Lotta noise on this thread now but I wonder whether Fedora ABRT data would show anything interesting?
1 Like
Partially. Emerald Rapids and Raptor Lake p-cores are both Raptor Cove microarchitecture. I’m unsure how much of the implementation’s shared but, as they’re pretty congruent (Emerald and Raptor are both Intel 7 with the same L1 and L2 cache sizes), I’d expect most of the layout to be reused. Some divergence is necessary as Raptor i9s have 4 MB of L3 per core and integrate with e-core clusters while Emerald’s 5 MB L3 per core.
Sapphire Rapids and Alder Lake p-cores are both Golden Cove. So Xeon overlaps with Core 12th gen there.
2 Likes
What a fantastic DEFCON presentation that was.
Found the references on reddit again and summary is what the f** were they when designing these products?
Ring bus runs at the same voltage as the cores and might be degrading prematurely, 6.0 GHz boost requires more than 1.5V on some i9’s.
i5 14600K and Raptor Lake CPU’s that don’t boost higher than 5.2 GHz mostly operate below 1.4V hence there are almost no crash reports on these CPUs.
Another wtf moment:
1 Pcore running 6GHz only pulls ~60W. So you can totally wreck the CPU with voltage without even reaching the power limit as long as the voltage is high enough.
And very nice summary of all fail scenario we might see concurrently here by captn_hector mentions another nice thought:
More generally, buildzoid mentioned "electromigration isn’t a problem, you can run a cpu for 10 years and it won’t lose anything" is no longer true in the 10nm/7nm/5nm era, actually a chip is expected to lose 10-20% performance within about 2 years, and the chip is simply built to hide that fact from you. It has canary cells to measure the degradation, and over time it’ll apply more voltage (meaning, it mostly shows up as “more power” and not “less performance”) and eventually start locking out the very top boost bins by itself. And people mostly just don’t notice that because they’re not doing 1C workloads where it matters. But it’s been a topic of discussion in the literature for a while. 1 2 3 4 5 6
I am starting to feel better about my 7950x3d now despite the overall platform flakiness (vbery subjective), compared to this. I think the entire x3d enabled ccd does even pull 60W running at full tilt.
3 Likes
That reddit comment is off the mark on electromigration; it is not an issue on modern COTS CPUs with the metals being used currently.
4 Likes
But it sumps up one thing for the future → paying premium for intels high end factory overclocked cpus is no longer safe and sane move.
Well not unless you do not mind undervolting and underclocking them, but why are you paying those extra hundreds of dollars for?
Personally I am glad for this, it eliminates FOMO of not building intel system this time around. Full amd build is is slightly too flaky for my preferences, but raw power is good.
5 Likes
100% agree; Intel juicing the things to high heaven is very likely the cause… the exact mechanism of error/failure seems to be mysterious though.
1 Like
Still 1.5V on stock configuration is insane. Over 9000 even.
3 Likes
Buildzoid has posted a video detailing this. Back in the spring he used HWinfo to demonstrate that in a stock configuration 1.6v was temporarily being blasted into his 14900K when it boosted up to 6Ghz, before the clock & VID came down as it hit thermal limits. At the time he blamed board makers as well as Intel for their lax loadline voltage specifications (HUB has also been harping on Intel’s lax voltage specifications for years).
Buidzoid’s most recent rant video on the topic has some VID sample size breakdowns courtesy of Igor’s Lab, and Igor’s Lab shows it is the i9 parts that’re getting the highest VIDs of 1.5v, whereas the i7 VIDs stay around 1.428v usually. Buildzoid’s current theory is that the >1.5v VID used to push the high clocks is cooking the ring bus.
With my previous Haswell 4790K system 1.6v was widely considered/known to be degradation territory, and that was a decade ago on 22nm. So I am incredulous that 1.5v is standard for many modern day i9 chips fabbed on “Intel 7 Ultra”, let alone that it apparently gets temporarily boosted up to 1.6v in actuality on i9 chips.
Any idea what the peak VID is on those when they burst clock to the max? Intel’s ARK doesn’t indicate support for Thermal Velocity Boost so I presume they don’t overdrive the volts, but on the flipside Igor’s Lab data indicates the 14700K’s often were 1.428v with two samples at 1.433. I have no idea how to look this up else I would, though I don’t think Intel publicly discloses it.
4 Likes
Ok, haven’t had the time beyond reading some comments, so I will watch it at work. 1.6 even, nuts.
EDIT: sidenote for the future.
Do not only perform stability testing at build time, but log the results and repeat each 6 or 12 months.
Better catch degradation early than try to solve weird crap like observed above.
I don’t remember which video it was he demonstrated the 1.6v stuff, that was before Intel, ahem, updated its ‘specifications’ and everything got changed around. He only talks about it in the vid I linked, just in case that was something you were looking specifically for.
It’s worth doing any time funny business starts happening, really. For example just updating the UEFI on my ASRock B650E Riptide motherboard saw some incredibly large voltage decreases six months after I built the system.
Sure, everyone knew about the VSOC voltage decreases in short order. But nobody commented when ASRock changed defaults on all sorts of other things, such as VDD Misc dropping from launch day 1.3v to 1.1v and CLDO VDDP dropping from 1.1 to 0.95v. Thankfully neither affected stability far as I could tell, and I did extensive stability testing when playing around with my Hynix A-die DDR5-6000 kit. (It’s wild how much is left on the table with Hynix DDR5 chips at the stock 1.35 volts) Point is parts can wear out over time, but stability changes can come from all sorts of places not just degradation.
