The goal here is to document my attempts and results to inject ECC errors for the purpose of verification whether error correction is functioning.
This is especially relevant on Ryzen where some boards seem to advertise being able to take ECC UDIMMS but don’t specify if ECC will be functional.
The situation is further complicated by AMD essentially mandating that Desktop Ryzen boards cannot declare full ECC validated support - most likely for the purpose of market segmentation.
The solution I am attempting here is by no means anything new:
Initial inspiration
Later reproduced by diversity on ixsystems/truenas forum:
Corraborated by @Mastakilla:
And thanks to @kwinz for bringing to my attention a similar approach taken by Passmark:
Their tool is was confirmed to be delayed ATM due to silicon shortage:
I fully expect this to be the tool to use in the future but at the same time I wouldn’t expect it to be as cheep as an aliexpress DDR4 riser, a button and a few wires.
So the main thing to use is this kind of aliexpress DDR4 riser (~6$):

Apart from that it’s only wires, a mono-stable switch (reset type) and maybe a resistor.
As mentioned in the first paper only a few wires are really necessary but using a riser makes this into a more easily reusable tool that could be included into mobo testing (wink, wink, @wendell)
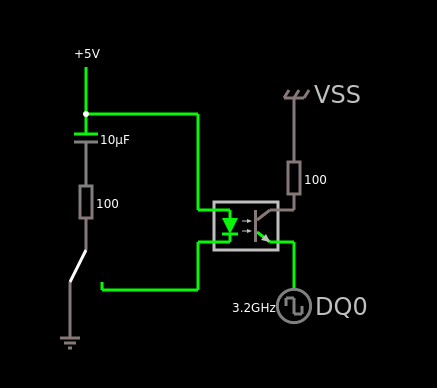
The idea is basic: short a data pin to ground - this causes an error and if ECC is functioning then we should get a report (* PFEH may stir things up - more details will follow)
Depending on the module type there are various documents that can tell you which pin is which:
Vss designates ground
DQx designates data pin
First 16 pins for faster reference:
| Pin | Function |
|---|---|
| 1 | Not conencted |
| 2 | VSS |
| 3 | DQ4 |
| 4 | VSS |
| 5 | DQ0 |
| 6 | VSS |
| 7 | Data Mask |
| 8 | Not conencted |
| 9 | VSS |
| 10 | DQ6 |
| 11 | VSS |
| 12 | DQ2 |
| 13 | VSS |
| 14 | DQ12 |
| 15 | VSS |
| 16 | DQ8 |
I tried a few different data pins but none seem to behave different.
So my pin selection was simply based on convenience of running short wires.
(But I would advice against using pins beyond 144 - since not all DIMMs are dual sided.)
Software used:
Errors are best observed in memtest86+ - they appear reliably.
One note: after shorting the pins there will most likely be multiple errors - some appear immediately but some can appear a while later. (If a write is corrupted then memtest can potentially read and verify it after going through whole memory space first)
Linux kernel reporting was flaky - it worked but for some reason I am routinely unable to trigger errors more than once. Not sure why - This is something to look at separately
Hardware used:
X470D4U (3.50 BIOS)
Ryzen 2600
Kingston KSM26ED8/16ME
Observations:
How BIOS settings change things when a 1-bit error is introduced:
| PFEH disabled/auto | PFEH enabled | |
|---|---|---|
| ECC enabled/auto | 1bit corrected error report | zero errors/reports, acts as if nothing happened |
| ECC disabled | 1bit uncorrected error | 1bit uncorrected error |
The matter of resistors: shorting to ground has a potential to induce current that could damage something. So shorting through a resistor seems like a good idea but even without it I am yet to fry anything.
Results of shorting DQ0 to VSS through various resistors:
| riser variant | resistor | ECC enabled | ECC disabled |
|---|---|---|---|
| third/soldered | 100k | no error | no error |
| third/soldered | 1k | no error | no error |
| third/soldered | 220 | no error | no error |
| third/soldered | 147 | no error | no error |
| third/soldered | 122 | no error | no error |
| third/soldered | 100 | 1bit error corrected | reboot |
| third/soldered | 47 | 1bit error corrected | reboot |
| third/soldered | 10 | 1bit error corrected | reboot |
| third/soldered | 0/short | 1bit error corrected | reboot |
Those resistor tests were done using third riser iteration with a button. (described below).
PFEH setting in the BIOS was set to disabled.
When trying to cause 1-bit errors by shorting VCC to data pin while ECC is disabled I am failing miserably. I assume that this is because hand-shorting is too slow.
However - just by touching an exposed data pin with a piece of wire without shorting to VSS I can get one of uncorrected errors:
| riser variant | resistor | ECC enabled | ECC disabled |
|---|---|---|---|
| first/second | N/A - any resistor/piece of wire works randomly | 1bit error corrected report | 1bit uncorrected - real data corruption |
This is most likely a result of small static discharge that is short enough to cause only a singe error instead of a continuous stream while shorting.
Described “static discharge” approach is a pain but it is reproducible and used to test configurations with ECC disabled.
Riser iterations:
My first attempt was mentioned here:

I added goldpin connectors to pin 4 (ground) and pin 5 (DQ0).
First think I noticed was that I cannot use long wires on Data pins - the board would not post. Most likely data integrity is getting decimated. This makes things less convenient.
But I can use long wires for ground if I need to.
Second iteration: Checked different pins, shorting 2 data pins - still flaky and frustrating

Same as the first one but with 2 more wires going to different data pins.
I was hoping to get some 2 bit errors by shorting 2 data pins together but it’s not really going well. I either see 1 bit errors or instant reboots. Most likely It’s just that my fat fingers are too slow and multi-bit error signal handlers get broken as well. Probably the best thing would be to make a simple circuit doing very short pulses.
Third Iteration: back to 2 pins but much more reliable with a switch


I had a joystick like-switch laying around so I used it and the reliability and ease of use is night and day. Hot glue isn’t super secure now I don’t have to fiddle with shorting wires.
This version is good IMO enough to check if 1-bit errors are reported correctly. It’s very easy to use but I will need something better for 2-bit errors.
It is causing instant reboots/freezes when used with ECC disabled - most likely because my fingers are not fast enough and it causes thousands of errors under the hood disturbing not only random data, but also control-flow.
Misc notes:
- A board sometimes fails to post. Most frequenly the reason was too long data pin soldered wires. But sometimes it was simply bad memory seat. Just pushing it a bit harder or reaseating would fix it.
The post codes while this happens are kind funny: “DE” “ED” “DF”, but when watching them going fast I always interpret it as “dead af”