Hi guys,
as long as i have my Threadripper System i am suffering from unpredictable instabilities on my AORUS Master… Blamed it on me first, then Mint, but no… i dont think so anymore.
I have run Memtest86 and got indeed memory errors (running 4x 16GB 3600MHz 16-16-16-36).
I then switched to stresstesting via prime95 (mprime) and stressapptest -W -s 360
I cant get prime95 stable… even with memory crippled to 2133MHz and the cores at 2.4GHz without XFR and precision boost and giving the core/soc some 50mV additional voltage, there are still cores failing. Those cores which fail, i have taken offline via
echo 0 | sudo tee /sys/devices/system/cpu/cpu8/online
and with all failing cores disabled, stressapptest actually completes successfully.
The thing is still… i mean… come on… 2.4GHz and still unstable?
Can anyone test if prime95 is stable at their system and maybe give me a hint on what to chase for? (MoBo, CPU?)
I am pretty sure the memory is ok, since the instability is unrelated to memory clock and i have tested different permutation of stick-arrangement, tried 2 sticks only and one stick only. still the same problems.
I also have reseated the CPU several times, however i have seen change in affected cores, there is a certain subset of failing cores that is always failing…
The Power Supply is great. When i use the die-temp as equivalent to power draw, i can increase power draw by normal-clocking the processor and disabling the wonky cores. Then the system is stable compared to the down-clocked system with all cores enabled.
I talked to Gigabyte, they said it is likely the CPU, there seems to be a higher rate of problems.
I talked to AMD, they offer RMA.
I talked to my retailer, they offered RMA for CPU and Mobo after they test it.
MAN, IS THAT SYSTEM BROKEN!!
RMA takes time. They all think you buy a 6k$ system because you dont need it… It seems impossible that they send out replacement first, then use the packaging for returning the faulty CPU while i have uninterrupted operation. External testing for weeks is stupid when it just takes 30min to replace the cpu, test and see a difference (or not).
This is a nightmare.
knowing is a very relative term when it comes to him, but basically anyone with an oscilloscope could check their VRMs and see if this phenomenon exists on other boards too. I dont know if the VRM design of the AORUS Master is unique. (I doubt it)
I might be better off just sharing those pictures with Gigabyte-Support.
What bothers me more is that those glitches also happen, if i set the core voltage to constant 1.25V. However it might be a function of the power management to just update the VRM anyway, just always with the constant value. If the glitch is only 130mV deep (little more with noise) I should get my system stable with overvolting it. At 1.25V it is still unstable at 3GHz with the same cores failing each time in Prime95… I try 1.35V next. But i wont go higher. It may be time for a re-seating of the cpu next, but if the affected cores dont change, i am giving up.
Edit: done the 1.35V:
The osciloscope only measures around 1.15-1.2V. Not that an oscilloscope is an accurate measuring device for absolute values, but it is surely not 150mV off. So somehow my 1.35V setting for VCore and SOC doesnt do much.
However it was more stable. The glitch was still there but only 30mV or so. But as the CPU got hotter, the glitch grew to the original size, and BAM, stopped workers in Prime95.
I would think the MoBo is simply unreliable. Not sure what causes such behavior however. It seem everything else is working fine. Maybe its an early adopter thing, i basically bought it, when it came out. Might have been a mistake. Running the newest Bios does not fix it.
Hi, as an electrical engineer, i do have my thought on the matter, but i think before i start soldering around the motherboard and voiding warranty, this should be a warranty case first.
To answer your questions:
PSU: no. The PSU does not act in such short time periods. If the PSU fails or is insufficient you would see much deeper and longer drops, as a PSU is a very slow thing.
Cap in PSU: there are many paralleled inside the PSU, so if one fails, you get higher ripple on the 12V line but that does not lead immediately to a failure. Only if all caps die, there would be such a phenomenon. But this is highly unlikely.
defective coil: generally a very unlikely scenario. (except bad soldering)
defective transistor: possibly although i dont think the silicon is defective (because power transistors usually short out) but it may be a soldering defect. I however dont see, hoe in a 16-Phase system a defective stage can ruin it all.
