what is the model of the fan you used?, i am looking for someone similar
2 Likes
Hi there.
While I am aware that CUDA has some absolutely great ‘getting started,’ material, and guides, books, etc.
Does the same exist for ROCm? Or would one just pretty much have to learn CUDA (given how similar they are) and use that to have an understanding of ROCm?
Thx
From what I understand in think it’s HIP specifically that translates Cuda code into ROCm code
I don’t know. A whole lot about programing so idk
2 Likes
Pytorch “just works” so if you start there you’ll be impressed.
Lower level code is doable too but a little more elbow grease.
2 Likes
Yeah I thankfully got ROCm recently installed (after lots of dependency pain) on an ubuntu build, so I’ll play around with it if I ever bother to.
Have some other Lattice (iCEstorm?) related project to do first, so it’ll help as I get more used to leenux.
few things , you can use the UPP tool , which can be installed via pip , to change the powerlimit , without using SMI, or flashing the vbios. , it does this by modifying the softpowerplay tables. Be careful though, because vega WILL draw >500w if you let it, the vrms shouldn’t be that much of an issue up to 300w since they will operate up to 115c without issue, and they are sinked by the large metal bracket. The pcb is basically identical to the wx9100 minus the unpopulated displayport pads, and the fe is very similar really only different by the display outputs and some component placement , this tool could also be used to change the voltage and clocks, if desired, so it is probably possible to do >1600mhz if desired.
secondly, 97x33 mm blower fans, while not optimal interms of mounting , do provide quite alot better airflow, loud, but can easily keep the hotspot under 85c with a 285w power limit with the stock heatsink, I used a 2.94amp version, but there are 2.4 amp ones, which should be similar in performance to the stock blower fan that comes with the vega FE, you can also get them in 3.6 and 6 amp versions… but I feel as though they would be excessively loud, but if you wanted to run 400w, it might be possible to do so with the stock heatsink.
thirdly, seems there is some issue with allocating a certain amount of vram via pytorch, as using more than around 10gb of memory will result in a memory access fault at least thats what I’ve experienced, not sure if its a bug with ROCM or pytorch itself, but it doesn’t seem to be unique to vega 10, since I had the same issue using vega integrated graphics, and there are reports of it on the mi50/radeon 7 and the mi250
and finally, there seems to be some variation between mi25s, The instinct card I have reports 56compute units in rocminfo, rather than 64, has 2x 8pins, I’ve seen online that there are some that have 6+8pin configurations, it definitely is a proper instinct card , and has 16gb of memory. So i’m not really sure if this is a software issue, or some obscure sku.
1 Like
It can something very briefly spike VRAM consumption past what the card has and pytorch really doesn’t like that
I had briefly looked into power play table hacks but most of the guides wanted me to change something in the kernel and I literally learned how to Ubuntu like 5 weeks prior to writing the guide
Got any resources for the upp thing
1 Like
can’t post links , since I literally just registered, but its on github by sibradzic (the readme is your friend)
its pretty easy to use thank fully, you can run “upp dump” which shows all of the different parameters, and then you can do upp set --write parameter/subparameter=value , upp has to be run as root inorder to actually write values, its also capable of writing to files and dumping powerplay tables from roms too.
edit: an example would be sudo -E env “PATH=$PATH” upp set --write PowerTuneTable/SocketPowerLimit=225, this will set the powerlimit to 225w, and it does so in realtime, so be cautious ,if you set bad values , it will crash your system/ or kill the card with stuff like voltage
1 Like
You should be able to replace all or most of those instructional steps with nixified.ai
For example
nix run github:nixified-ai/flake#invokeai-nvidia -- --web
Lol
So I did some further stuff, the stock mi25 vbios on my card was softlocked at 56 compute units, after flashing to the wx9100 vbios, all 64 compute units are listed in rocm info, performance for other tasks like 3d acceleration was also much better independently of the power limit. so in general probably best to use something other than stock , also I dumped the exposed flash chip with a programmer and its 1mb instead of the 256kb , and has some extra crap in it, dunno what for, but It probably has something to do with that extra chip on the back near the vbios chip. so bear in mind that if you brick it, the rom you get from gpuz is not the full rom.
2 Likes
The w9100 is probably the best bet for bios especially with the power play thing, for higher frequency you will need more voltage than stock bios as the wx9100 silicon is binned differently and needs less voltage at those frequencies
At least on my cards
I tried this in my workstation that has a 6900xt and a 6700xt. I wanted to see if I could get it working in Ubuntu 22.04 and perhaps that was my downfall. I used Rocm 5.4.2 since that’s the one that pytorch says works with pip nowadays.
