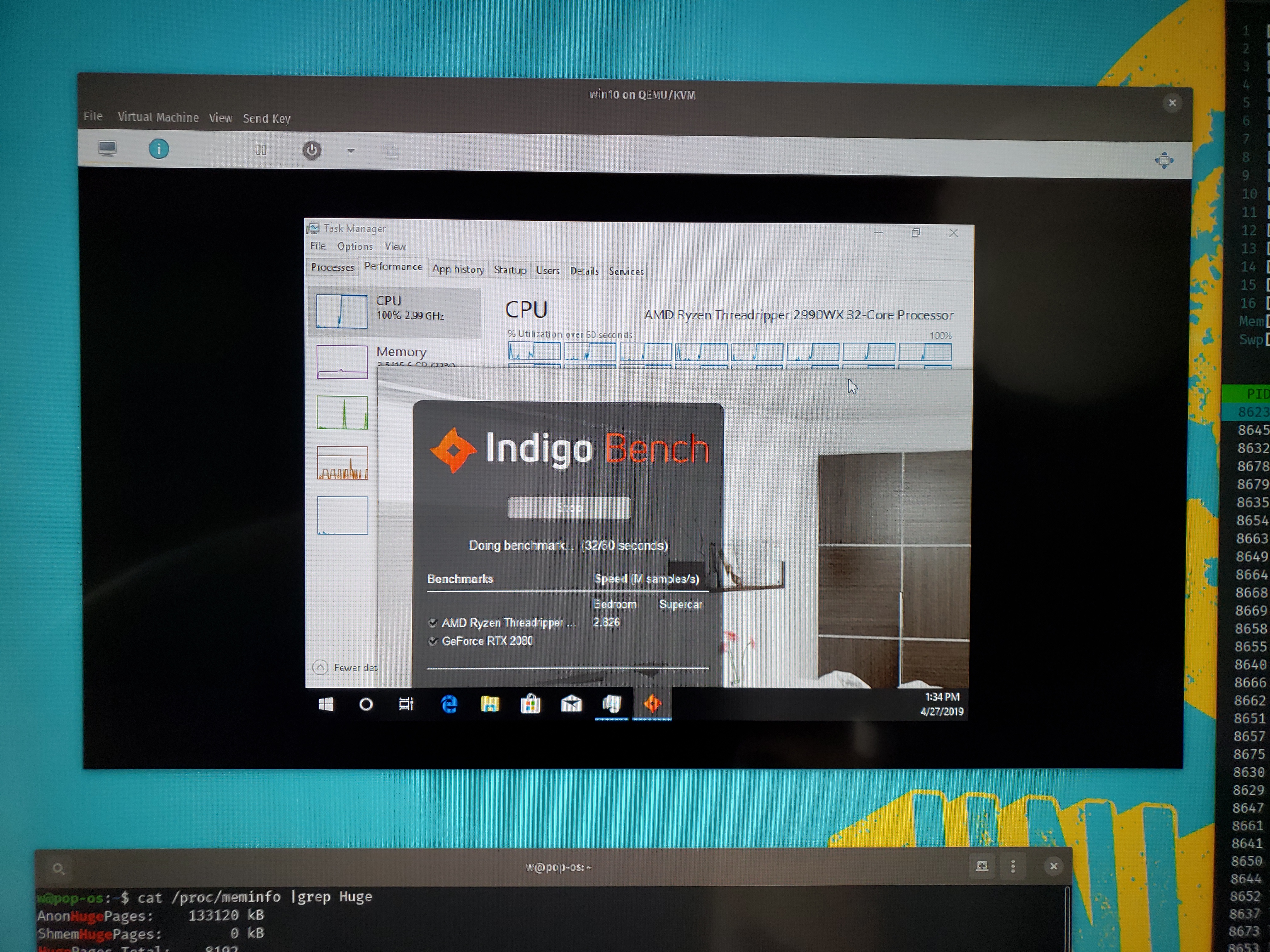
Our test setup is as follows:
System 76 Thelio Major r1
64gb Memory
Gigabyte Designare X399
AMD Threadripper 2990WX
2x Nvidia RTX 2080 (Gigabyte)
2tb Samsung NVMe (host)
1.2tb Intel 750 NVMe (guest)
The setup is pretty simple – create a Windows VM, pass through one of the RTX 2080 (not strictly necessary as this is a CPU test, but we can see about Indigo performance on the graphics card ‘natively’).
