Figured documenting my homelab exploits might be interesting to at least some people, and it might motivate me to actually finish some of the stuff I start working on… 
So this will mostly be a WIP ongoing thing, in case I actually finish something I might do a proper writeup on my blog (or as a separate post on these forums, or both, depending).
Short history
Like many people I initially started out by (ab)using old desktops as servers. This went fine until I switched to a 5 disk RAID6 setup (+ 1 OS disk) and melted the motherboard chipset (pretty close to literally, burnt my finger on the damn thing) on my then-server. Result was some corrupted data and a pretty dead motherboard.
So I bought a (new) Supermicro server and moved the entire setup over. With this I now had hardware that should be more suitable for constant operation, but still no real protection against data corruption (it did gain me ECC RAM though).
Unfortunatley the only real option at the time for that was ZFS, on Solaris. And while OpenSolaris was a thing, switching my only server to Solaris was just not going to happen.
So I’d been keeping an eye on Btrfs hoping for raid5/6 to stabilize to a point where I’d feel comfortable to start using it, which never really happened. Though even if it had it would still have posed the problem that I already had a lvm+mdadm setup so I’d have to do some funky stuff to get that to work in the current setup, and I doubt that would have been pretty. Alternatively, I’d have to look for a new machine and move everything over…
Starting hardware
| Name | superbia |
|---|---|
| Enclosure | Supermicro SC743TQ-865-SQ |
| Motherboard | Supermicro X9SCA-F |
| CPU | Intel Pentium G620T |
| RAM | 8Gb DDR3 Unbuffered ECC |
| HDDs | 1 x Seagate Barracuda 320GB |
| 3 x WD Green 1TB | |
| 2 x WD RE4 1TB | |
| OS | Gentoo GNU/Linux |
This box ran basically everything, among which:
- router/firewall/dns/ntp
- incoming e-mail and spam filtering
- build environment (Jenkins, etc.)
- IRC client
- version control
- file sync and sharing
- media server
- web server
So if this machine was down our entire network was basically down, so experimentation had to happen when it bothered no-one. Not ideal, but this is how I ran my stuff for a very long time.
Initial upgrade
Since I started running into both memory as well as CPU limitations (I blame Docker ) I researched what was possible with the motherboard and took to Ebay (big mistake) to see if I could find anything at a reasonable price.
I ended up buying a Xeon I3-1270 v2 and 32GB of DDR3 ECC SDRAM (effectively making this machine more powerful than my desktop. Hmm)
I also noticed how relatively cheap old enterprise stuff was. Not having upgraded anything in quite a while due to the entire “buying a house”-thing tying up most of my …time… I figured it was time to treat myself to some new toys. After a bunch of research, since I was basically 8 years out-of-date on hardware.
Gula (FreeNAS)
So after reading a bunch (but not quite enough, never enough…) I ended up getting gula (more details on that build in the thread here). The idea was to offload a bunch of stuff from the main server, most notably docker containers that shouldn’t be exposed externally (since docker likes to punch holes in the firewall, having it on your firewall box is not ideal…) and also be able to move data over from the aging drives in superbia (all of them have 7+ years of uptime on them). Unfortunately I hadn’t quite considered power consumption, or rather, I wasn’t quite aware how much more power efficient server hardware had gotten in just a few generations. With a Xeon L5140 this machine still easily gobbles up over 300 Watts at idle, which isn’t exactly ideal…
For now I’m using it as an offline backup box. I power it on during the weekend (while power is cheaper), run the backups, and then shut it back down.