One question I have with the amdgpu --install command
I see you suggest adding basically all of the use cases. I have only used the --usecase=rocm to get pytorch working in Docker. I thought all the other libs were only necessary if you wanted to compile pytorch from source on your machine? or am I mistaken here?
after pip installing using the following command:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
I run python3 and import torch to see if torch.cuda.is_available() and it returns false. so it won’t work on my default python3.10. so I tried pulling rocm’s pytorch container to see if it works there:
docker run --net=host -it --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --device=/dev/kfd --device=/dev/dri --group-add video --ipc=host --shm-size 128G rocm/pytorch:latest
and I can see that the python 3.8 that that ships with does see my amd gpus. torch also says cuda is available. I cloned in and the torch that it comes with in docker is 1.13.0 and it fails out with the following error
The program is tested to work with torch 1.13.1.
To reinstall the desired version, run with commandline flag --reinstall-torch.
Beware that this will cause a lot of large files to be downloaded, as well as
there are reports of issues with training tab on the latest version.
Use --skip-version-check commandline argument to disable this check.
==============================================================================
Downloading: "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors" to /var/lib/jenkins/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.97G/3.97G [00:44<00:00, 96.3MB/s]
Calculating sha256 for /var/lib/jenkins/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors: 6ce0161689b3853acaa03779ec93eafe75a02f4ced659bee03f50797806fa2fa
Loading weights [6ce0161689] from /var/lib/jenkins/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors
Creating model from config: /var/lib/jenkins/stable-diffusion-webui/configs/v1-inference.yaml
Failed to create model quickly; will retry using slow method.
loading stable diffusion model: TypeError
Traceback (most recent call last):
File "/var/lib/jenkins/stable-diffusion-webui/webui.py", line 139, in initialize
modules.sd_models.load_model()
File "/var/lib/jenkins/stable-diffusion-webui/modules/sd_models.py", line 438, in load_model
sd_model = instantiate_from_config(sd_config.model)
File "/var/lib/jenkins/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py", line 89, in instantiate_from_config
return get_obj_from_str(config["target"])(**config.get("params", dict()))
File "/var/lib/jenkins/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 550, in __init__
super().__init__(conditioning_key=conditioning_key, *args, **kwargs)
File "/var/lib/jenkins/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py", line 81, in __init__
super().__init__()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/core/module.py", line 122, in __init__
self._register_sharded_tensor_state_dict_hooks_if_available()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/core/module.py", line 2022, in _register_sharded_tensor_state_dict_hooks_if_available
self.__class__._register_load_state_dict_pre_hook(
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1467, in _register_load_state_dict_pre_hook
self._load_state_dict_pre_hooks[handle.id] = _WrappedHook(hook, self if with_module else None)
File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 54, in __init__
self.module: weakref.ReferenceType["Module"] = weakref.ref(module)
TypeError: cannot create weak reference to 'weakcallableproxy' object
Stable diffusion model failed to load, exiting
inside the container, I’ve tried upgrading torch with both conda and pip. However, conda doesn’t see torch installed in my conda env so pip is the only one that worked. it upgraded torch to 2.0 and then when I check if cuda.is.available() it responds false inside the container after upgrading to the newest torch. it looked like it pulled cuda 11 packages when installing so that’s probably the reason. Anyone run into this and how did they get around it?
I figured it out. I didn’t have my user in video and render groups
sudo usermod -aG video $USER
sudo usermod -aG render $USER
worked to get it working outside my docker container. using conda for env management now.
1 Like
extracted the pptable from the FE vbios, and loading it works just fine , gives FE performance and enables overclocking if you wanted to do that lol, so if you want to change between wx9100 and fe mode during run time you can. I see basically no reason to use the FE vbios with this, since it breaks the mini displayport on the mi25 card.
loading procedure is just
sudo cp < pptable file > /sys/class/drm/card0/d
evice/pptable
extracting pptable from a rom can be done with the upp tool via
upp --pp-file=pptable.bin extract -r vbios.rom
Also this reminds me the 264w fe vbios, is actually for the liquid cooled version If I remember correctly, so be careful with that one lol.
1 Like
Just a heads up: you don’t need the DKMS blob if you are using amdgpu on a last/current year 6.ish kernel. Recent amdgpu already bright up everything you need.
