Check your pinning. You seem to be pinning across the NUMA.
Dont know if it helps but you could try.
You could use lstopo to see which CPU id in on which core.
Also make sure you have set you RAM to channel interleaving to expose the NUMA.
1 Like
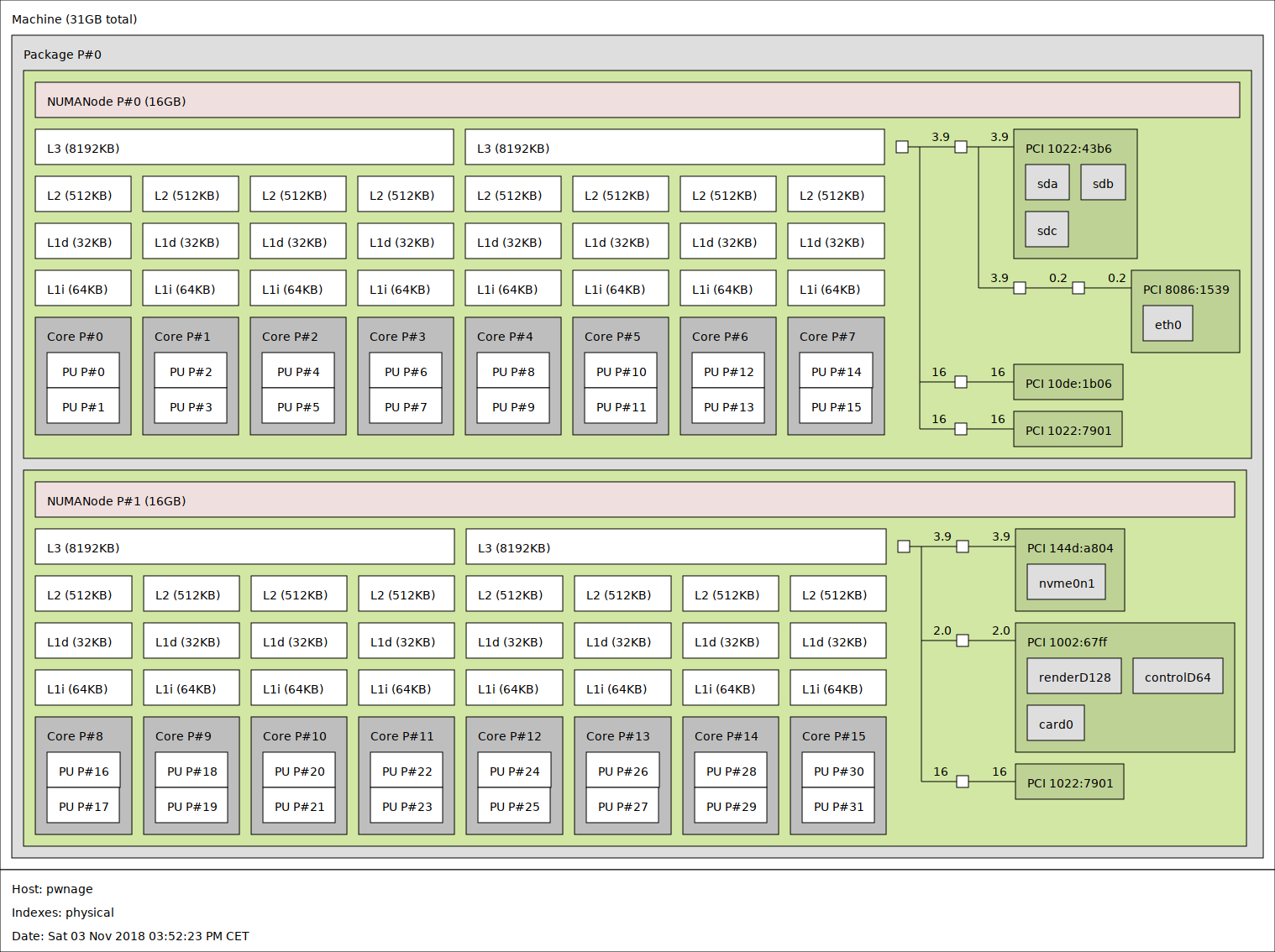
Looks correct to me, but did you also pin the memory via numactl?
numactl --membind=X someProcess
I also bind the Looking Glass shared memory to the same die.
numactl --length 64m --shm /dev/shm/looking-glass --membind=1
And make absolutely certain you have turned off kernel numa balancing, it will literally shuffle the threads around, changing their affinity. And even worse, if you’re using isolcpus it will move them all off the isolated cpus and avoid them.
sysctl -w kernel.numa_balancing=0
1 Like
So lstopo is confusing. Depending -l --logical or -p --physical the map changes.
Now which to use for pinning…
for me it doesn’t change. on both maps, logical and physical, the numbers are identical.
and @pixo they have recently fiddled with it, I think, for epyc? I will ask my contact. As I think the numa layout has changed but I need to verify. Busy with life stuff the last couple months so no time for anything 
1 Like
thanks for info @wendell
hopefully the pining according to physical map is the correct one
just for info, running AGESA ThreadRipperPI-SP3r2 1.1.0.2
I’d say just use coreinfo in your VM to check what Windows sees. For me, It doesn’t know the ‘correct’ cache amounts but at least they’re paired correctly. i.e the cache and hyperthreaded cores are in the correct spots with Windows recognizing them. I’m not an expert, though. So that’s the best I can offer. I still use FIFO on all the passed through cores except one of them, and I’ve yet to crash/lockup yet since that change.
gnif knows more then I do, and I can’t see anything wrong with your config.
