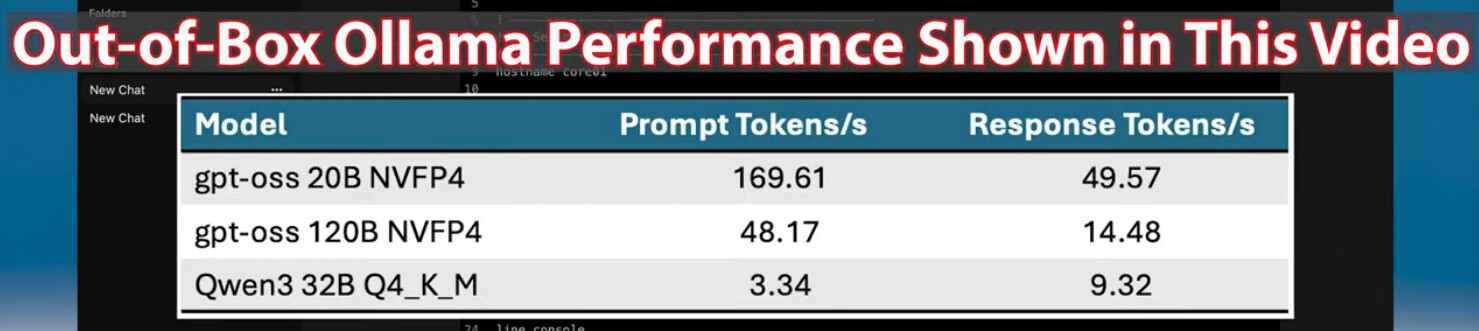
Check Out the Video

The Bottom Line
The DGX Spark represents NVIDIA’s latest experiment in making an “AI lab in a box.” While its marketing headline boasts one petaflop of FP4 compute I was only able to achieve that in 500ms bursts due to bottlenecks like memory bandwidth (haha).
The real story is the platform’s design philosophy, “AI in a box” rather than raw inference throughput.
This system isn’t built to win single-model benchmark contests, and that’s okay. The hardware and software stack are already heavily optimized, and yet some bottlenecks remain when compared to dedicated inference hardware. The real magic lies in its NVFP4 precision format, a novel 4-bit floating-point representation developed specifically for NVIDIA’s next-generation inference pipeline. There’s even an academic paper dedicated to it (arxiv.org/abs/2509.25149). When models are trained or fine-tuned directly for NVFP4, the performance is nothing short of stellar—unique, even—but otherwise, traditional model inference performance is relatively modest.
What DGX Spark does excel at is being a complete agentic AI sandbox. It’s a self-contained environment where developers can orchestrate the full modern AI stack—model serving, retrieval, reasoning, coordination, and deployment—all running locally across multiple containers. Its vast memory capacity makes it possible to run several distinct AI models at once, each handling a part of a larger agentic workflow. If you’ve been out of the loop on “the AI thing” and need to catch up quickly, basically everything is here. One can quickly onboard into the Nvidia ecosystem and one will generally find that anything built or learned here will scale up to the cloud.
I have no doubt that this device will be subsumed into AI and CS educational programs the world over and that will drive many generations of future AI scientists. It is too easy with this platform to get up and running quickly in just about every corner of everything exciting going on with AI today.
Networking is another standout: dual 100 Gb ConnectX-7 NICs make it ideal for distributed training experiments, NCCL tuning, and RDMA-enabled cluster interconnects. Everything you learn scaling workloads to multiple boxes here translates directly to NVIDIA’s higher-tier GB300 systems.
In short, DGX Spark isn’t a product you benchmark—it’s one you build with. Sure I would have loved to see at least 2x inferencing performance, but NVFP4 gets close. Spark is, through and through, a modern and complete AI development instrument designed to help engineers understand and experiment with the connective tissue between models, containers, and data systems that define the next phase of AI computing.
