Hi folks,
I’m planing to fine tune OPT-175B on 5000$ budget, dedicated for GPU. I want to use 4 existing X99 server, each have 6 free PCIe slots to hold the GPUs (with the remaining 2 slots for NIC/NVME drives). Thermal management should not be an issue as there is 24/7 HVAC and very good air flow. Electricity cost is also not an issue.
The problem is, I have trouble deciding on GPU to buy. These are the options I have at hand:
Mass P40 at 200$/each, total 24 cards. This would give 574GB, 282TFLOPs FP32 cluster.
Mass MI25 at 75$/each, total 36 cards. This would give 574GB, 442.8TFLOPs FP32 cluster. The additional 2 X99 servers would roughly cost the remaining money (2300$).
The issue with MI25 could be architectural or OOM at a single device.
What options should best fit my use case? Did I overlook any better deal?
edit: Found this, which contains results for a lot of GPU
I dont know what your long term plans for training are but this is gonna take a long time on hardware without matrix acceleration i.e. tensor cores or WMMA. This guide may help
If the goal is to test a theory, you could go for faster feedback & avoid hardware till your forced too. Renting some a100 80gb cards, like in this project. They fine tuned a model via LoRa in 24hours a total cost of $300 for two models in 7b and 13b.
I don’t know if you have looked at the Tesla P100 but it can be had for the same price as the P40.
I got lucky and got my P100 and P40 for 175 each free shipping plus tax.
I just saw 10x P100 for 180$ each plus 5$ shipped and tax but had a make offer too.
The P100 should be faster at ML than the P40. I use mine for folding@home and the P100 walks the dog on all my other video cards, list: Titan X Pascal, 4x M40, 2x K40, GTX1660, 2x GTX 1060, P40 and others not worth naming. lol
This is for people reading in the future, you need qLora or tensor cores for training else enjoy waiting months for a result.
The model in question needs 350GB GPU of memory just to do infrence with the OPT-175B model. Training also has its own memory overheads that blow this out further.
Thank you for the replies! The purpose of the machines are for our AI club at my university. We are looking to buy the hardware instead of using the cloud as it would be more economic since our members will use those machines for different tasks after the project. Running time isn’t so big issue as long as it is under 20 days.
For the P100 suggestion, I think that is a good one. However, I can have 3060 for 220$ each shipping included. In fact I am using x4 of them on my server at home. Speed-wise I have no idea which will win because while the 3060 have tensor cores, the P100 have HBM memory and thus have double the memory bandwidth compare to the 3060. Probably the 3060 would win in this task but for other task I am uncertain. Unfortunately they are 12GB so I would need to buy more of them to be able to run the model.
The larger memory of the P40 is the main reason why I have overlooked the P100. However, as you said, speed tradeoff might not worth it.
Tim Dettmers recommended used 3090/3090Ti for transformer task and I think that one is also very good. However, they will cost me ~700$ each. With this money, I could theoretically stack up 3x 3060 and obtain more aggregated speed/memory as each 3090 is only twice as fast and memory as a 3060. I would not mind connecting more servers to the Infiniband switch.
You will have more aggregated memory, but not speed. Speedups from stacking cards will highly depend on how much communication there is between the partitions of the model. With 3 cards on X99 (and apparently some IB card), I guess you’re limited to pcie 3.0 x8 for inter-card communication.
The 3090 would keep slots open if down the line you would add more, keep pcie bandwith for CPU/IB communication, and allow you to use nvlink for dual 3090 setups with much faster inter-gpu communication.
Just food for thought; to know for sure you’d probably need to benchmark both systems.
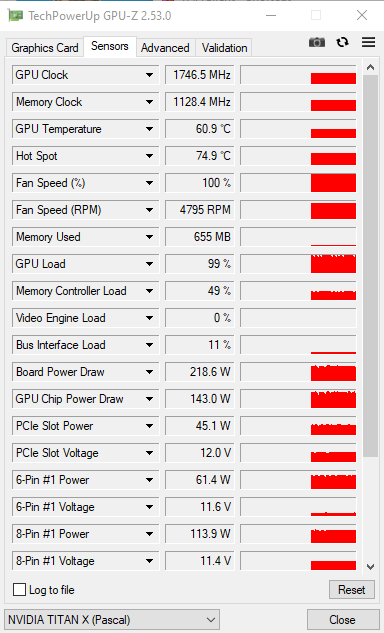
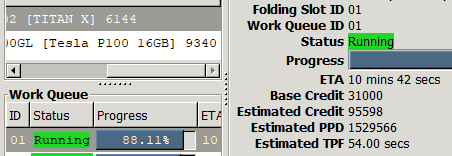
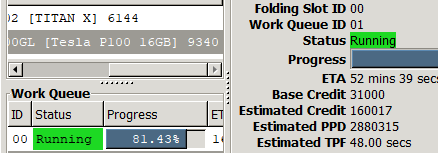
Here are the three doing the same F@H work unit, I have a 3060 XC Gaming 12GB The P100 outdoes it but can’t be overclocked so it’s all stock speed. Whereas the 3060 is OCed and can’t keep up on this task. Not saying the p100 is the best bang for the buck at 185$ but it also outdoes my Titan X Pascal OCed. From my testing 3060 and Titan run about the same in F@H on the same projects. Now 3DMarks is another story Titan X gets better scores in Time SPY and Fire Strike than the 3060 or p100 with the other hardware used in these tests. I got the 3060 for 187.00 shipped with tax.