Current hardware in this system:
| Name | Gula |
|---|---|
| Case | 3U enclosure with 16 SATA2 hot-swap bays |
| Motherboard | Supermicro X7DBE (and a SIMLP-B IPMI card) |
| CPU | 2 x Intel Xeon L5140 |
| RAM | 32GB Fully Buffered ECC DDR2 |
| HBA | IBM LSI Sas9201-8i based HBA |
| Intel RES2SV240 SAS Expander | |
| System drive | Kingston A400 120GB SSD |
| HDD | 8 x 1TB |
Luxuria (Sun Fire/Oracle Enterprise T5120)
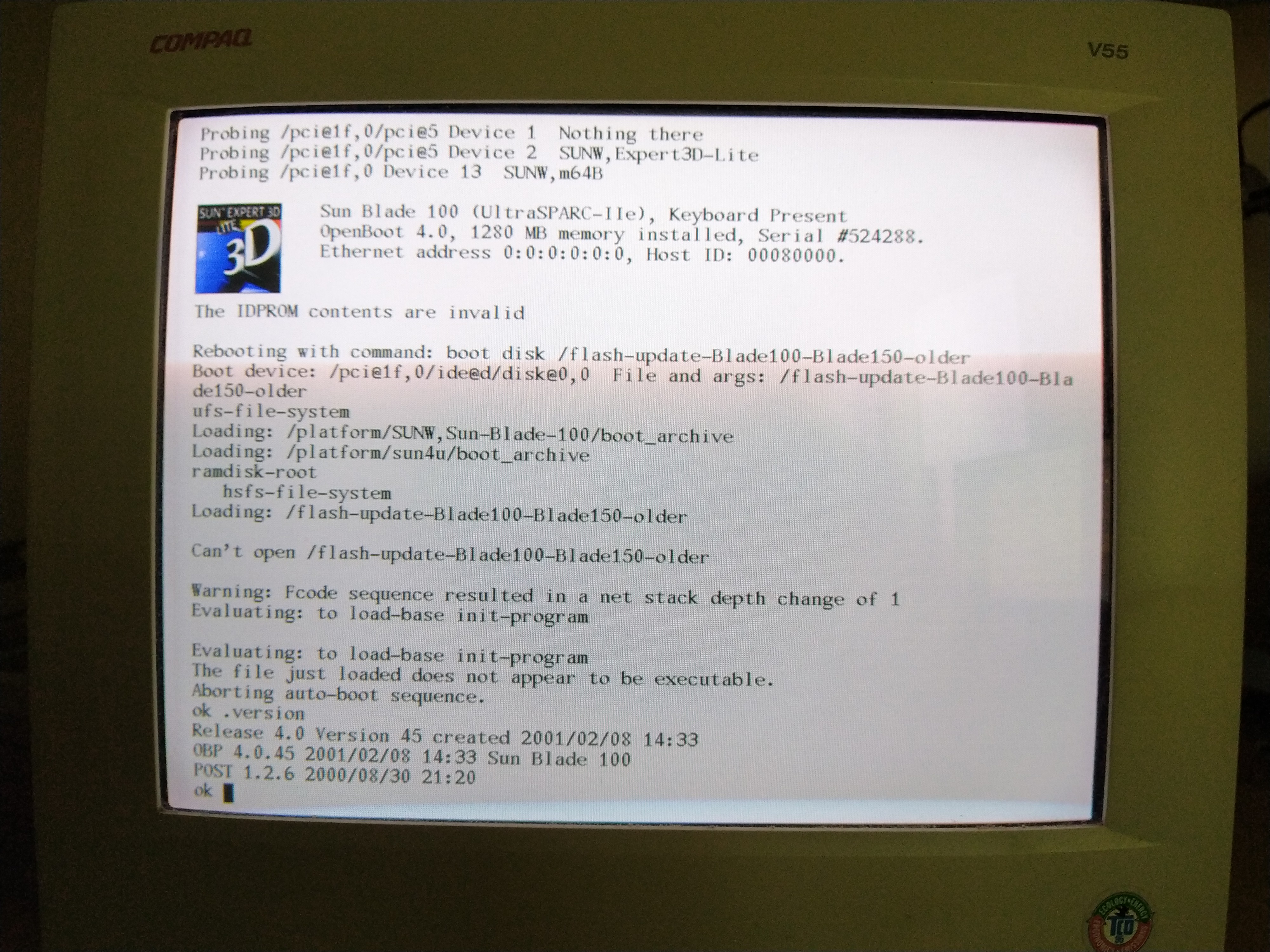
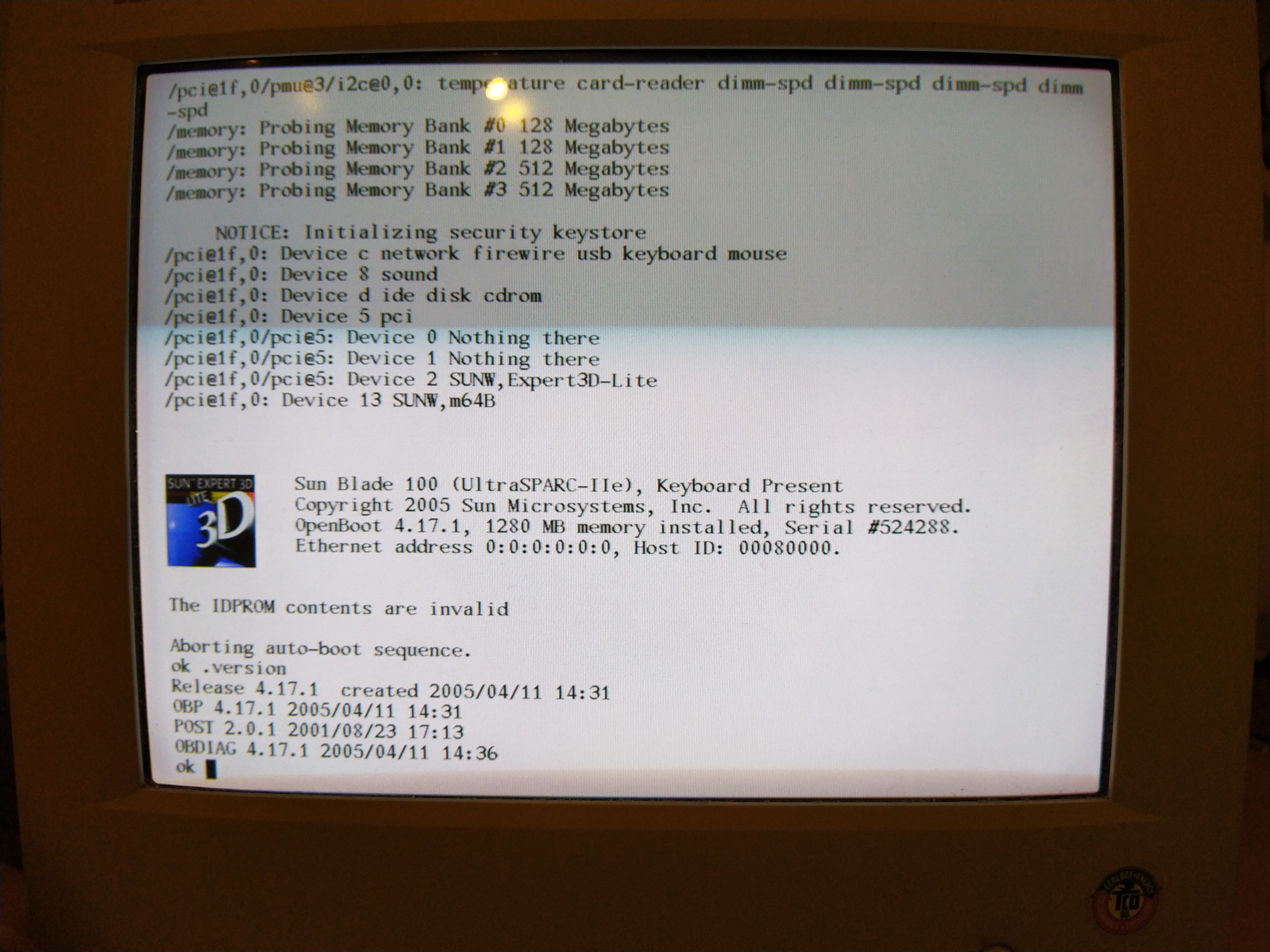
I got this one for a pretty decent deal. These are UltraSPARC T2 powered systems, supposedly the last to be designed by Sun before the Oracle takeover. I’ve always had a bit of a soft spot for SPARC systems but my Sun Blade 100 is, at this point in time, rather underpowered for “real” use (it also has a dead IDPROM battery, which is rather annoying, and slightly scary to fix).
And well, you can get a feel for that Threadripper life with these for quite a bit less money (but about the same power bill, I imagine ):
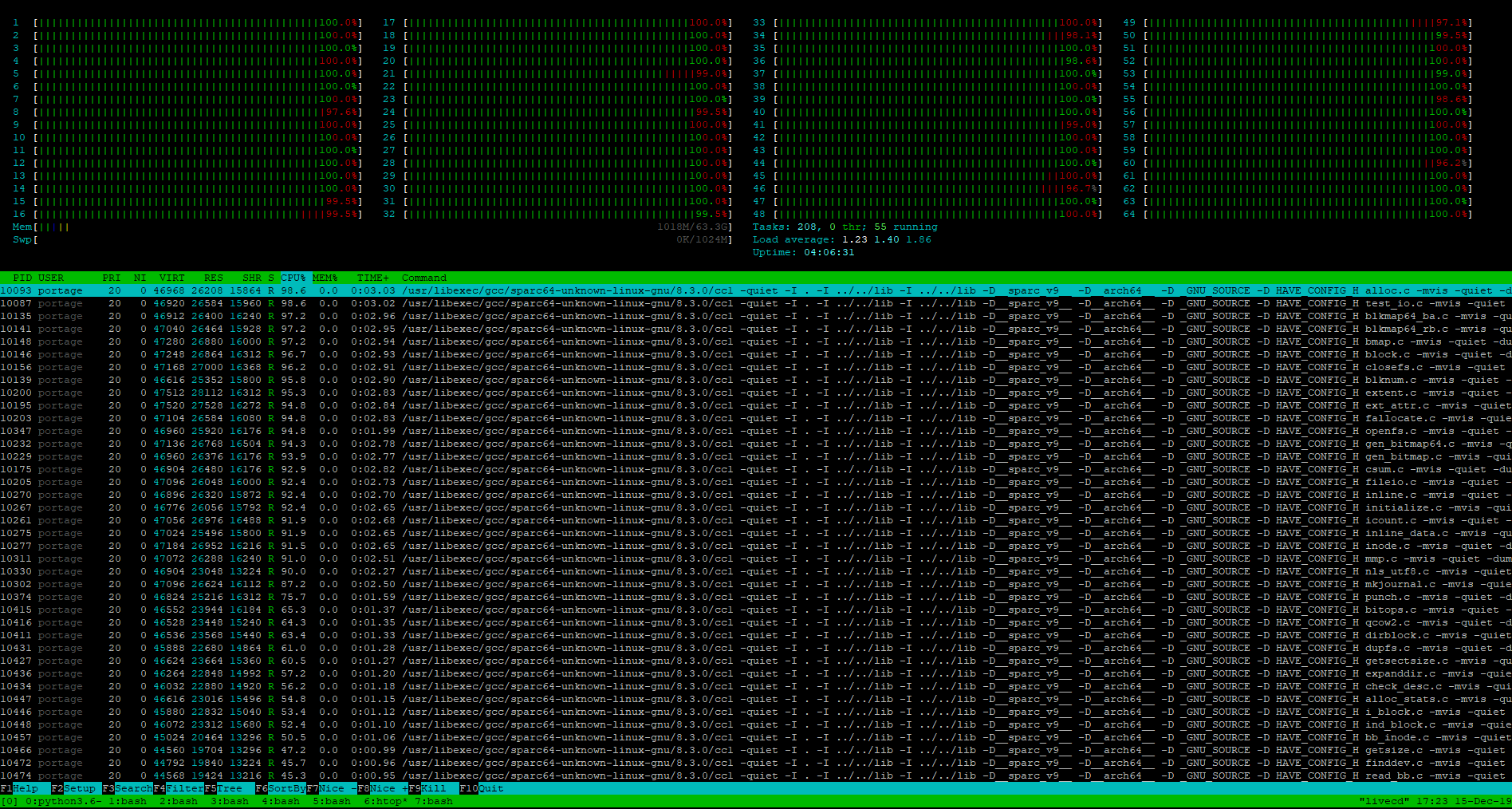
The goal is to try to install Gentoo on a ZFS mirror of the first two disks in this system. So far I’ve managed to install a regular Gentoo on the third hard drive so I can use that to bootstrap the target install (and I’ll be able to use this bootstrap disk as a backup in the rather likely case something eventually goes wrong with my experimental Gentoo-on-ZFS-on-UltraSPARC setup, assuming I even make it to a bootable state at all).
