Hi there, I am not really an active forum participant, but I’ve been watching L1T for a few years now, and this year I decided to enter the Devember challenge with a project of mine that I’ve been prepping for a while now.
So what’s UM exactly?
Well… ummm… it’s my take on computing. It is inspired by the slew of weaknesses, limitations and design flaws that riddle software all the way from programming tools to end user software.
How is UM different?
-
It is not text based - compiled or interpreted, it more or less works directly on raw memory, with some basic safeguards
-
It must be usable through any generic input means – keyboard, mouse, touch, and further down the line – voice, for the lazy and those who suffer disabilities
-
No syntax means no syntax errors, logical errors are still possible, but must never result in crashes for all “design time constructs”, only graceful failures
-
It is designed with efficiency in mind, the design goal is to provide good user experience even on affordable phone and tablet devices
-
It must lower the bar of hardware requirements, so that even those who can’t afford powerful laptops or desktops can be productive with it, and I mean on the actual device rather than some front end to a web service
-
Its base ABI must be portable across every contemporary platform type and dependency free, with modest core requirements – 32 bit integer support and heap memory allocation, basically everything all the way down to MCUs
-
It is based on a few primitive built-ins, which can be used to create compound user types on the go – there is no compilation necessary
-
It must be almost entirely programmed within itself, there should be a very minimalistic pre-written core, which also means you can easily implement or extend language level features
-
It is not just for programming, as the “Universal” part of the name should imply, initially yes – but the plan is to extend it into a whole ecosystem for products and services that enable various benefits that computing can provide. You know… much like how there is quite a lot of benefit to being able to speak and write, outside of being a professional speaker or writer
I do realize all this sounds overly ambitious, especially for a single dude to implement, but I’ve been contemplating this, learning, practicing, researching and testing various components of it for nearly 10 years now. My primary language is C++, although I am fairly proficient with C and JS as well, I’ve also analyzed a number of other languages.