The motherboard is configured with 2933 XMP 16-18-18-36 1T timings, but otherwise EDC, PDC, PBO etc are all at AMD defaults (meaning – no CPU overclocking).
On bare metal in Linux, the Indigo renderer will score around a 2.9 to 3.0 (3.1-3.2 with PBO). It scores about a 1.6 on bare metal Windows as reported by The Tech Report, Anandtech and others.
The key baffling thing here is that a score of 1.6 on Windows operating systems represents a regression in performance even over the 16 core Threadripper counterparts.
It doesn’t make a difference if you use Windows Server 2019, use bcdedit to play with sockets/grouping signals to the Windows kernel (or even use Windows 10 Workstaion).
With KVM on Linux and this VM, we have an easy opportunity to emulate CPUs from other vendors (e.g. A Nehalem i7 cpu), control the number of cores & threads passed through from the host and even to alter the topology.
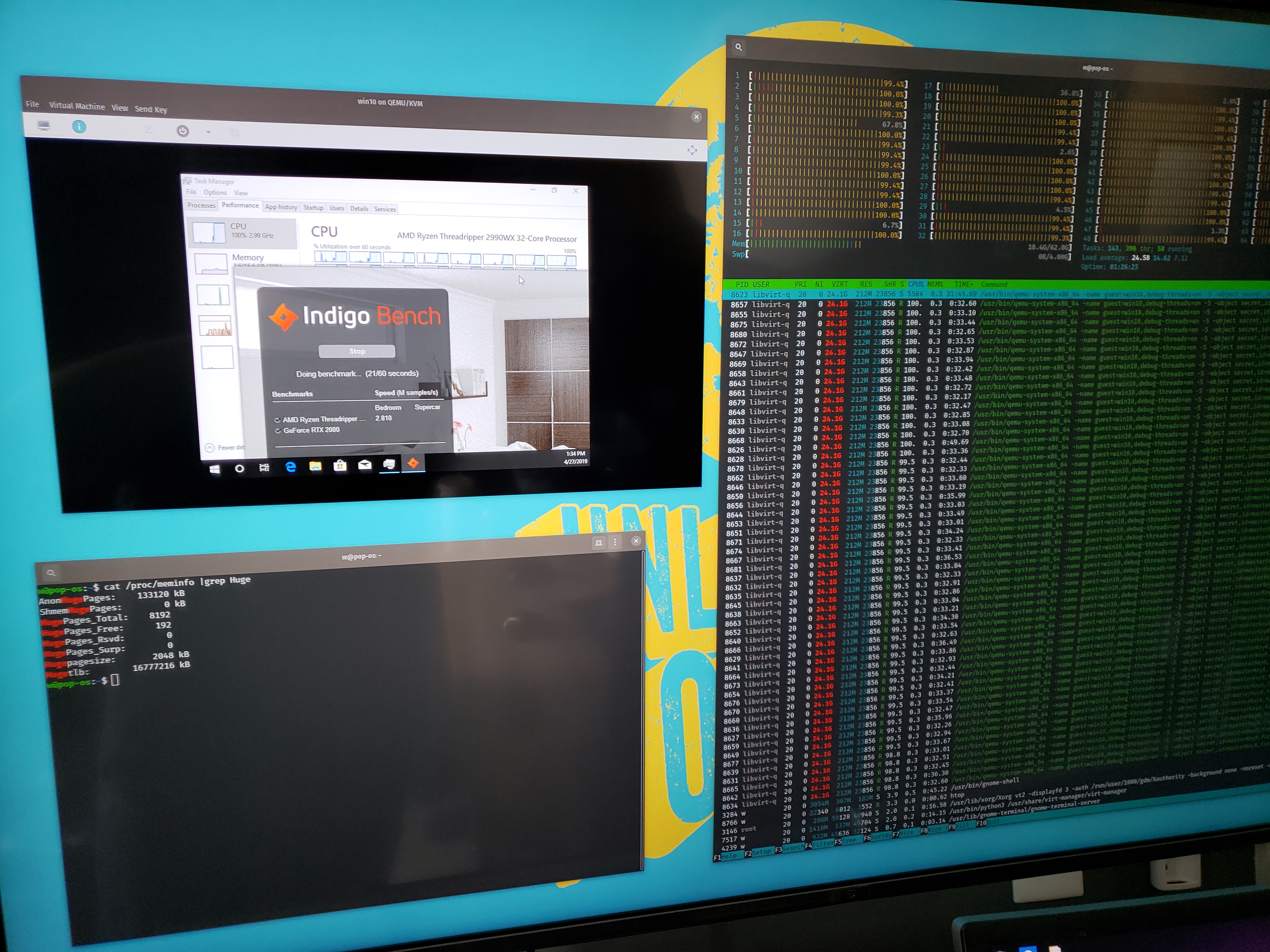
It turns out that, with KVM, if you simply lie to Windows and tell Windows that the 2990WX is one numa node of 32 cores/64 threads, most of the Indigo