What I think:
I have done a FFT on my oscilloscope of V_core. I found it disturbing to see there is a significant portion of ripple voltage at 500kHz. From my experience, a VRM going from 12->1V should switch from 150kHz to 300kHz per phase. Seeing a 500kHz ripple in the output means that somehow something is wrong, since the combined phases should end up in the MHz-Range if everything works and not 500kHz. This hints to broken load sharing across phases or inactive phases (despite setting the VRM to extreme performance mode in bios, so all phases should be switching independent of load)
The fact that all phases seem to stop switching at once is either an over current condition or a feedback glitch (like sensing over voltage which is not there)
Unfortunately i cant probe the switching side of the VRMs because it is hidden under a heatsink. So i cant test any hypothesis. Lets wait for a response from Gigabyte. They say may take 3-5 business days. WTF.
Actually, as you may know, the VRM phases operate sequentially. Each provides all the current for a short while, then “rests” while the others take up the load one at a time. (Sometimes 2 or 3 FET-choke stages are wired to a single phase, but the principle is the same.) And 500 kHz is a credible frequency for switching from phase to phase, near enough to the 150-300 kHz you mention.
Makes me wonder whether a single faulty FET-choke stage might produce the waveform you are observing. No current for a moment during which voltage drops sharply, then the next phase takes up the load. Regular as clockwork.
You might look at the Vcore at idle, or under differing loads. If it’s this sort of problem, a similar pattern ought to be present - though the voltage wouldn’t drop as steeply with a lighter load.
P.S. Kudos for collecting & sharing solid data - the oscilloscope photos are very helpful.
Hmmm… I realized that it isn’t clear to me whether 150 - 500 kHz is the frequency at which a particular phase / FET is switched, or whether it is the master phase clock which would be divided by the number of phases. For my earlier suggestion to be correct, it would have to be the first case.
Ah-ha! The figure “PWM-Double Signal” at this site WikiChip Voltage Regulator Module
shows an example with each of 12 phases switching at 150 kHz (divided from 300 kHz) although frequency isn’t the focus of the discussion.
That is very much a power delivery problem. That level of droop should never occur. I would have suggested a BIOS flash, but you’ve tried that. The only other thing to try would be differences in LLC settings to mitigate the ridiculous transients, but I would have sent the mobo back as soon as I saw your linked oscilloscope readings. Nothing you can do will make that manageable.
Thx nurdygurl for the backup. I have contacted Gigabyte, lets see how the customer service is. I just hope they send out before i have to send in. The standard procedure is really the most f.dup s.t that can happen to a higher end work station. Cant have the downtime.
Caped_Kibitzer, your description of a multiphase converter is a bit off, i dont think you have fully understood how it works
The phases (may some be paralleled or not) are not operating sequentially so that any single stage has to carry the full current. They in fact operate interleaved (phase shifted). In such a stepdown converter, the coil-current does not go to zero in any inductor at any time - before that happens, phases are shut down preferably.
Unfortunately the Link/Resource you posted is some utter BS. For example their voltage curves in https://en.wikichip.org/w/images/5/52/vrm_circut_with_switching_(multi-phase)_output_overlay.svg are totally stupid I mean, the output voltage of every phase is shorted together. It is impossible to draw individual voltage curves and how the combined voltage is then suddenly just the maximum of all of the voltage is just hilarious. That does not happen.
If you really want to learn about that stuff, I suggest you read datasheets of multiphase converters ICs. They usually contain a Theory of Operation paragraph. Those are credible sources. And never think after, for example, a Actual Hardcore Overclocking video, that you learned something correct, just because it make sense to you at the time. As an electrical engineer (having also built multiphase converters myself), trust me, it is pure cringe.
I suggest real engineering literature about that stuff like: http://www.ti.com/lit/an/slva882a/slva882a.pdf
If you dont understand everything, that is totally fine! The important thing is, that you know that you dont understand it, instead of thinking something is understood but it is actually wrong The more you read the same type of documents, the more they make sense over time.