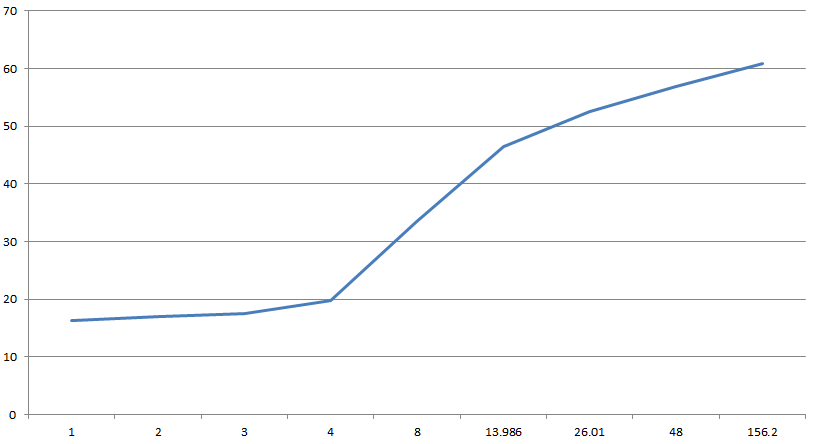
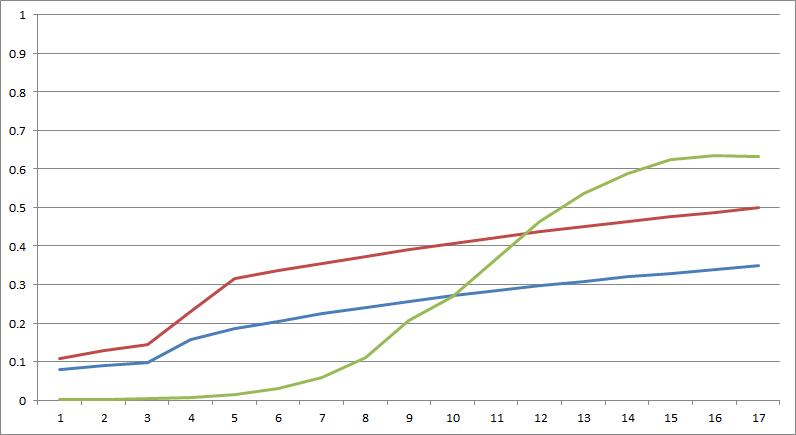
Here is the gist of my findings to disagree with – featuring two representatives of 3 language groups – the powerhouse old timers, the declining mid-rangers and the popular kids, 6 languages in 6 key metrics, focusing user friendliness in the top area, and hardware friendliness in the bottom:
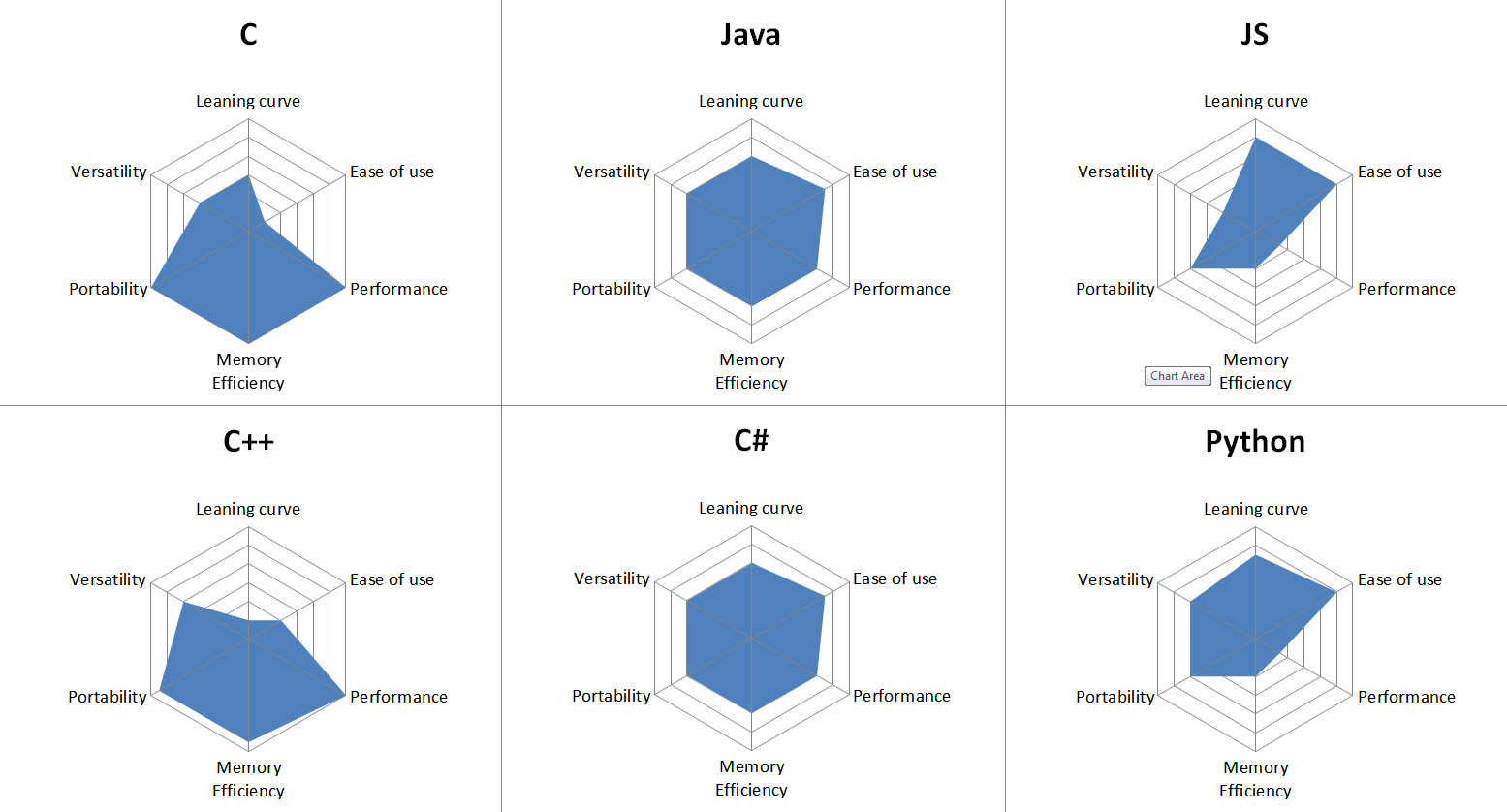
Obviously, stuff like that is somewhat subjective, and there is no need to start a language war here, but I think everyone sufficiently competent can agree that:
-
C and C++ are performance kings, but that comes at a cost – they are quite tedious to work with, for those that know or can imagine better. C is rather simple as a language, but its usage idioms require a lot of boilerplate, since it lacks any high level features. You can write almost anything in C, but for the vast majority of tasks, C is actually a very poor choice. C++ has been trying to improve on that weakness, as a result it has gotten horrendously complex, and I don’t mean the basic stuff, I mean learning the language in its entirety