2 Likes
@wendell In the video you mention 4200 in combination with “4 DIMM configuration”, which is slightly different than 2DPC. Intel uses the “2DPC” in their specs to identify boards with 2 DIMM slots per channel, even if not fully populated. And applies different limits to them with only 1 DIMM populated instead of boards with just 1 DIMM slot.
I have found no 1DPC W680 board, so I am assuming, like in the video you mean actual DIMMs not slots?
If that is the case the numbers still seem to be slightly outside of official Intel specs or am I misunderstanding sth.?
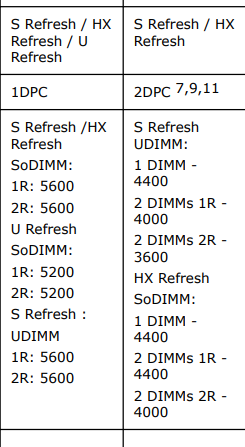
1 Like
No diy boards sure but oem boards are out there.
https://www.intel.com/content/www/us/en/support/articles/000088926/processors.html
Also this is a thing ive come across. Mixed dimms in channels which is not guaranteed whereas same dimms in a channel is ok
Have boards with solder holes for 2dpc but no populated components. This used to mean the board maker verified operation at nornal speeds. Dell certainly does this at yuuuggee volumes. This spec says
- Populating with a single DIMM per channel for either 1-DIMM per channel (1DPC) designed board and 2DPC designed board produces no memory speed impact. *
3 Likes
Ok.
Then it would seem Intel’s specs are contradicting themselves? Why would they list 1 DIMM configs under 2DPC with lower speeds than under 1DPC if their position is that it makes no difference?
Or do you just mean, that boards can be classified as 1DPC, if there is no 2nd slot soldered, even though the pads are there? That would make sense to me. I am no high frequency expert, but can totally imagine that the pins in the socket and solder joints are the most problematic points for signal integrity, and the small difference in trace-length does not cost anything.
So where all boards running at > 4000 simply such boards that would qualify for 1DPC because the secondary slots were not present?
1 Like
So what is the consensus on which SKUs this impacts? Is it just the K parts? Just the i9s or also the i7s? I was in the middle of doing a bunch of research for a new server and had my eye on an i5 w/ W680 which came to a screeching halt once I saw this video.
Calling 14 “series” a generation is a little bit far-fetched…
A cache may actually make more sense than memory controller. If it was just the memory controller, I’d expect similar degradation on i7s. However, the cache also appears to be rather similar between these products…
https://ark.intel.com/content/www/us/en/ark/compare.html?productIds=236783,236773
Hmm… except for the one E-core cluster and some cache difference, the only other difference I can find is the absence of TVB on i7, and apparently this issue is not TVB related. Or is it?
Scratch my previous comment.
I feel much better about my Skylakes now xD (14nm).
I have a 13900k that is horrifically crashing, it was never over clocked.
I upgraded from a 12900k water cooled overclocked monster machine but decided that it wasn’t worth all the hassle anymore and the unreliability. I also had problems with PCI ASPM and clock gating (which default on) when using my 40G Mellanox Connect 3 card with a Nvidia 3090, and everytime the bios reset due to overclocking stability I had to pull everything out of the computer.
I got the 13900k ran it completely stock until I started getting crashes in PUBG. I under-clocked my gpu first, then under-clocked my ddr5 ram to 4800. Both seemed to help for a while and then the crashes would get worse. I then changed the bios power profile based on what others had experienced and change it to ‘INTEL FAIL SAFE’. This also helped for a while. I changed the clock speed to be capped at 4000mhz, until the crashing became horrific and I gave up and bought a 7800x3d which has been amazing.
I think this likely affects a huge number of people (maybe >50% of 13900k/14900k owners), it’s just really difficult to diagnose CPU failures over the rest of the hardware/software stack. I also think the people who buy silly top end CPUs (myself included), don’t have the time to spend figuring it out / proving it’s an RMA etc.
I also don’t know what Intel can possibly do about it unless they figured out the solution already and can now produce reliable chips. I’d take 12900k in replacement immediately.
@wendell: If it helps, you mentioned you wanted examples. I’m in Perth, Australia, so the latency will be horific but I can’t it my rack and put linux on it if you want to tinker. I don’t have a IP KVM but can give you access to a APC / remote power-on/off. Alternatively if you have some sort of plan I can run it and give you the results.
2 Likes
Transmission line theory is wild coming from the calm of DC-circuits. All sorts of thing that are normally safe (such as “dead legs”) suddenly make the card house blow out the window.
1 Like
Intel’s CPU cache has built-in ECC capability. When the ECC catches errors in the cache it will try to correct them. If it can this generates a WHEA “A corrected hardware error has occurred” in the event logs with a reference to an internal parity error. If it can’t correct it, well then you get an “uncorrectable” hardware error has occurred along with a nice failsafe BSoD. Garbage in from failing RAM can trigger this which I experienced on my Haswell system.
I mentioned above the 13700T doesn’t support TVB, or at least the ARK page doesn’t indicate it. Which makes Wendells data set all the more intriguing… couldn’t find what the typical VID values are for that model, though.
Hello everyove i have a i7 13700k and my pc keeps crashing , having blackscreens , and bluescreens when i play any game can someone please reach out