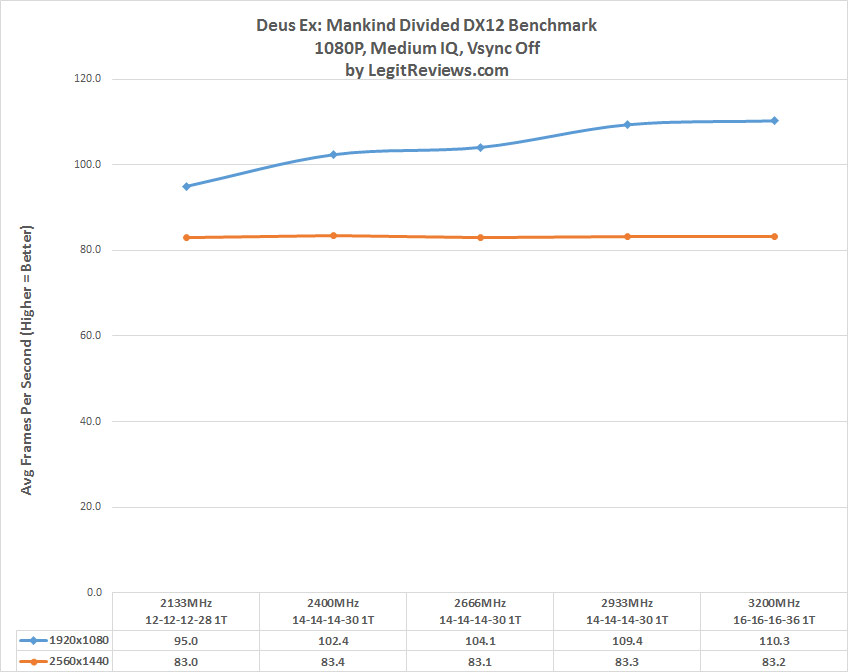
The clock for the Infinity Fabric, aka the Data Fabric connecting the two CCX and everything else, runs at half the effective RAM clock. Faster RAM = Faster communication between CCX:es and pretty much everything else. Problem is that even 3200 MHz RAM seems to be a bit of a challenge do get working well on Ryzen. This might have to do with clocking the IF too high, but I don't know. We'll see down the line. Maybe AMD will give us a separate multiplier for the Fabric, it could be possible, but could also not be. AMD has been very silent on the specifics of the Data Fabric they call Infinity Fabric. It is proprietary and secret.
There was a leaked slide on hardware.fr:
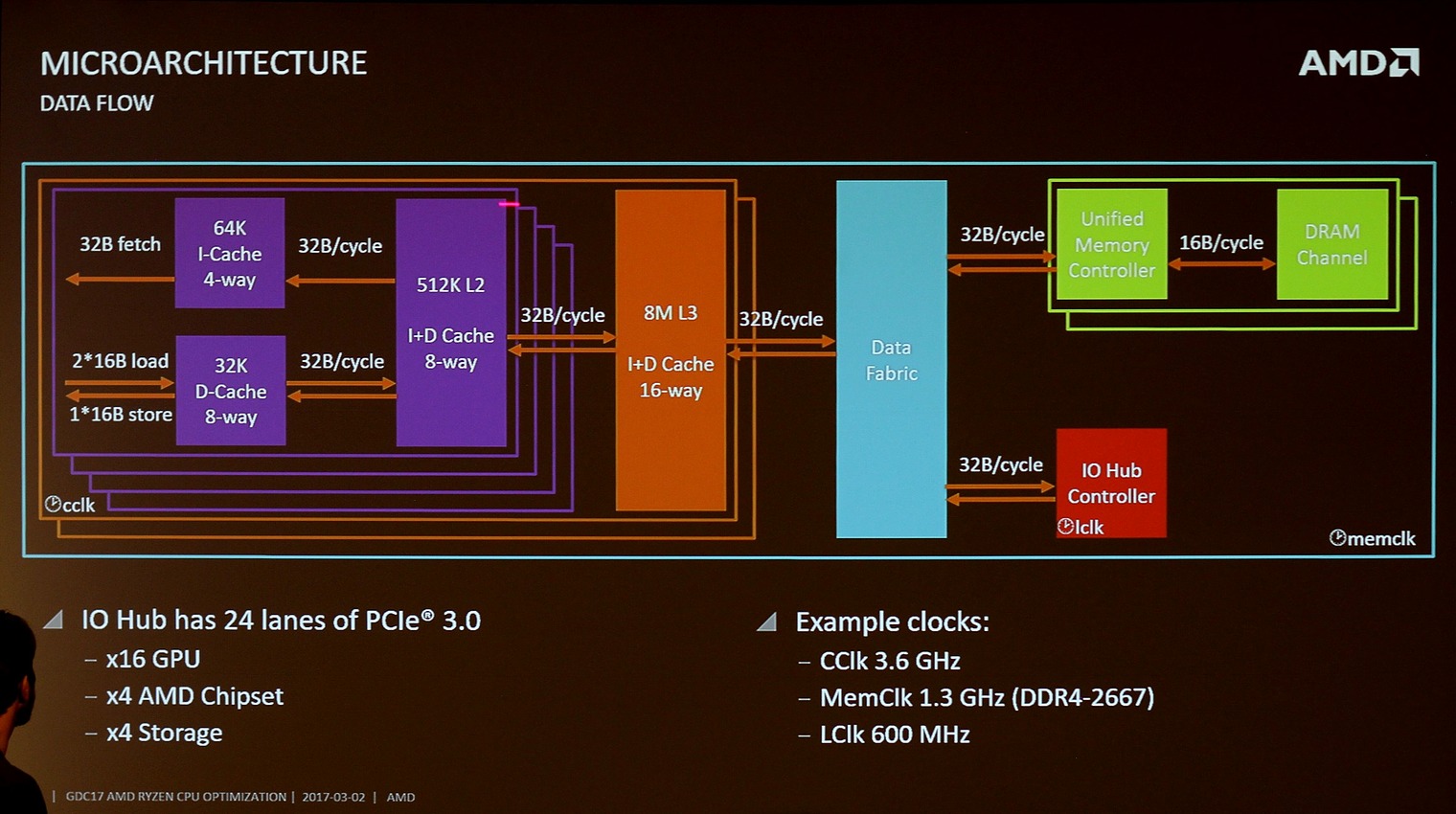
The Fabric operates on half the effective mem clock (2400 RAM would mean 1200 MHz). I've seen this info on other places as well, but as I said, seekreet. Hardware.fr also state that AMD told them the bandwidth between the CCX:es was 22 GB/s. Some have taken this as proof that the Data Fabric is only 22 GB/s. That is not necessarily the case though. It could mean you get that one way bandwidth on the lowest std JDEC DDR4 speed, i.e. 1600MHz. Most analysis I've seen think the Fabric operates on full duplex, seems plausible from that slide. We also have from that slide the figure of 32B/cycle. Say you have 2400MHz ram that would mean 32B * 1200 MHz or about 38 GB/s (there is probably overhead). This will then be used for inter CCX traffic, all Memory traffic and IO.
Charlie over att Semiaccurate had an early article on IF:
On the surface it sounds like AMD has a new fabric to replace Hypertransport but that isn’t quite accurate. Infinity Fabric is not a single thing, it is a collection of busses, protocols, controllers, and all the rest of the bits. Infinity Fabric (IF) is based on Coherent Hypertransport “plus enhancements”, at a briefing one engineer referred to it as Hypertransport+ more than once. Think of CHT+ as the protocol that IF talks as a start.
He goes on talking about how IF is split between Control and Data, controls power management, security, reset/initialization, and test functions. It is probably fairly low bandwidth but also low latency. And if it is scaleable, the bandwidth can be scaled up. Latency will be important for Naples, IF connecting the sockets for cache coherency etc. AMD has also said that IF will be in GPUs like Vega.
Also we don't know if IF is point to point, ring bus or something else. It looks like Vega is using a mesh topology for IF, for example. AMD seems proud of the granularity and the scalability. Vega could have, say thousands of IF controllers on chip for that granularity.
It could be the case that Ryzen has Infinity Fabric-light or something. Full blown thing will be in Napels though, so I'm eagerly waiting for that to release to get more details.