performance comes back without any special hacks. One can easily score a 2.6 -2.7 (instead of 1.6).
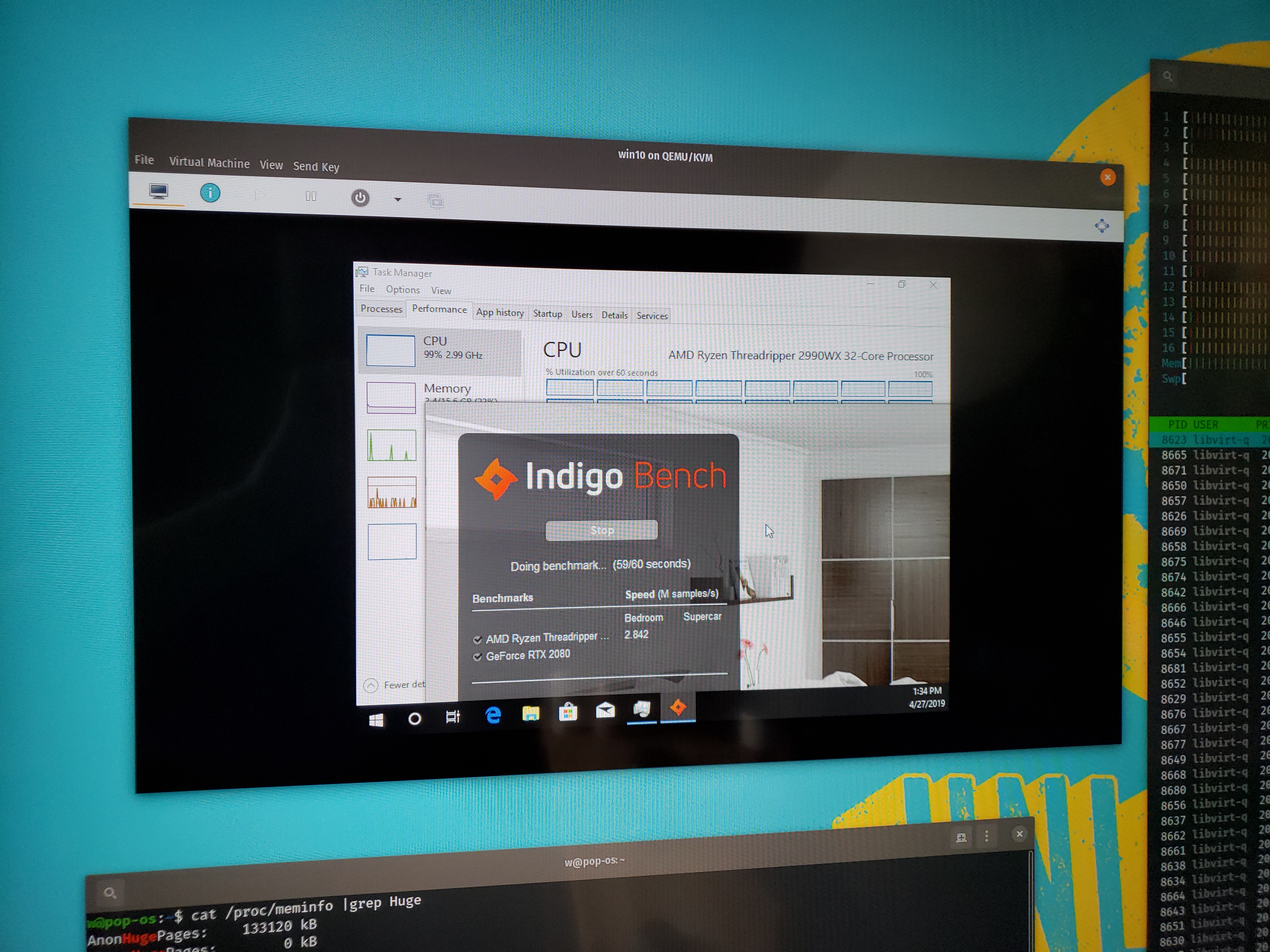
It’s not the best situation, in terms of overhead, to pass through all CPUs from the host to the guest. I found the sweet spot was around 56 threads out of 64 threads with a final Indigo render score of 2.8 +/- .
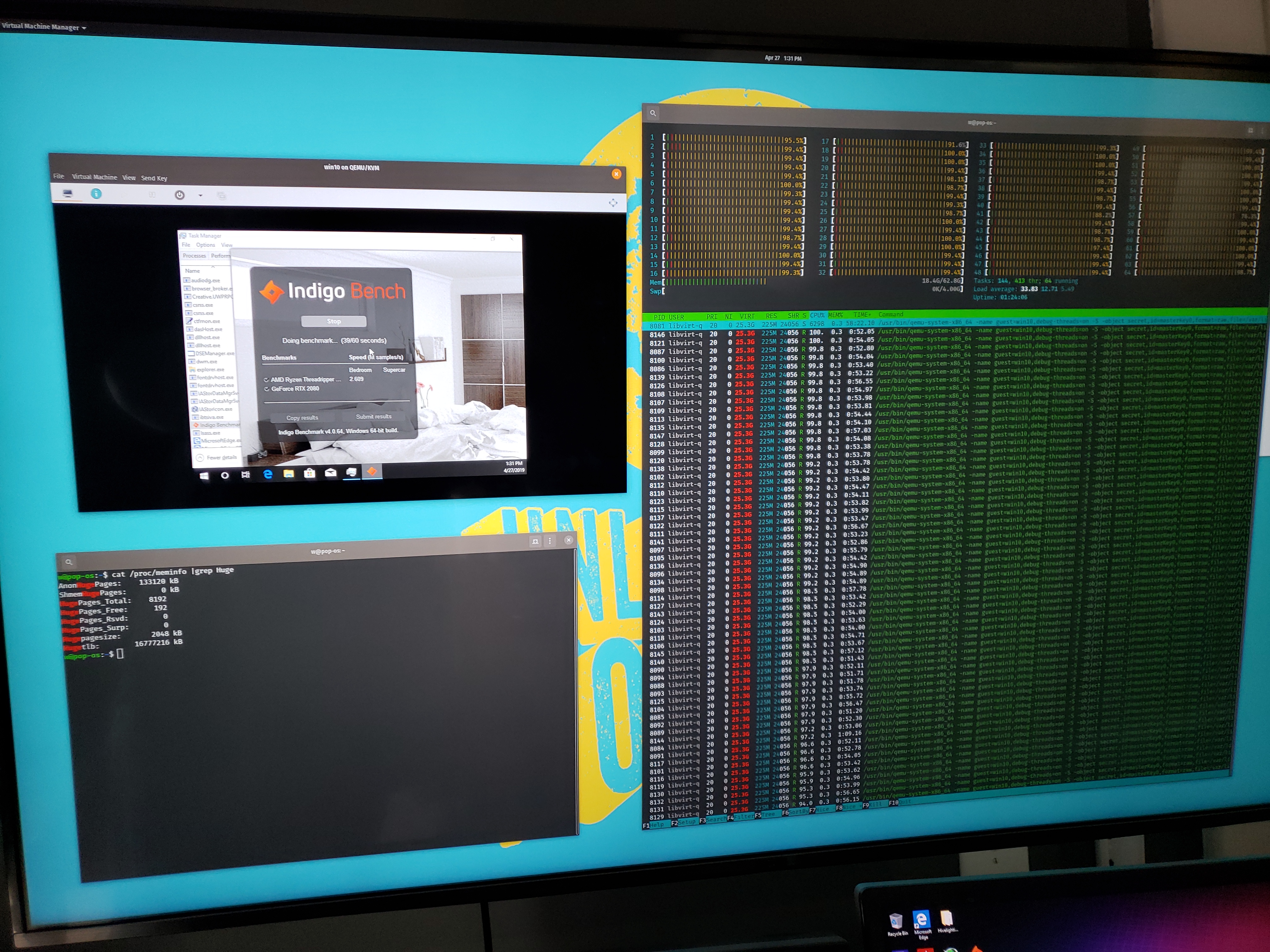
This is 93% of the bare-metal performance in Linux with this one benchmark, and a 175% of the performance of Windows as-is, even Insider build 18885.
