i see, well hopefully shared memory support will get added eventually, HIP/cuda does support it , but there is no support with automatic111/torch. if you haven’t try yet, you can use the --medvram and --lowvram, both have a performance hit, but will reduce memory usage.
also, I Discovered that you can use the HIP allocator instead of the torch one, saves a few hundred mb , no or negligent performance penalty.
has anyone experienced “Memory access fault by GPU node-1 (Agent handle: 0x8b3e3c0) on address (nil). Reason: Page not present or supervisor privilege.
Aborted (core dumped)” with vladmandic’s fork, also with base AUTOMATIC1111 it seems to just halt/crash as well, though without an error (doesn’t close just hangs)
Running NixOS unstable but I don’t think that should majorly affect it, I also have another gpu for my video output… I’ve tried flipping them, to no avail.
Edit: A1111 complains about not finding limits, then later crashes…
Edit2: Seems to have to do with libstdc++12, I can try on debian/ubuntu later… If I can figure out NixOS then that would be very nice.
As an artist who has been using Stable Diffusion since its inception, I recently spent some time using a Mi25 and faced a few challenges.
One significant hiccup with Torch + ROCm 5.2 is its limitation on VRAM usage to just 10GB. This is a problem, especially considering that larger batches offer speed benefits.
This issue seems to be addressed with ROCm 5.5. For these GPUs, you can obtain a pre-compiled version of torch & torchvision by pulling the Docker container using docker pull rocm/pytorch. It’s important to ensure that you have the ROCm 5.5 driver and the appropriate kernel before you begin.
I’ve found Doggettx cross attention optimizations the best with this setup in terms of VRAM usage & speed.
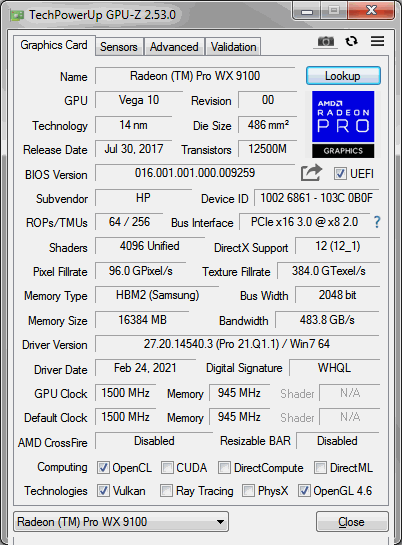
In terms of performance, the Mi25 delivers approximately 40% of a 3060’s performance (with WX9100 bios). Despite being good for its price, it has high power consumption, and I’ve struggled to get Torch+ROCm to work with motherboard slots other than the main x16 CPU lanes. Seems I am not alone. If this were resolved, I’d certainly use one of these in the third slot of my system. On particular upscalers like GANs and LSDR, it competes with the speed of a 3060, suggesting that Stable Diffusion possibly relies more heavily on tensor cores as opposed to being more FP16-focused like some upscalers. I think this because the newer Radeon cards with tensor cores are showing much better results.
For those more serious about Stable Diffusion but not wanting to spend 7900XT money, the 3060 is a strong recommendation. If you’re considering used options, the 2080ti has serious FP16 performance. In my personal testing, the 2080ti was just 12% slower than a 3080 at FP16 models, while consuming significantly less power. The 2060 12GB is a good pick also.
Hm, bit of a bummer that they’re .deb files, was expecting that I could plop them into the system. Suppose I wait until someone fixes ROCm or I PR it myself…
given that nix os already has 5.4.4 , all you would have to do is extract the kdb file from the appropriate deb package, and copy it to the correct directory.
Anyone tried running LLMs on this? I’ve been playing with llama.cpp. It can be compiled with OpenCL and offload both process and memory layers into the GPU. There is also a PR for HIPBlas.
An optimized 30B WizardLM-Vicuna model can fit into roughly 20GB. Since it can be layered you don’t need to put everything on vram. The 13B model uses less than 10GB.
If someone is interested I wonder how many tokens/second this thing can do. Installing llama.cpp is wayyy easier than setting up stable diffusion.
This is slightly off topic as it’s related to delta fans but I’m trying to get a pair of mi25’s setup and cooled. I’ve got a pair of these fans and a 3d printed shroud for 2 40mm fans.
And as you in the picture ( something I paid not enough attention to when purchasing ) the connection is what I can only describe as a proprietary 6 pin.
Anyone know of a controller or adapter? Would rather not have to break out the soldering iron but if a wireing diagram exists that I’ll do it.
I’ve spent the past few days searching myself and just haven’t been able to find anything useful.
Red and black should be the 12v supply, but I’d test first. Then you could use something like this to control the speed as a whole or separate by fan header off the MB .
Edit: here is a good deal on fans I’ve used a couple of times already and no need to guess what wire does what. 12,000 RPM connected to MB fan header. I don’t try to control mine, I can’t hear well so the sound doesn’t bother me.
that second BIOS chip that has tiny solder blobs. are these even meant to be flashed via a clip? the black clip that came with the CH341a programmer doesn’t even come close to touching the blobs. i tried filing the clip down but no luck so far. i bought a better clip ( **Pomona Test Clip,Blue,300 Vrms 5250) and it doesn’t seem to get any closer.
wasn’t able to flash in windows “Adapter not found”. i’m not surprised as windows doesn’t support the Mi25. Linux has a probe timing issue which causes the kernal to crash so no flashing there. this is with a Sandy Bridge 2500k.
i REALLY don’t like the thought of soldering wires to those tiny blobs.
The second bios chip is unnecessary to flash, Once the primary chip is overwritten with a wx 9100 or vega fe rom, it no longer switches to it after boot.
I used a Soic-8 clip just fine, didn’t even have to remove the backplate, I used a bus_pirate with flashrom on linux, only extra step was that I had to pad the rom to the full 1mb to be able to flash , used truncate on linux.
at first it didn’t work. i was getting D4 error on boot. (PCI resource allocation error. Out of Resources). then i remembered i didn’t erase the stock bios. i removed the card, erased, then flashed it with the WX9100 (180w) bios. BAM!