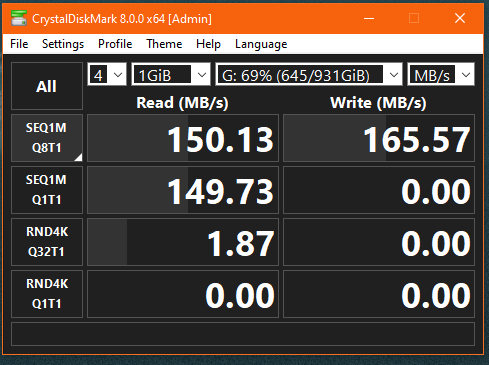
Here’s some disk speed tests, run on the host, with a LV on the RAID 10 array mounted to the host. (ie. no VM and no network involved).
#> dd if=/dev/zero of=diskbench bs=1M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 3.01235 s, 356 MB/s
#> dd if=/dev/zero of=diskbench bs=1M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 2.32202 s, 462 MB/s
#> dd if=/dev/zero of=diskbench bs=1M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 2.4362 s, 441 MB/s
#> dd if=/dev/zero of=diskbench bs=2M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
2147483648 bytes (2.1 GB, 2.0 GiB) copied, 4.94802 s, 434 MB/s
#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 39.6829 s, 541 MB/s
#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 37.4604 s, 573 MB/s
#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 37.3123 s, 576 MB/s
It seems to get faster each time I run the test. Caching?
Next, same test, but from inside the NFS VM. No network protocol, just disk writing to the same disks through the virtualization layer.
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 79.4929 s, 270 MB/s
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 87.1805 s, 246 MB/s
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 88.1575 s, 244 MB/s
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 89.4389 s, 240 MB/s
Holy Bandwidth, Batman! That VM layer is cutting disk IO in half!
I’m not sure why I got 356, 441, and 462 MB/s on the first three host tests, but all subsequent host tests have been 540-570 MB/s.
Other than the first test of 270 MB/s, all the other tests from inside the VM ran at about 240 MB/s.
Next test: Reboot the VM and watch free.
NFS VM, after fresh reboot:
free -m
total used free shared buff/cache available
Mem: 987 95 766 2 124 758
Swap: 0 0 0
After starting dd:
[AoD.NFS]#> free -m
total used free shared buff/cache available
Mem: 987 117 70 2 799 712
Swap: 0 0 0
Upon completion of first dd:
AoD.NFS]#> free -m
total used free shared buff/cache available
Mem: 987 96 101 2 789 731
Swap: 0 0 0
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 98.3258 s, 218 MB/s
So it looks like it’s keeping a bunch of stuff in cache. And memory may be an issue.
Second dd:
While running:
[AoD.NFS]#> free -m
total used free shared buff/cache available
Mem: 987 117 64 2 805 710
Swap: 0 0 0
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 87.1268 s, 246 MB/s
Second one was a little faster, so I think some cache has come into play.
Bump VM RAM from 1G to 4G:
After reboot:
[AoD.NFS]#> free -m
total used free shared buff/cache available
Mem: 3946 104 3750 5 91 3675
Swap: 0 0 0
RAM dropped like a fly until it bottomed out here during the transfer:
[AoD.NFS]#> free -m
total used free shared buff/cache available
Mem: 3946 125 104 5 3710 3550
Swap: 0 0 0
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 99.764 s, 215 MB/s
Still only 215MB/s though. Same test again:
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 90.4059 s, 238 MB/s
AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 86.9767 s, 247 MB/s
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 87.9707 s, 244 MB/s
OK. Now I’m mad! Allocating 32GB of RAM to the VM:
[AoD.NFS]#> free -m
total used free shared buff/cache available
Mem: 32170 152 31922 8 95 31706
Swap: 0 0 0
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 99.23 s, 216 MB/s
[AoD.NFS]#> free -m
total used free shared buff/cache available
Mem: 32170 156 10760 8 21253 31549
Swap: 0 0 0
OK, 20GB of buffer/cache! And still only 216MB/s
Again for posterity:
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 88.7613 s, 242 MB/s
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 88.3195 s, 243 MB/s
So it appears that 1GB of RAM performs no differently than 32GB of RAM in this test.
I also re-ran on the host after all that, just to be sure nothing changed:
#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 36.9425 s, 581 MB/s
I can try playing with CPU cores and other stuff, but I think something is going seriously wrong in the virtual disk layer.
Settings in virt-manager for the LVM disk used in the VM as the NFS share:
Device Type: VirtIO Disk 2
Disk Bus: VirtIO
Cache Mode: none
Discard Mode: Hypervisor Default
Detect Zeros: Hypervisor Default
Again, none of the tests above used the NFS protocol, so network is not a factor.