The link below has some NUMA memory configuration you can add to your libvirt domain file as they use a Threadripper, too.
https://tripleback.net/post/chasingvfioperformance/
Try adding this under your ‘cpu mode=’ section but before /cpu>
<numa>
<cell id='0' cpus='0-15' memory='16' unit='GiB' />
<cell id='1' cpus='16-31' memory='16' unit='GiB' />
</numa>
Maybe you can find something useful in there that gnif hasn’t accounted for already? Other then that, you could try setting the CPU governor to performance in your qemu hook as well.
With my 1950X the numbers reported by -p seemed to be correct for me (so “core” 0 and 16 are smt pairs), when using the -l number I was seeing large latency spikes which I guess where caused by accessing memory from the wrong numa node.
Won’t disabling NUMA balancing affect performance on the host? Or would you turn it off before guest boot and re-enable it after guest shutdown?
Is numactl necessary when using libvirt, or is this mostly for using QEMU directly? I simply pinned the guest cores to physical cores / threads of NUMA node 1 and use 2 MiB dynamic hugepages managed by numad. It seems to work okay, though I haven’t run any synthetic benchmarks so far, only actual gaming usage.
I’m currently trying to optimize the performance and stability of my 2950X guest. It is quite good already - I get performance that is mostly comparable to a friend’s system with a Ryzen 2700X, but I’d still like to experiment a bit to improve it when possible. For example CIV 6 crashed a couple of times after a multi-hour gaming session, but other times it worked without any issues whatsoever. When looking at htop on the host only cores of NUMA node 1 seem to be used by QEMU which is correct.
Though I have the issue that I can’t use host-passthrough, or Windows won’t recognize threads correctly. With EPYC it correctly sees 8 cores / 16 threads. Could this be a configuration issue on my side?
By the way, it seems like 2950X uses the “old” numbering and not the sequential one, but I will need to check this. I get different lstopo outputs for -p (old) and -l (sequential).
What is your QEMU version?
Only the latest 3.0.0 supports SMT on Zen.
I compiled 3.0.0 as I am using Ubuntu 18.04 - at least for the time being. I have thought about switching to Arch but it will be some time before I can make a such major change.
Might be an issue with libvirt? Haven’t compiled a more recent version of that yet. Maybe I should try running QEMU manually.
Update your machine to 3.0
For q35 it should looks like something this <type arch='x86_64' machine='pc-q35-3.0'>hvm</type>
You dont have to change to q35, just change the version.
I have done both. I’m using the manually compiled QEMU 3.0 binary for the VM and changed the machine parameter in the domain XML (using the Q35 chipset as well).
I am using QEMU 3.0 alongside Ubuntu’s default 2.11, but I specified the 3.0 binary in the libvirt XML. By looking at htop when running the VM it’s actually the one being used.
I wonder if it’s a problem with libvirt, I might need to try using QEMU directly without libvirt to see if the issue persists.
Just found this thread and I’m noticing the same issues on proxmox with my Windows 10 guest. My GTX980 is listed as running under PCIex1 slot, not the correct bus configuration. I’m using the q35 arch type.
Anyone else here using a hypervisor similar or brainstorm how to work this into a proxmox config for my guest to make it closer to bare metal performance?
Certainly it will, but you only have two CPUs to balance between, if you isolate the cores on one die, there will be no balancing required as you have the VM on one, and everything else on the other.
Pinning cores doesn’t pin memory allocation. You might pin all CPU threads to one core, but qemu will ask the kernel for memory which could end up anywhere, including on the other CPU’s bus, making it non local.
Though I have the issue that I can’t use host-passthrough, or Windows won’t recognize threads correctly.
Update QEMU.
Update your BIOS Agesa.
1 Like
This is an experimental thread, wait until this has been fixed upstream in Qemu, there is no “fix” yet.
I figured that as much. I am willing to test things out though. I’ll follow the thread and see what I am able to get to work as it progresses.
Doesn’t numad allocate the memory on the right die if QEMU only runs on one die and asks the kernel for memory? I thought that’s the whole point of using numad in the libvirt config. I realize that there might be some RAM on the other bus depending on the guest config, but generally it seems to work. I went with the RedHat documentation for this: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/virtualization_tuning_and_optimization_guide/sect-virtualization_tuning_optimization_guide-numa-numa_and_libvirt
I’m already using (a self-compiled) QEMU 3.0, that’s why I’m baffled by this.
Thanks for the hint, a new BIOS beta became available recently which I apparently missed. Will report back after I installed it, hopefully later today.
Thanks for your answers, appreciate it a lot as it’s my first time dealing with TR / NUMA.
Updated my ASRock X399 Taichi to the latest beta BIOS with AGESA 1.1.0, but lstopo -p and -l still show the different numbering schemas.