If all of the above materializes the machine also came with two fibre channel HBAs that are tempting to play with…
Janus (router/firewall)
All of the above still left me with a lot of services on what was essentially my firewall box. Still not exactly ideal, so after some digging I ended up buying another server, though this time I did pay attention to power consumption (and noise, no 70dBA fans this time around).

| Name | superbia |
|---|---|
| Enclosure | Supermicro CSE-815 (1U) |
| Motherboard | Supermicro X9SCI-LN4 |
| CPU | Intel Xeon E3-1240 v2 |
| RAM | 8Gb DDR3 Unbuffered ECC |
| HDDs | 2 x 120GB SSD in ZFS mirror |
I got the system without CPU or memory. For the memory I just used the old memory from my initial server, superbia. At first I also intended to use the Pentium G620T from that system, but that CPU lacks hardware encryption (AES-NI support), so I ended up getting the Xeon E3-1240 v2.
As OS I started off with OPNSense, however it would suddenly “forget” the port forwarding rules, and on every restart it would just stop passing traffic entirely. I could ping to outside (on IP, and on hostname, so DNS was fine) but I was unable to surf anywhere (including the modem on the WAN link), not on IP, nor on hostname. I factory reset the OS and ended up with the exact same issue a day later.
Initially I thought it was a cabling issue (had pulled new cables) as I had issues with packet loss that I fixed by re-punching. But attaching a laptop proved that everything was working as far as hardware was concerned, so the issue really was with OPNSense, somehow.
Given that for the entire duration of this the network was down (unappy household) I ended up not wanting to spend too much time on debugging what was going on and ended up installing pfSense instead. I set that up the exact same way as I had set up OPNSense and it has been humming along great ever since.
Rack
I also wanted to move all that out of my office. So I started looking for a rack (not quite as easy/cheap this side of the Atlantic, it would appear) so I could move everything to the basement.

Future
This is basically the starting point, next "planned"steps include:
- setting up InfiniBand between the servers (and potentially getting that routed by pfSense)
- get another machine for storage
- centralize logging
- add monitoring
- update OBP on the Blade 100, and potentially fix the IDPROM (if it turns out I need to get a new one I’ll probably just make do)