Hi,
I’m having a lot of issue with a pretty new PC under linux
It look like it work OK under windows, but to be fair i so rarely use it it also could be random luke.
So i have a Ryzen 9 5900X, on a ASRock X570 Taichi Razer Edition.
I run Fedora 37, but this as never been stable
randomly, the computer will freeze, power off and reboot.
I could be on discord, youtube or playing a game, never really the same thing.
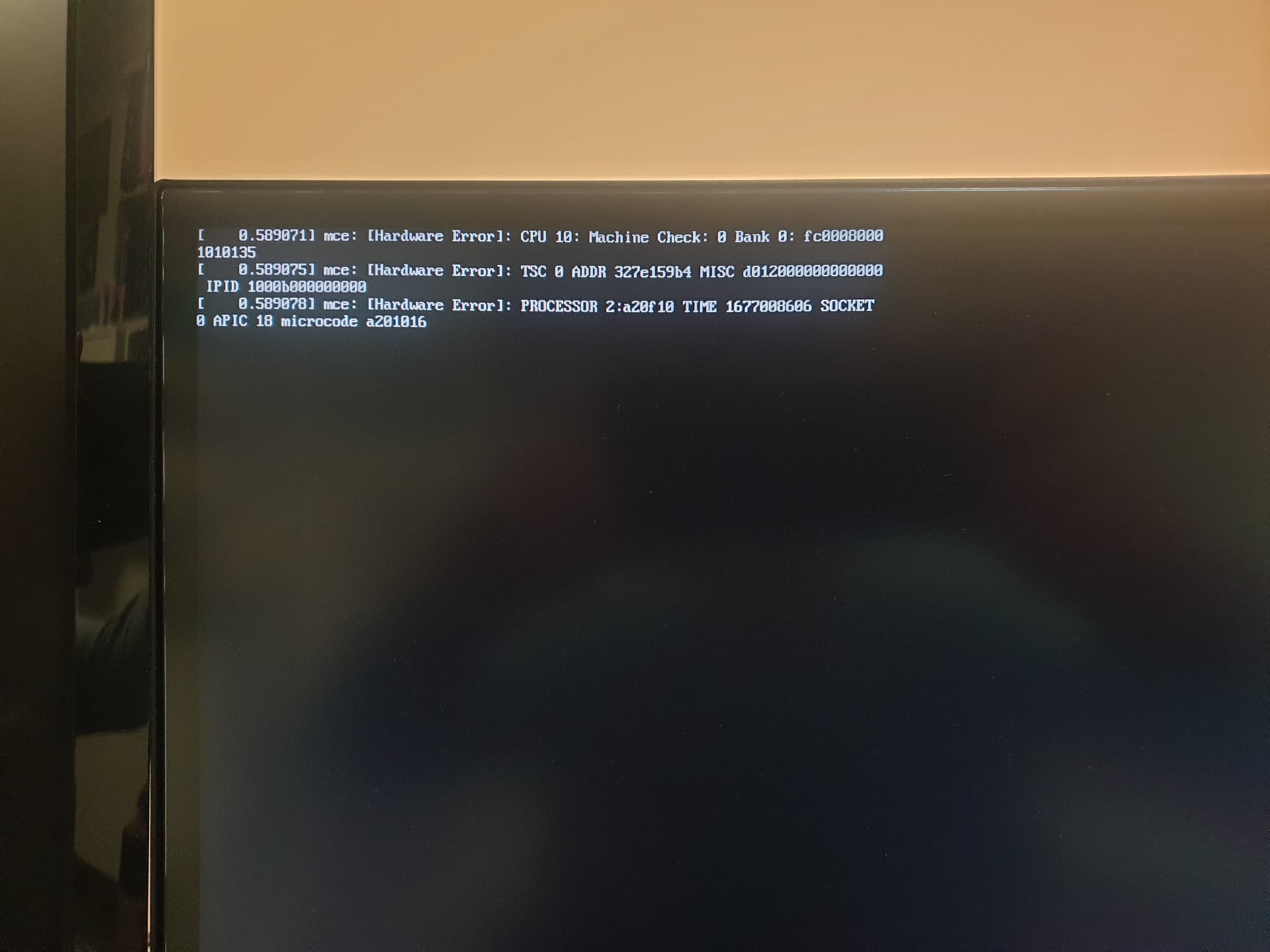
At the reboot i get a message who say
The kernel log indicates that hardware errors were detected.