I’m running on RDNA2 on a Fedora toolbox to boot (basically podman). I’ve installed the runtime with:
amdgpu-install --no-dkms --usecase=rocm,hiplibsdk,mlsdk,mllib
As of 2022, AMD Kernel Fusion Driver (KFD ) is now integrated in this one kernel module. AMD KFD development at AMD is part of ROCm, under the ROCk project.
This should include everything torch needs to execute Stable Diffusion webui. As of writing this please make sure you are on Python 3.10. I’m not sure torch for 3.11 is prime time yet.
My webui-user.sh params for the 6800m are:
export HSA_OVERRIDE_GFX_VERSION=10.3.0
export COMMANDLINE_ARGS="--precision full --no-half --opt-sub-quad-attention --deepdanbooru --listen"
export TORCH_COMMAND="pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/rocm5.4.2"
2 Likes
In order to use the versions of ROCm supported by pytorch you have to use a hyper specific kernel
By supported you mean officially supported? It works fine on 6.2.11 with open source amdgpu drivers. I just need to install the runtime libraries on a rootless container as described above.
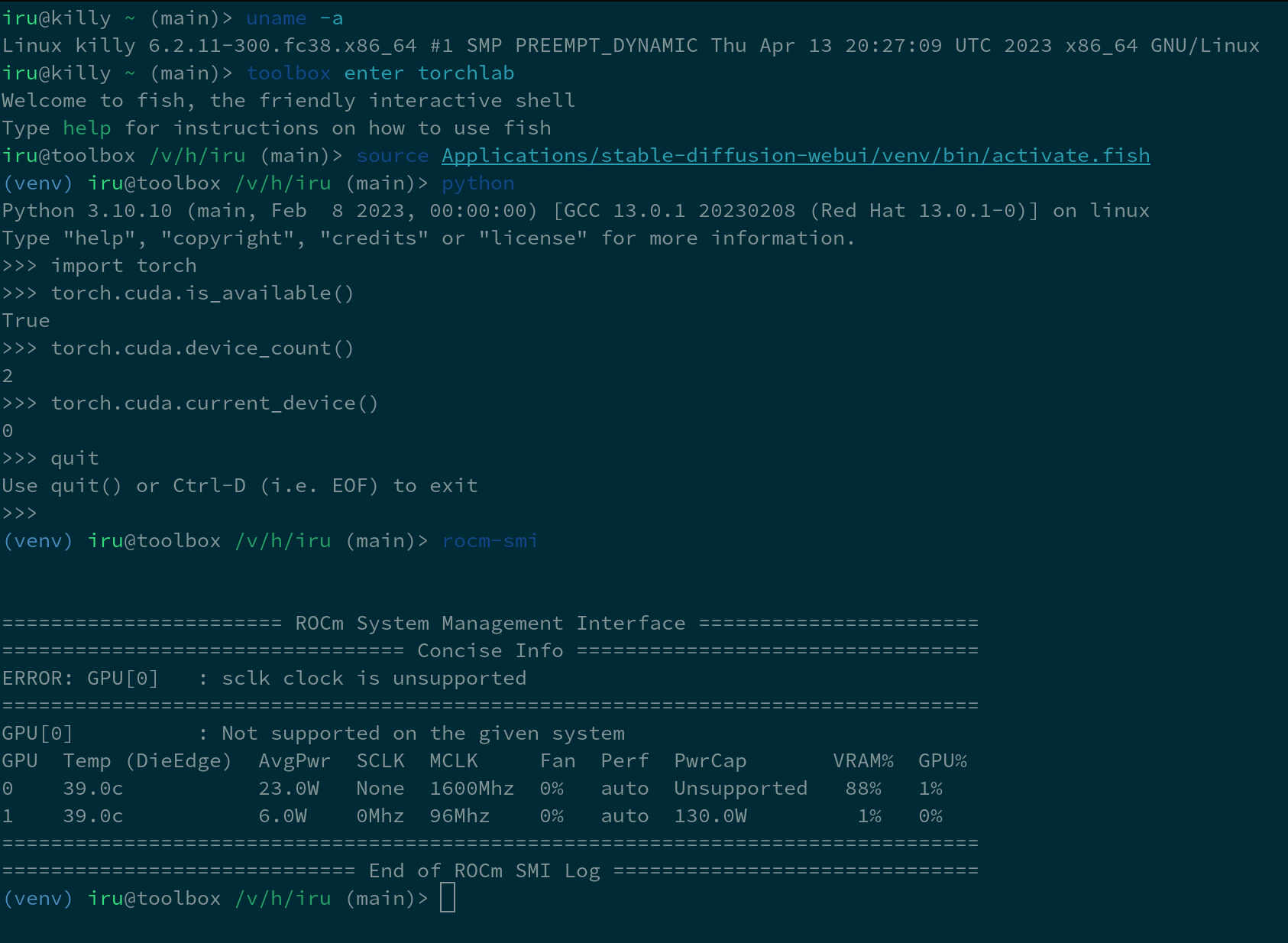
Please check my previous comment on TORCH_COMMAND about PyTorch install. Its not even from the nightly branch.