These projects use Cuda so mileage may vary in other usages.
Best to just keep checking to find what will work best in your use case and budged.
Wattage pull is another thing to look at well unless you don’t pay the power bill that is. lol
Edit: the TPF=time per frame is what to look at in the lower SS. 3060 bounce between 54
and 55 seconds were as the Titan holds 54s. P100 at 48s doesn’t seem like a big jump
but it’s 8 to 10k points jump over the other two per work unit so every 24hrs that can be a big difference in the final results.
Yes we need to benchmark the system to be sure which will be faster. But in general, I can accept some speed tradeoff for more aggregated VRAM as long as the slowdown is under 50% (2x time required for the task) between choosing the 3090 or 3060. This is because being able to run some task is more important than not being able to run them after all, despite having to spend more time.
Abit_Wolf thanks you for the benchmark! I don’t know what kind of computation does Folding@Home does. Is that half, full or double precision? The memory utilization seems quite low for the Titan X Pascal and very high for the 3060. Does this mean the 3060 was using tensor cores so most of the time it was waiting for data to arrive from the memory controller? By the way, I think I have read somewhere that scientific computations usually use double precision. If this is true then the Tesla will beat the others by a large margin. However, it don’t seem to be the case for this benchmark.
I have also performed some search and found this thread on Reddit, which also discuss something close. Last time I saw MI60 on ebay it costed ~550$ or so. At that price the 3090 with tensor cores would be much better for training. They probably was talking about inferencing, which is a different task.
Unfortunately, I do not live in the US or Europe so the cost for these devices are much higher than usual. One bright side is that the school will pay for all electricity usage as well as HVAC so I don’t have to worry about these factors.
[quote=“hotfur, post:8, topic:197140”]
use double precision
[/quote] This is a few years old and could be different today with updates to the core 22. I really don’t know I haven’t been keeping up with what is going on for a few years. As for the 3060 I can’t say as I’m not sure how I would be able to see if it uses tensor cores in these projects. I kind of doubt it is as F@H is usually late to the party with new Tech on their software end of things.
P100 has no tensor cores so it probably is best to get something with them to future-proof for your project. Edit: I forgot to say that the Titan X and P100 are in the same rig so there is also a possibility they are fighting for the same resources slowing each down just a little bit.
I had posted in this thread some thoughts and experiences but I dont think they are at quite the scale you are looking at
If you are putting these GPU’s into servers, then you really need to make sure you are getting GPU’s with blower style fans, not “gamer cards”. This is really important especially if its gonna be running for a long time.
You are generally better off getting the most recent model cards possible with the largest VRAM per-card. AFAICT, fewer beefier cards with larger VRAM are better than more numerous smaller cards with less VRAM.
You do not want RTX 3090 Ti, only the 3090 (blowers if possible, as I described here).
I seriously doubt that you are going to be able to do anything with RTX 3060 12GB besides just running small LLM models, or running Stable Diffusion, etc… I would not expect them to be useful for training.
Honestly I think you need to more seriously consider cloud for this. I do not think its gonna be economical to go bare-metal for this purpose.
I will be using pcie 3 x16 risers and powerful fan solutions so in general I don’t really care about what kind of stock GPU cooling I got.
It is true that an 3090 could be faster than 3x 3060 at same price but I would have got more aggregated memory with 3x 3060. I don’t know why you think stacks of 3060 would not train well. Have you used DeepSpeed ZeRO for training/inference on multiple-gpu/multiple-node?
If I only have to do this task once, I would have considered cloud. But we are not looking to do it once as our club members would likely be using the cluster 24/7 to train more models (of different architecture) after this task is finished. Therefore, cloud is not economically viable.
This is a bit after the last response…
x99 has 40 pcie lanes max per CPU. So 5 cards max at 16 lanes not including any other add in cards or how the motherboard routes connections (4 more likely unless 8 lanes are used then 8 cards max per cpu). x99 is also pcie gen 3.0 meaning you will have some degredation in performance with Nvidia 3000 series that is gen 4.0.
My very limited test testing gen 4.0 vs gen 3.0 with 16 lanes was 10% drop in some applications but milage will heavily vary. My tests were more gaming oriented.