I just remembered something, so years ago on some haswell cpu, I was having similar problems. I was using liquid metal and a delided cpu. After throughly cleaning the board and cpu, then using regular thremal paste, the problem went away. The liquid metal was shorting something.
moral of the story: check for shorts?
Edit: oh and sorry about you threadripper, but thanks for posting it was a nice read.
I am back. I just had a very frustrating WTF-Moment.
Short story short: i bought a new Motherboard, nice i got no support from the suppliers except giving up my pc for a month or two. Thats no option.
Now, switched motherboards: same problem as before. Same Vcore-glitch and the same cores failing first in prime95 and stessapptest.
So basically it comes down to:
a) The CPU shorting out Vcore every 4ms and it needs to be replaced
b) The Gigabyte Aorus Master TRX40 has a general problem, since two boards failed here.
Man that is torture! Specially with no support from AMD or Gigabyte… they just refer to to their resellers. “Sure, dear customer, diagnose it yourself. We can take your spare 3000€, buy new CPU+MoBo and just try stuff in vain; Or hey, give us your PC; we take it for an undetermined length of time, but it is for sure measured in months. Your choice of course”
Man am I pissed.
Oh: regarding the gigabyte support: imcompetent trolls. There is no useful conversation with them. Basically to solve the µs-glitch they proposed to play with the Load line calibration. All while having access to the oscilloscope pictures and seeing damn well, that the regulator response is slower than the glitch. I just gave up, gave 0 starts. not worth the time. No real technicians there who actually know anything in detail.
What now? Order a spare 3970x ? Guess so…
Oho ooohhhho hooo… !!! Just a thought: if it is a dead cpu short-circuiting Vcore, then my power draw must be higher in Idle, right? (even if the glitch is not that deep in idle)
My system draws 200W from the wall doing nothing. Just saying. Is that normal for the 3970x?
Don’t have experience with the 3970x, but that seems really high for a system on idle.
What’s your full spec list? Are HDD’s plugged in? GPU?
To get the best measurement, use a current-clamp (you likely have access to one) and tell us what you get on your 12v CPU rail. Try it in the bios and booted into an O.S.
Regarding your mention of measuring the VRM output, why can’t you remove the heatsink from the VRM’s? Also, have you tried measuring the voltage stability of the DIMM power rails? Also I guess you tried varying memory configuration in different slots as well (even if they aren’t configured optimally)? I know it seems like it may be a CPU issue, but it could also be a DIMM issue.
Full spec is: 3970x, 5700XT, Aorus Mater TRX40, 64GB 3600CL16 (4 sticks), 4x 2TB (ssd) @ SATA, 2x 1GB @ NVME, some fans + a pump. 850W Power supply, full load is 600W-700W. (So there is actually room for graphics card)
I unfortunately do not have a dc current clamp. However i measured the 12V rail voltage-vise and they are rock solid as are all the other rails. Power supply is fine. (I understand, you wanted me to measure cpu power draw, but I cant, so I answer this instead )
Removing the Heatsink of the VRMs seems sketchy. I know its possible, but i also so not want to void warranty more than necessary. Also measuring on a live stupidly expensive system does not feel good. I havent the right setup here to so a professional job.
The voltasge stability of the other rails (those that have measurement points) are all fine. It is only Vcore.
Bios is updated.
disabling CPU-Cores helps, but it only lessens the chance. I ran a while with 8 cores (via bios), it still happens. Also i can disable all cores in Linux that fail in stressapptest or prime, but when i run the test again, other cores just fail. I see on the oscilloscope that the depth of the glitch is load dependend. This is why disabling cores helps.
This behavior is the same on both motherboards i now own.
The Vcore glitch happens like clockwork every 4ms. It is not related to VID-changes.
I disabled C6 via zenstates.py. No change under load.
i also tried different memory speeds. The glitches also happen when Memory is at stock 2133MHz.
I also removed and/or shuffled memory sticks around. No Change.Memory is fine, when Mem-Testing it is the CPU that fails the comparison or hash/crc computation, (stessapptest retests a failed memory segment, and retesting is often successful)
I also exchanged my 5700XT with a 1080, although the system ran more stable, the glitches on Vcore are still present.