It takes me 1 minute to generate 768x768 20 steps on DPM++ SDE Karras.

AFAIK Shark is the tech that requires very specific drivers. Torch can go along with whatever as long as its recent.
1 Like
Will that work on Ubuntu?
Yes! I ran the following from the livecd environment on current LTS https://releases.ubuntu.com/22.04.2/ubuntu-22.04.2-desktop-amd64.iso Image:
root@ubuntu:~# uname -a
Linux ubuntu 5.19.0-32-generic #33~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Mon Jan 30 17:03:34 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
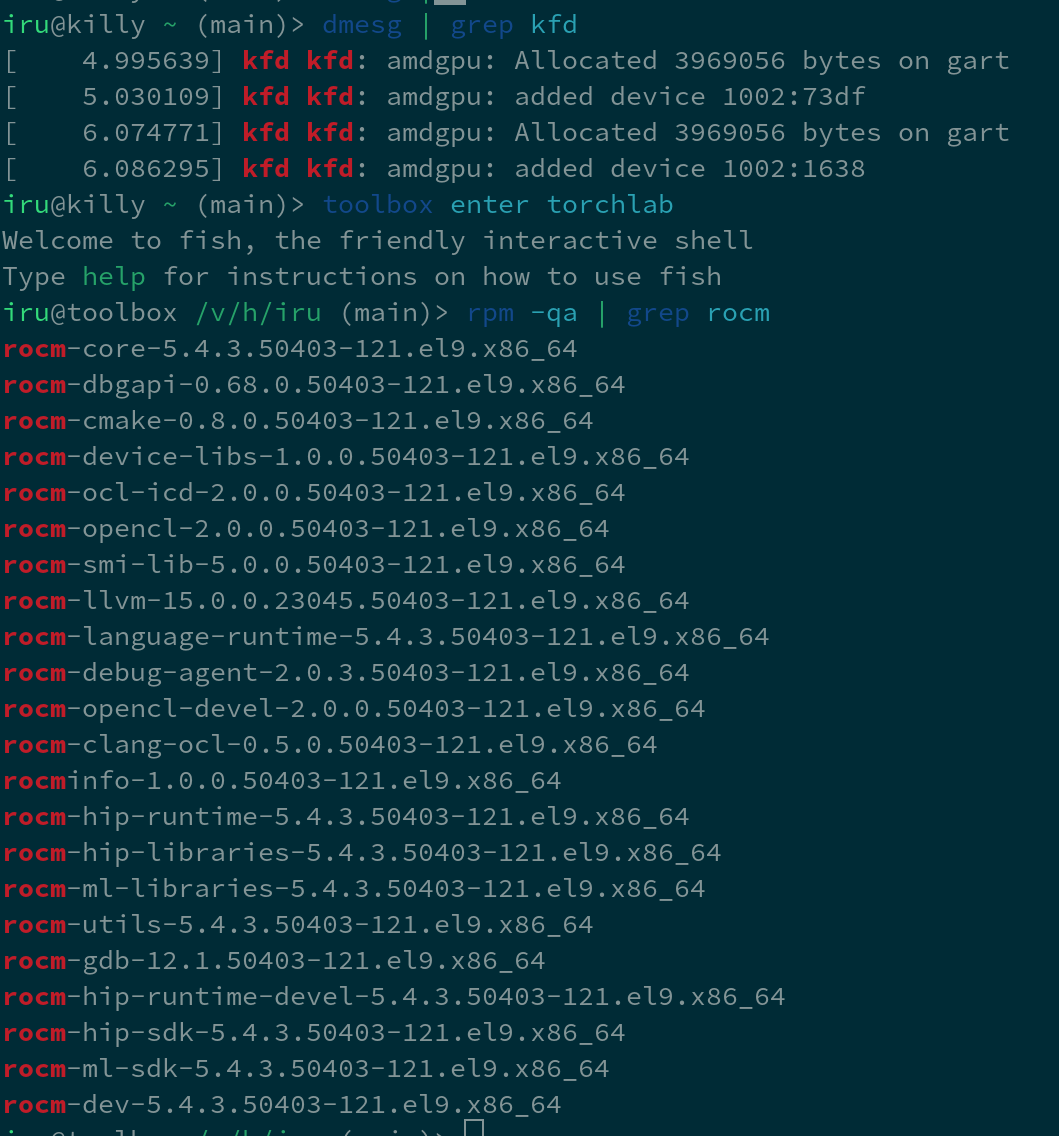
root@ubuntu:~# dmesg | grep -i kfd
[ 4.764483] kfd kfd: amdgpu: Allocated 3969056 bytes on gart
[ 4.808136] kfd kfd: amdgpu: added device 1002:73df
[ 5.807169] kfd kfd: amdgpu: Allocated 3969056 bytes on gart
[ 5.835113] kfd kfd: amdgpu: added device 1002:1638
...
