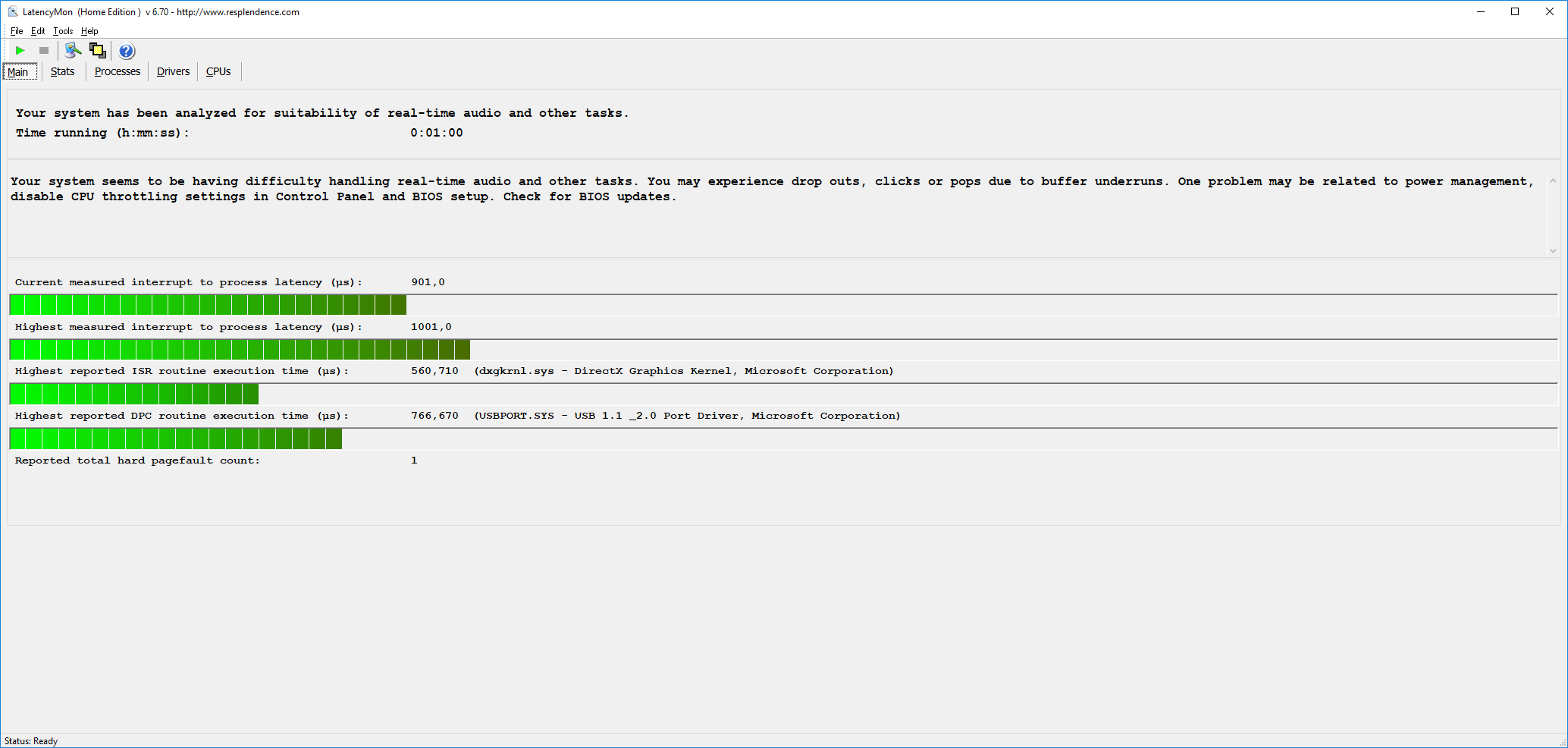
You should set the IRQ affinity to a single core or when interrupts happen on a different core the ISR (Interrupt Service Routine) task needs to be moved to the core the IRQ was triggered on, increasing latency due to L1/2 cache misses. Here is how I set it 
MASK=$(printf "%x" $((1<<$CORE)))
echo $MASK > /proc/irq/$1/smp_affinity
Also make sure you’re not running irqbalance, or set it to one shot mode, or ban it from touching your vfio interrupts, as it will undo any affinity configuration you do. Always check /proc/interrupts to see if your affinity settings are sticking.
watch -n0 cat /proc/interrupts
Or if you want to watch a single core, pipe it through awk. For example, to watch core 13:
watch -n0 "cat /proc/interrupts | awk '{print \$1 \" \" \$12}'
In theory, but if the available local memory becomes sparse/fragmented, the kernel may shift memory to the other die. If you’re going for best latency you want to avoid this at all costs, by pinning it locally if you’re out of local memory instead of the kernel finding more on the other die, it will fault with an OOM error, which is what you want for a dependable configuration.
Also numad doesn’t allocate memory, it simply tries to keep all the memory and threads of a single process local, on the same die. When allocating such huge chunks of RAM for a guest VM, it is best to be as specific as possible, no matter what virtualisation software you’re using.
It will attempt to locate processes for efficient NUMA locality and affinity, dynamically adjusting to changing system conditions
The dynamically part is the issue, at any point in time it may shift the allocated ram to the other core if for instance another process on the host needs more ram and it’s out of local ram on the other die.
Also AFAIK at current Qemu doesn’t support NUMA natively, it only supports CPU pinning, and as such when it allocates the guest’s RAM from it’s primary thread at startup, affinity has not yet been set as it’s not a CPU thread and it may be allocated to the wrong die. I can confirm this for LookingGlass’s shared memory, which is why I pre-allocate it using Numactl before starting the VM.
numactl --length 64m --shm /dev/shm/looking-glass --membind=$NODE
chown qemu:qemu /dev/shm/looking-glass
 it’s good to see that the bus speed issue is finally being resolved.
it’s good to see that the bus speed issue is finally being resolved.