Hi, i have not read the post (in detail) yet, but this is getting very interesting. Last night (night for me) I had a session with Wendell who was kind enough to spend time with me probing his board, testing Prime95 and so on. He does not have issues.
However i am willing to share another screenshot with you of my oscilloscope findings:
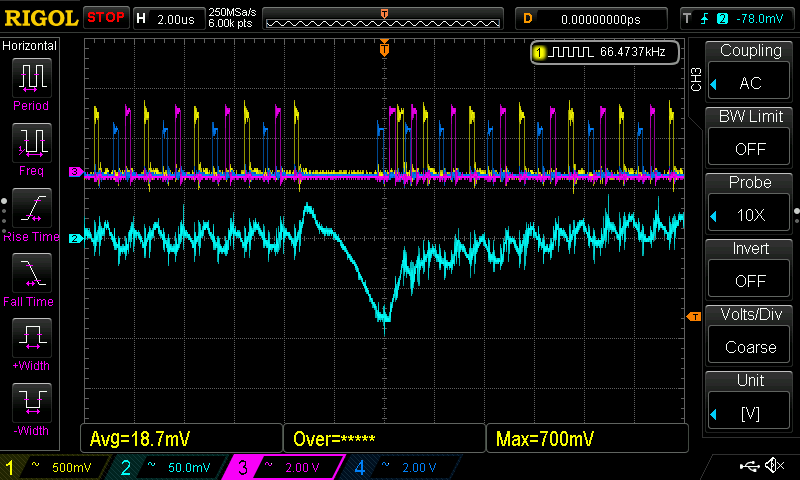
What you see is the voltage Vcore-dip on the bottom. On top i probed 3 of the 16 phases. Here, only the waveform counts, the way i probed to phases does not give me correct absolute values. View it just as indication of what happens!
THE VRM IS INDEED MISSING A CYCLE.
And its worse: it is not only a missing cycle due to a protective feature. I can distiguish this, because the low-side mosfet of the stepdown is turned intentionally ON by the multiphase-controller causing the dip. All phases at once. The CPU does not have a chance.
Now, i have had 2 boards with the exact same issue.
I have to change the CPU first to really double check that it is not the CPU, but it makes absolutely no sense that the CPU would cause that issue. PMBus-Communication is far to slow to misconfigure the VRM for only one cylce.
My current guess is that the XDPE132G5C has some sort of configuration issue (which can be fixed by bios update) or it is actually a hardware fault inside the chips - as if there is a bad badge or something from Infineon.
PLEASE tell me that Franz is a German name? Where do you live? Send PM.
In your post people suggest it is a Vdrop issue. Trust me, the boards copper layout is solid. Those boards do NOT generate excessive drop with huge variations (meaning the Load line calibration in bios stock settings should be fine). If someone hints at a drop, i honestly think it is the VRM fucking up. We need more oscilloscopes among the people.
It is very unfortunate that Gigabyte is not taking me serious. I have no power to get through to someone where a technical discussion about intricate details about the VRM is actually fruitful.
 Franz is how most people call me, in part because I lived many years in Germany (Berlin), in part because it’s much easier for everyone to spell my name (my actual name is François: no weird
Franz is how most people call me, in part because I lived many years in Germany (Berlin), in part because it’s much easier for everyone to spell my name (my actual name is François: no weird 
 yeah, right.
yeah, right.