Pros and Cons
| Pros | Cons |
|---|---|
| NVFP4 precision delivers exceptional inference performance for NVIDIA-optimized models | Inference performance for non-NVFP4 models is relatively weak |
| Complete “AI lab in a box” — ideal for learning, development, and experimentation | Some thermal and bandwidth bottlenecks limit sustained performance |
| Excellent memory capacity enables multi-model and agentic workflows | Cost is High |
| Dual 100 Gb ConnectX-7 networking supports high-speed NCCL and RDMA workloads | 3rd party kernel optimizations needed |
| Exceptionally well-organized documentation and examples | |
| GB10 “works the same” as GB300 |
Tell me more about NVFP4
[2509.25149] Pretraining Large Language Models with NVFP4
In this study, we introduce a novel approach for stable and accurate training of large language models (LLMs) using the NVFP4 format. Our method integrates Random Hadamard transforms (RHT) to bound block-level outliers, employs a two-dimensional quantization scheme for consistent representations across both the forward and backward passes, utilizes stochastic rounding for unbiased gradient estimation, and incorporates selective high-precision layers. We validate our approach by training a 12-billion-parameter model on 10 trillion tokens – the longest publicly documented training run in 4-bit precision to date. Our results show that the model trained with our NVFP4-based pretraining technique achieves training loss and downstream task accuracies comparable to an FP8 baseline. These findings highlight that NVFP4, when combined with our training approach, represents a major step forward in narrow-precision LLM training algorithms.
Check out the NVFP4 optimized models on hugging face:
GB10 device query

FP4, and especially NVFP4 best-case-scenario performance
| Model | Precision | Backend | TTFT (ms) | E2E Throughput (tokens/sec) |
|---|---|---|---|---|
| Llama 3.3 70B-Instruct | NVFP4 | TRT-LLM | 195.06 | 5.39 |
| Qwen3 14B | NVFP4 | TRT-LLM | 51.99 | 22.59 |
| GPT-OSS-20B | MXFP4 | llama.cpp | 608.3 | 51.9 |
| GPT-OSS-120B | MXFP4 | llama.cpp | 1594.20 | 27.50 |
| Llama 3.1 8B | NVFP4 | TRT-LLM | 32.86 | 39.01 |
| Qwen2.5-VL-7B-Instruct | NVFP4 | TRT-LLM | 366.48 | 38.08 |
| Qwen3 235B (only on dual DGX Spark) | NVFP4 | TRT-LLM | 87.23 | 11.73 |
| Llama-3.1-405B-Instruct (only on dual DGX Spark) | INT4 | vLLM | 733.75 | 1.76 |
FP8 and bfloat16 Performance
Competitors - AI MAX 395+
AMD’s Ryzen AI MAX 395+ can absolutely be faster in some FP8 and bfloat16 inference workloads—when the software stack is fully optimized. On paper, its peak throughput in mixed-precision math looks competitive, except with NVIDIA’s NVFP4 path, and well-tuned Vulkan or DirectML inference pipelines can push it. But the similarities stop there.
The Strix Halo platform is an APU, not a discrete accelerator. Its integrated RDNA 3.5 compute units share memory and bandwidth with the CPU, which changes everything about how workloads scale. It’s fundamentally a graphics-class RDNA implementation, not a compute-class one, and certainly not CDNA—AMD’s datacenter architecture. While CDNA parts like the MI300 expose mature ROCm, HIP, and RCCL stacks for high-performance compute and distributed training, Strix Halo does not.
In fact, HIP support on this APU has been inconsistent at best. Ironically, Vulkan backends often outperform HIP on Strix Halo simply because the graphics driver path is better optimized and more stable. This means developers trying to prototype agentic or distributed AI workloads on the Ryzen AI MAX will find themselves in a dead-end ecosystem: the performance may be decent locally, but the code, configuration, and tuning knowledge don’t translate to AMD’s CDNA or ROCm-based servers.
So while Ryzen AI MAX 395+ can flash impressive FP8 numbers, it’s a different lineage entirely—a fast APU, not a scalable compute node. Or, as the saying goes, you can’t get there from here. Networking/RCCL? Not there yet. I’d love to see AMD’s Pollara on Strix Halo!
Look at this: DGX Spark | Try NVIDIA NIM APIs – look how polished that is. Now, imagine AMD building that where you start on Strix Halo but you end up at MI300/CDNA… not everything really translates. It’s getting better, but it’s still a problem. A relatively small number of enthusiasts are entirely carrying the AI water on AMD’s non-cdna platforms (imho). You can do some amazing AI stuff on Strix Halo, and run agentic AI… but it’s kind of this weird adjacent experience and the experience focuses mostly on inferencing. Not so much fine-tuning or even some of the crazy fun edge cases we’ve explored like running DeepSeek R528 in Q1 quants in ~~140gb of platform memory (Hard to do that on APU/RDNA).