...
...
root@ubuntu:~# lspci | grep -i display
03:00.0 Display controller: Advanced Micro Devices, Inc. [AMD/ATI] Navi 22 [Radeon RX 6700/6700 XT / 6800M] (rev c3)
...
...
...
# Comment: add yourself to the render group (default livecd user is ubuntu)
ubuntu@ubuntu:~$ sudo gpasswd -a ubuntu render
ubuntu@ubuntu:~$ exit
# Comment: have to login again.
# Comment: Enable extra repos
ubuntu@ubuntu:~$ sudo add-apt-repository universe
ubuntu@ubuntu:~$ sudo add-apt-repository multiverse
ubuntu@ubuntu:~$ sudo apt update
...
...
...
# comment: had to run this from /tmp because some livecd sandboxing
# obviously not a problem from a proper installed system.
ubuntu@ubuntu:~$ wget https://repo.radeon.com/amdgpu-install/5.4.3/ubuntu/jammy/amdgpu-install_5.4.50403-1_all.deb
ubuntu@ubuntu:~$ sudo apt install ./amdgpu-install_5.4.50403-1_all.deb
...
...
...
# Comment: besides not using dkms you don't need everything at least not for
# my RDNA2. Maybe some Polaris era might need OpenCL related stuff? IDK.
# The hiplibsdk includes HIP libraries and Mii kernels (which are not related to
# the linux kernel more like a runtime thing) . If you don't install the Mii kernels
# Torch will still work but will complain and warn it might be slower than normal.
# From my observation if you don't have the Mii kernels it takes a while to start
# the first gen after loading the checkpoint but performance is pretty much the
# same after that. I recommend installing hiplibsdk.
# I think you can skip mlsdk and mllib if you don't plan to run training workloads.
ubuntu@ubuntu:~$ sudo amdgpu-install --no-dkms --usecase=rocm,hiplibsdk,mlsdk,mllib
...
...
...
# Comment: LTS has Python3.10. That's good. Not sure about non LTS but if it's 3.11 you might
# need to install 3.10.
ubuntu@ubuntu:~$ python3
Python 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
...
...
...
ubuntu@ubuntu:~$ sudo apt install python3-pip python3.10-venv
ubuntu@ubuntu:~$ source venv/bin/activate
(venv) ubuntu@ubuntu:~$ pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/rocm5.4.2
...
...
...
(venv) ubuntu@ubuntu:~$ python
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.device_count()
2
>>> torch.cuda.get_device_name(0)
'AMD Radeon RX 6800M'
>>> torch.cuda.get_device_name(1)
'AMD Radeon Graphics'
There it is Torch without tainting your kernel. Stable diffusion should work. Remember to supply the necessary env switches on webui-user.sh. My RDNA2 requires HSA_OVERRIDE_GFX_VERSION=10.3.0. Check rocminfo output for clues.
Also considering its a in kernel + runtime thing you can pretty much run a container with read/write access to /dev/kfd (or maybe also /dev/dri/*) and be done with it. I’ve used toolbox which is a convenient way to run rootless containers on Fedora 38 Silverblue. These things are not even touching my OS.
BTW the APUs don’t seem to be really supported. They appear on rocminfo and show up on torch as cuda devices and all but as of writing this it doesn’t actually work.
If you plan on testing this route it might be a good opportunity to compare the performance between the binary blob and open source driver.
7 Likes