I figure about the time Microsoft finally fixes whatever this problem is, it’ll be just in time for Intel to take advantage of the chiplet revolution. The irony is that AMD creating this situation now will absolutely benefit Intel when they get around to doing chiplets themselves.
To be clear, there are downsides to just lying to Windows about the CPU Topology. While it’s useful for diagnostics, it would create more problems than it solves for day to day users.
Most applications are not massively multithreaded and benefit from the lower latency that is available if the process and operating system scheduler are able to locate the process on a CPU that is closest to the memory in which it resides.
~$ numactl -H
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
node 0 size: 32128 MB
node 0 free: 21992 MB
node 1 cpus: 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 0 MB
node 1 free: 0 MB
node 2 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
node 2 size: 32225 MB
node 2 free: 21507 MB
node 3 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
node 3 size: 0 MB
node 3 free: 0 MB
node distances:
node 0 1 2 3
0: 10 16 16 16
1: 16 10 16 16
2: 16 16 10 16
3: 16 16 16 10
The node table here in the output of numactl -H on linux gives the scheduler a hint about which memory is closest to what CPU core.
The Threadripper 2990WX is a little unusual in that there are two nodes here with no direct access to Memory – it must be loaded through other nodes.
Based on my research, it doesn’t seem like bandwidth is the issue here, or even latency for most apps that can use the many threads available on this CPU. It seems as though it’s down to something in the operating system that remains unfixed.
Further Testing
One other configuration that worked well with KVM was a two-node NUMA config where in CPUs 0-31 were assigned to one NUMA node and CPUs 32-63 were assigned to the second NUMA node.
Astute readers might have already recognized that the first NUMA node is the cores that have direct access to memory, while the second NUMA node is the one that does not have direct access to memory.
In the case where we pass through all 64 threads (vs 56) the performance approached the 56 thread configuration.
I am still testing a couple of things here.
TODO – 7zip
In Concluision
I suspect the reason a proper OS fix here has taken so long is because of the complexities involved.
Linux has ‘always’ run on Big Iron and I can think of a few systems from e.g. IBM where they had turned a small cluster of 2-socket hardware nodes into an ‘8-socket’ server via proprietary software and interconnects. It makes sense Linux would have an advantage here, though I would expect Microsoft to be doing better at a low-level especially because of their investment in Azure.
AMD has gone on record as saying the next server CPUs, codename Rome, will be UMA with a centralized on-chip memory controller so perhaps it won’t be too important for Microsoft to fix whatever the problem they have that causes a regression on this hardware.
The 2990WX hardware itself is demonstrably great; it’s just too bad not everyone can have the first class experience with it that I’ve had on Linux.
If you want to repeat my test on your 2990WX – all you need is Pop!_OS, enable HugePages, setup the windows VM to use huge pages, and that’s about it. Experiment with CPU pinning (not much, if any, difference with huge pages) and the various threads/sockets/cores options in KVM.