It recommend the use of mcelog to have info about it, but it is installed and refuse to start, asking for a kernel module already loaded
➜ ~ sudo mcelog start
mcelog: ERROR: AMD Processor family 25: mcelog does not support this processor. Please use the edac_mce_amd module instead.
CPU is unsupported
➜ ~ sudo lsmod | grep amd
edac_mce_amd 57344 0
kvm_amd 172032 0
kvm 1126400 1 kvm_amd
amdgpu 10661888 11
drm_ttm_helper 16384 1 amdgpu
ttm 94208 2 amdgpu,drm_ttm_helper
iommu_v2 24576 1 amdgpu
video 65536 1 amdgpu
gpu_sched 49152 1 amdgpu
drm_buddy 20480 1 amdgpu
ccp 122880 1 kvm_amd
drm_display_helper 208896 1 amdgpu
To me, first thing seam to be able to get this running, but i’m open to more option
First theory is insufficient cooling. In case you have not yet, I recommend installing the sensors package.
sudo dnf install lm_sensors
There are a bunch of tools that help with graphical display of sensor data, I mostly use the terminal like so
watch -n1 sensors
Look for temperature sensors starting with CPU temperatures, also motherboard, chipset sensors.
I had lockups from overheating nvme sticks as well in the past.
kinda ? i don’t have the cable lengh to do it i’ll have to disasemble everything.
My current power supply is a seasonic prime 1000W… i would trust if especially since the cut don’t happens only on triple A, not on VR game under windows.
Your 5900X’s L2 cache was corrupted when your system rebooted/crashed. This is very rare hardware issue IF you were running your system everything as default or recommended by AMD. If that’s the case, I suggest you do a RMA on your 5900x because AMD does sell marginal quality silicons from time to time.
However, I suspect more likely it was caused by overclock (either by you or someone else in your chain list of component suppliers). If you OC by yourself, you’re pretty much on your own. AMD officially doesn’t offer warranty once PBO/etc are turned on.
hi !
May i ask you what make you think that ? I’m still lacking any log of the actual issue since i can’t get mcelog to work
PBO was enabled (but left as it) by the company who sold me the cpu and the board because the Bord was an open box and they couldn’t ship the ram until after the 15 day warranty expired on it, So i had them test it with there own ram.
The hardware error was shown in your previous post:
If you check Windows’ event log, you may find equivalent errors in Microsoft speak. Something like WHEA xxx which might give you a more human readable interpretation. Not very sure about this since these days I spent little time in Windows as an OS.
I suggest you restore BIOS to default without O/C. If problem persist, then exchange or refund the CPU/MB combo.
After more than a week, i can’t reproduce this issue under windows while it’s very regular under linux …
Not having linux log nor windows event log mean i have no way to contact support about it
mce/mcelog https://mcelog.org/ indicates that your processor is bad, specifically the cache on it. you might try updating/downgrading the bios and see if a different version doesn’t show that error. or you might need a new processor.
the ADDR field is the failing address but you’d need to know the bank organisation, interleave settings and channel layout to determine which module/chip.
The earlier message from Feb 8 had a status of bc80 0800 060c 0859 - that’s a BUS_ERROR, i have no idea what would cause that. I’d try to find a stress test that can reproduce it as reliably/quickly as possible. Try prime95/mprime stress tests. Then try things like reseating the CPU, single memory module, reduce memory timing.
If you have ECC memory, make sure ECC mode is enabled and if it is a memory timing/stablility issue you should see ECC corrections happening.