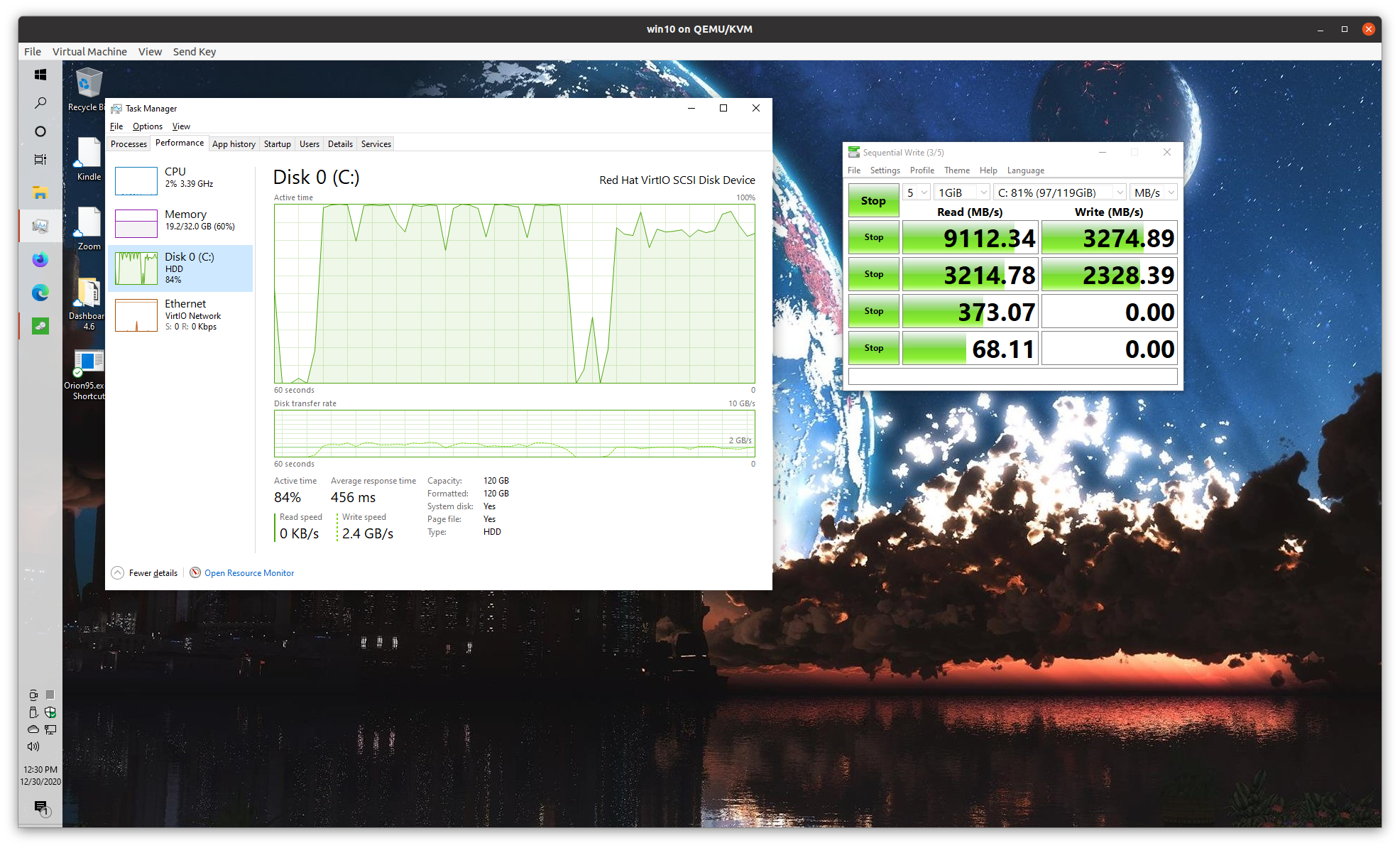
There is definitely something wrong with your VM disk IO.
I just ran a Crystal DiskMark in my Windows VM running on this Ubuntu system using libvirt / KVM. Now, there’s a TON of host-side disk caching going on here, although the image is on a Samsung 970.
I just noticed this. Unless you have some special reason to use “none” I recommend setting that back to Hypervisor Default, which should be “writeback” which will only use disk sync when the guest commands it with a flush command. At least give it a try.
The amount of host side caching shouldn’t matter in this case.
Guest should be able to issue enough parallel write requests… , and we’re only at a few hundred megs a second CPU performance shouldn’t be a bottleneck even when using a single thread.
It’s as if there’s some queue depth setting somewhere in qemu that’s limiting performance.
Nah, this is most, guest kernel block driver to host qemu device driver/handler issue.
It did go up from 74MB/s to ~250MB/s with large writes over NFS in some tests, but this is all sequential. And it should be as quick as on the host - 550 MB/s with 6 disk raid 10.
I don’t know if host can expose the block device to the guest with NBD over the virtio network … that way virtio block device stuff is bypassed (it’s not as efficient, but might be faster anyway).
Should be possible to confirm queue depth effects with fio.
Did some digging. The error is not related to LVM, it’s based on io mode.
There doesn’t appear to be a GUI option for it in Virtual Machine Manager, but in the XML, there’s a choice of io type of either threads or native. eg:
It seems like you aren’t allowed to choose writethrough for cache without also choosing threads for io. But io can only be changed by dumping the XML.
But I’m not finding much about io besides 45 minute highly-technical lecture presentations (YouTube), and maybe-answers behind the Red Hat Paywall.
Here’s the (abysmal) performance inside the NFS VM with threads and writethrough:
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 938.99 s, 22.9 MB/s
But the second time (run again immediately):
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 89.5316 s, 240 MB/s
[AoD.NFS]#> dd if=/dev/zero of=diskbench bs=20M count=1024 conv=fdatasync
1024+0 records in
1024+0 records out
21474836480 bytes (21 GB, 20 GiB) copied, 104.079 s, 206 MB/s
Maybe caching is coming into play. But best case, writethrough and threads is still about the same speed as before with native and none. I think something else is going on.