-
Java and C# IMO are the product of two different companies and the same motivation – to address the weaknesses of C++, and they did manage to provide a balanced solution with fairly proportional trade-offs, and for a long time they were very popular, but recently have been losing to even easier and more user-friendly languages
-
JS and Python are two of the most popular languages today, something they owe entirely to their ease of use, that unfortunately came at the cost of terrible performance and efficiency, to the extent they are not at all applicable for performance critical stuff or resource constrained platforms.
Also note that there are also many other important aspects to programming, those are just the basic fundamentals. And yes, there are many more types of languages, and newer ones that are quite promising, Rust being a honorable mention that does solve some of the C/C++ problems, but IMO not enough.
My design goal for UM is to basically fill the hexagon all the way. My research didn’t identify any technical reasons for the trade-offs between different metrics, but rather unrelated design choices, and I consider it practically feasible to design a tool that checks all those marks, and then some.
Obviously, it is totally unrealistic to expect to UM in its entirety in a little over a month, so here is my list of functionality that I think is doable:
-
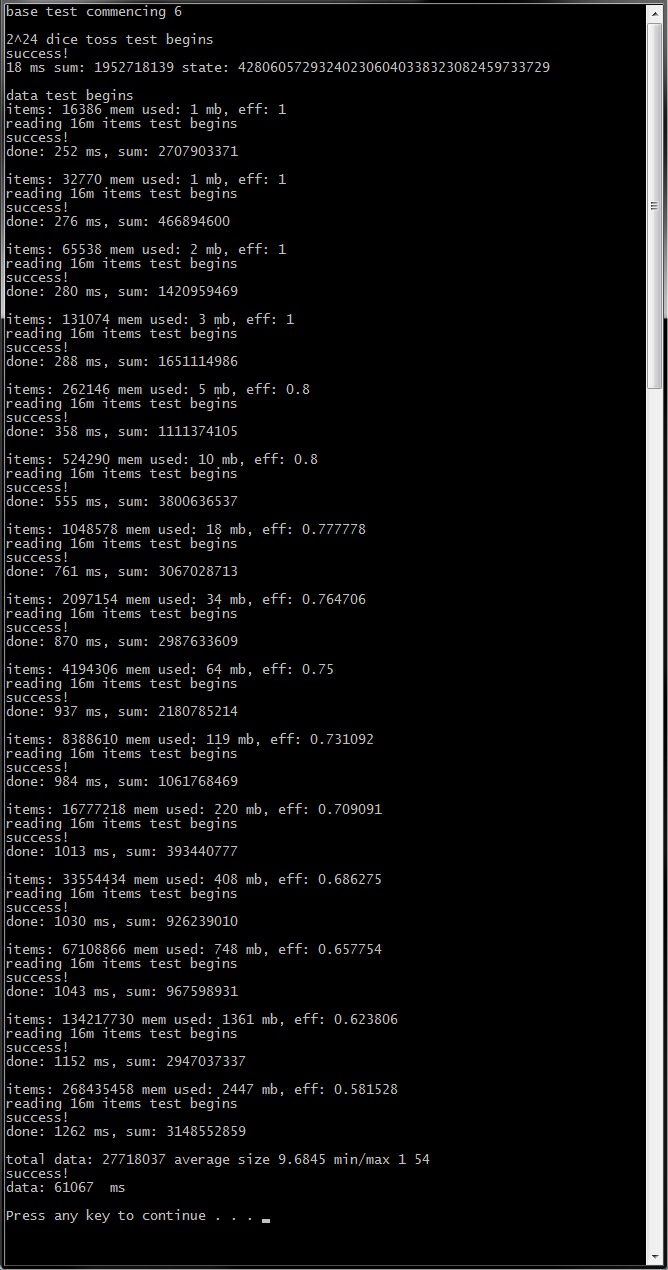
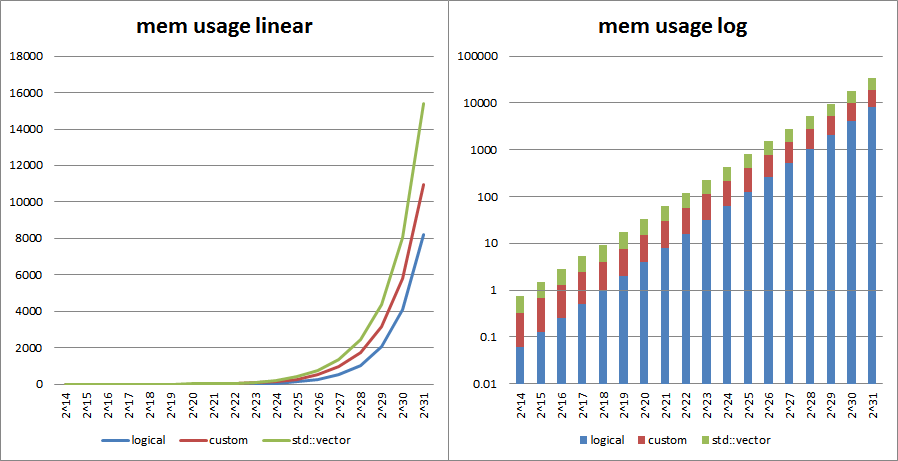
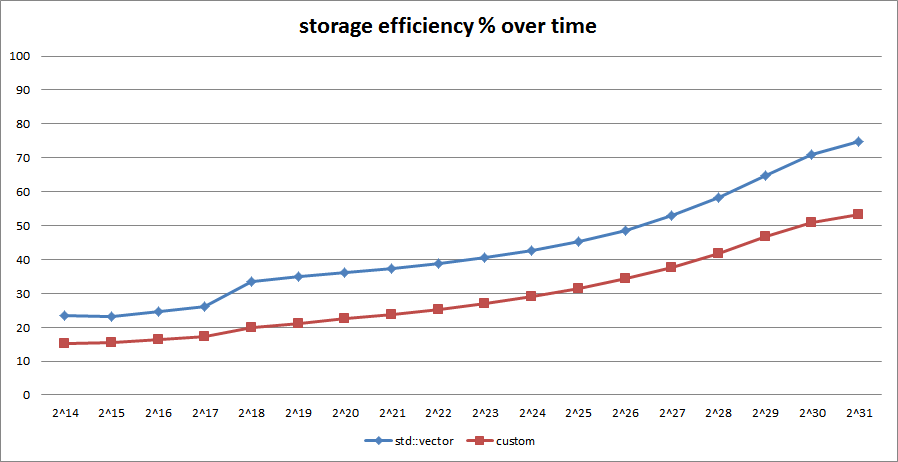
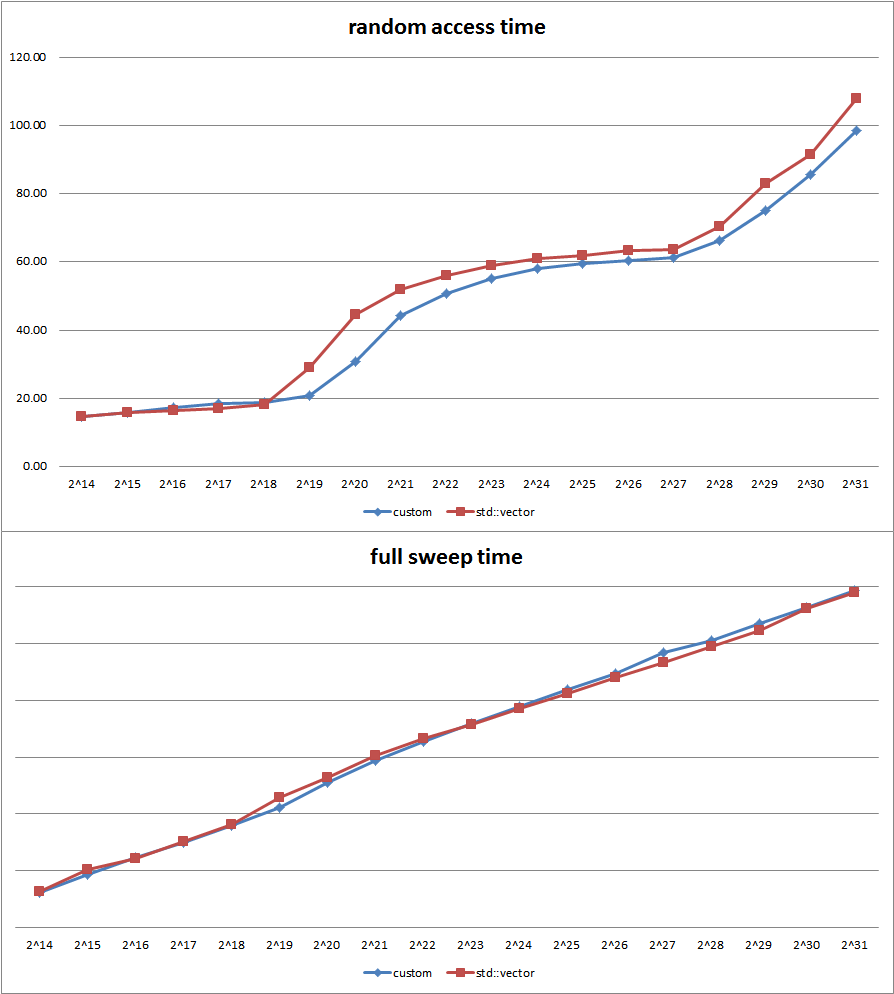
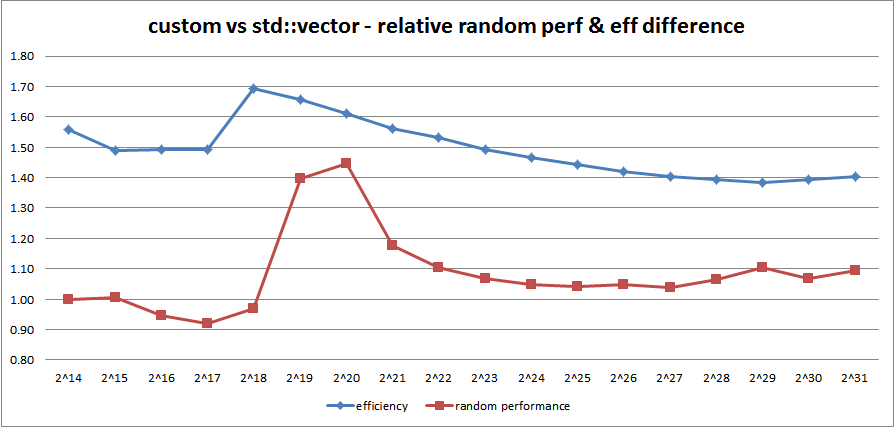
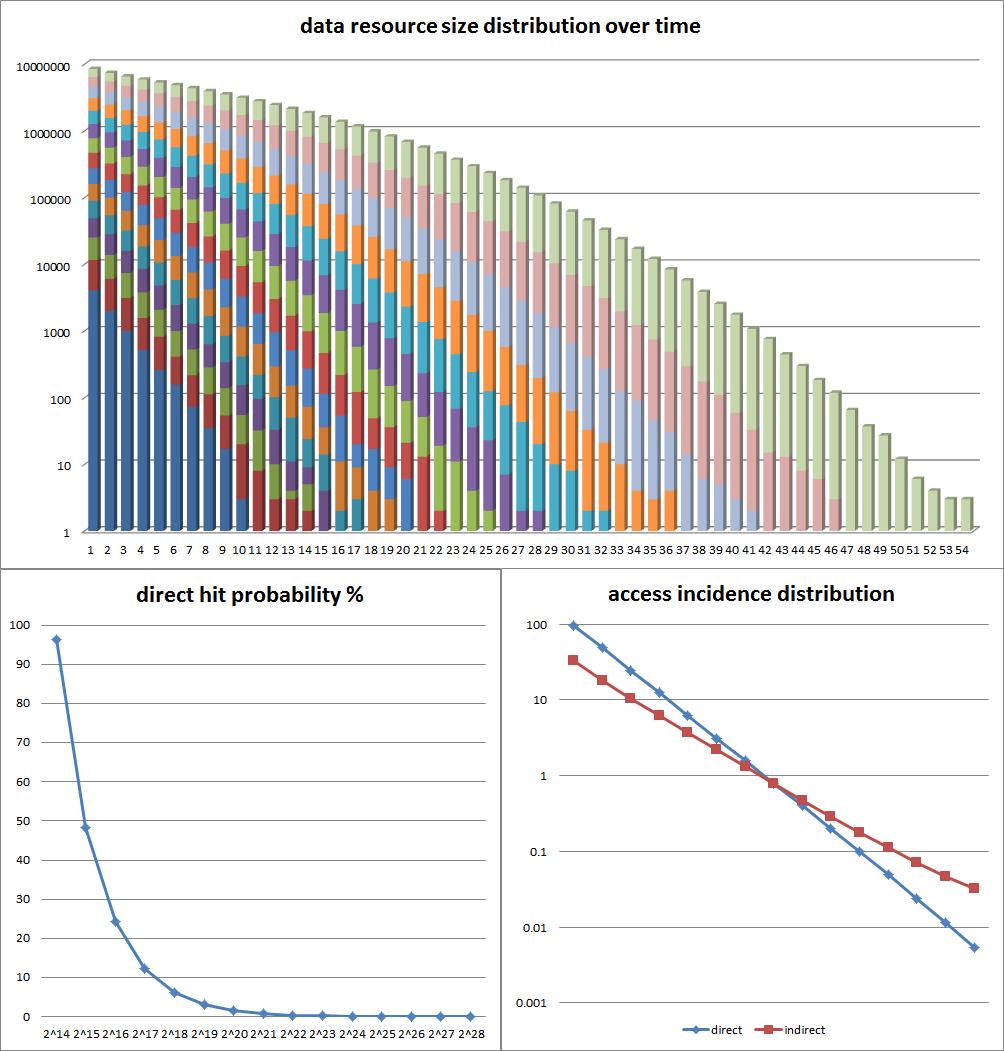
Implement the Default Data Engine – this is basically a glorified container of data resources with unique and persistent across sessions IDs. It is a custom design, optimized for both memory efficiency and look-up performance, plus some integrity stuff. It can contain up to 2^32 number of discrete data resources, each of which can address up to 16 gigabytes of memory, for a total of up to 64 exabytes of theoretical addressing space
-
Implement the Abstract Object Model – the set of logic that defines and structures data resources into traversable object trees
-
Write extensive tests for DDE and AOM – for both performance and stability
-
Implement a basic GUI for user interaction, until the project reaches a state it can produce its own and more feature-rich GUI
-
Implement a minimal set of built-in primitives
-
Implement the static core language types
-
If there is still time, implement the Pooled Data Engine – an abstraction that works on top of the DDE to further improve efficiency for short data resources
Note that there won’t be any code initially, not until internals are thoroughly tested and finalized. The source will become open when the API is complete and stable, and the project is ready for contributions. Due to the nature of the project tho, I do not expect a lot of contributions to happen to its written code base, but rather internally, through the tool itself. The initial C/C++ code base will eventually be re-implemented in UM as well.
I will provide progress updates, test results, case studies and even binaries to run tests and benchmarks. I will need help testing things at scale, because my system has only 24 gigs of ram.
I will try to provide an alpha release before the end of November and a functionally usable beta version before the year ends.
Now back to work, I will come back when there is progress to report.