The CPU is the only thing left to change.
To me, it makes no sense. at all.
It would be a tremendous help, if anyone could hook up an oscilloscope to their Threadripper3000 system. As far as i know, Gigabyte uses the same VRM on many boards. If the glitch is part of normal operation, then i have another problem. But not knowing what to expect on Vcore is what holds me back from buying another 3970X. It is no fun to spend 2000€ on a guess.
Have you tried changing the VRM settings in the UEFI? The controller can probably do things like dynamic switching frequency, phase shedding, etc. to save power. But if thats buggy you might get more stability with all phases active all the time at a fixed switching frequency.
Have tried it, does not help at all.
I dont expect that anything helps anymore either. If two boards behave the same, that would mean that there would be a systematic problem with the VRM. AFAK the VRM design is shared across multiple models. I think they would have addressed that by now. This is nothing that can be solved by BIOS-settings or all Gigabyte-TRX40-boards would be unstable out of the box.

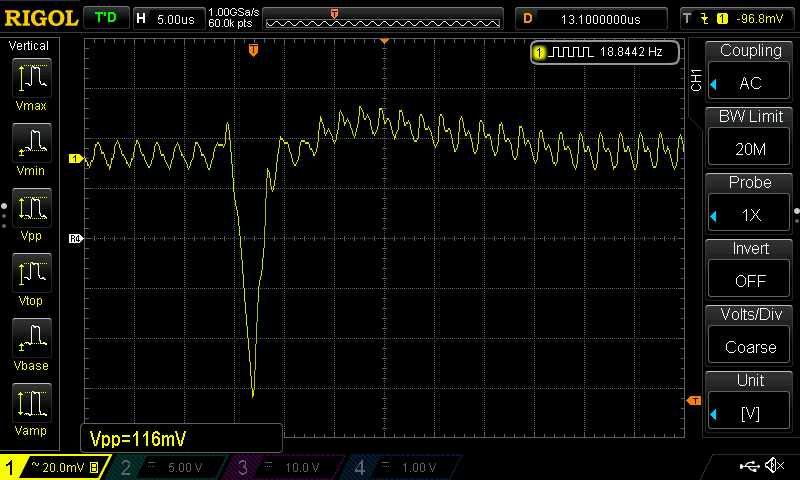
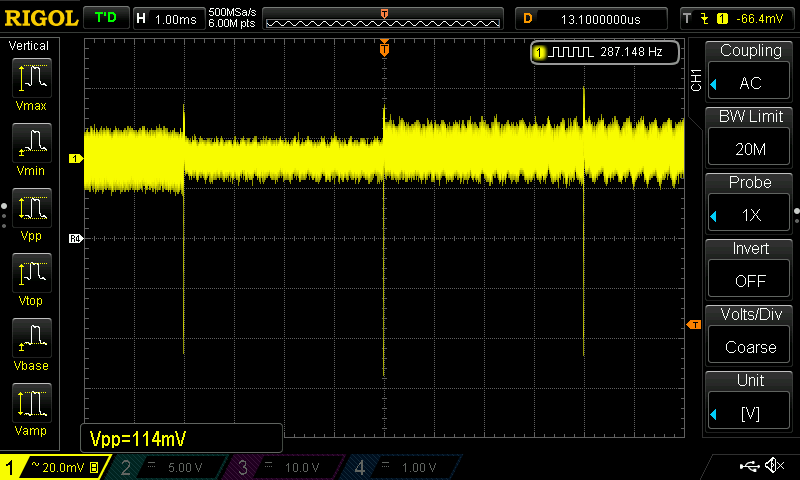
 knowing is a very relative term when it comes to him, but basically anyone with an oscilloscope could check their VRMs and see if this phenomenon exists on other boards too. I dont know if the VRM design of the AORUS Master is unique. (I doubt it)
knowing is a very relative term when it comes to him, but basically anyone with an oscilloscope could check their VRMs and see if this phenomenon exists on other boards too. I dont know if the VRM design of the AORUS Master is unique. (I doubt it)

{kind=link}