Hardware engineer here joining in, longtime lurker but you might recognize ‘UnexpectedSpud’ from the Twitch streams. Probably not. This one’s not really a software project but hopefully someone finds it interesting… it’s been a pet project for a long time but I’ve never mustered the motivation to do anything beyond some back of the napkin theorycrafting until now.
The ultimate goal is to design and implement a single-cycle (not pipelined) transport-triggered-architecture processor core. Put simply, this means designing a CPU with one instruction: MOVE. The whole thing, from the ground up.
The design will be implemented in VHDL and targeted at an undecided FPGA, for which I intend to spin one board for the processor module itself (core, memory, system bus interface) and another to act as your traditional motherboard for the platform and provide enough I/O for demonstration, probably ATX form factor. Sounds like a lot of work but with my own pre-existing board component libraries and the wonders of modern FPGA hardware, I think it’s realistic in two months. Only issue might be the turnaround time on JLCPCB’s $4+shipping board runs, but we’ll cross that bridge when we reach it.
Here’s the executive summary:
Deliverables:
Hardware:
- Processor Module CCA
- ATX I/O Baseboard CCA
Software:
- Processor Core Bitstream/VHDL Package
- Machine Code First Stage Bootloader
- Machine Code I/O Demonstration Payload
Documentation:
- Theory of Operation
- ISA Datasheet (Instruction set, etc)
- Block Diagrams
Goals:
-
Half of the work here is just getting a modern FPGA to configure itself. Between power requirements, timing requirements, configuration protocols/etc, it will be nice to finally pile together a generic reference design for my own use in future projects that need an FPGA.
-
I’ve never really version controlled any of my personal projects. I intend to take that a bit further and learn about how to actually set up a continuous integration (probably Jenkins) and version control (probably SVN) environment for myself, since the only other experience I have with the matter is from Git memes and one employer’s halfass TeamCity deployment.
And then maybe for next year’s Devember I can do an assembler and/or compiler in C, but that’s way beyond what I can handle in a little over two months.
Godspeed, gentlemen. More to follow.
8 Likes
(Yeah, this will get updated once hell freezes over at this point.)
Development Log can be found at http://www.winterstorm.com
I’ll bump the thread whenever major updates go up, but otherwise all details will be over there!
3 Likes
You’ve got my attention =P
How will you implement an ‘exchange’ instruction? That is exchange a value in a register with a value in memory? These are needed to implement semaphores. And have to execute in one cycle. If you don’t have one then you can not have non maskable interrupts.
Yeah, there’s going to be a massive information dump in the next couple days… I’m putting together a quick HTML site now with all the info/dev log that I’ll just host on an old parked web domain + link to instead of blowing up this thread.
Keep in mind, this is going to be a pretty basic processor core - think like the old MOS 6502. Direct linear memory addressing, no cache, no hardware multitasking or permission levels. I have some ideas for adding things like that in the future, but for now I’ll be happy to have something working at the end of December. Start small.
An ‘exchange’ will be a load+store+move, not monotonic. The way I have it laid out on paper: there’s a single interrupt vector with a queue of identifier tags which indicate the interrupt source. There is no nonmaskable interrupt vector… this core itself doesn’t generate interrupts; there isn’t a counterpart to the x86 exception/trap.
The nice part of building something ground-up from the gate level is that I can disregard programming paradigms that exist right now and make my own. In this case, until I add a lot more hardware complexity, the software/kernel is going to be responsible for basically everything. We can deal with that next Devember haha
2 Likes
Alright, the Dev Log’s up - nothing there yet, but I’ve updated that reply I reserved up at the top with a link.
Have had a domain name idling for a while now, so I decided to spin up a Linode and unpark it. Figure it’ll work out better to info dump over there instead of blowing up this thread every day.
2 Likes
First couple pieces of documentation are up.
I’ve just learned a valuable lesson on cache busting after wondering why nothing was actually updating on the Dev Log page. Spent a solid two hours trying to get Apache to acknowledge the .htaccess file, which was fun. Everything’s in good working order again.
1 Like
No updates for the last couple weeks, since I came to the realization that I was spending far more time redrawing documentation than I was actually accomplishing anything every time I made a conceptual improvement.
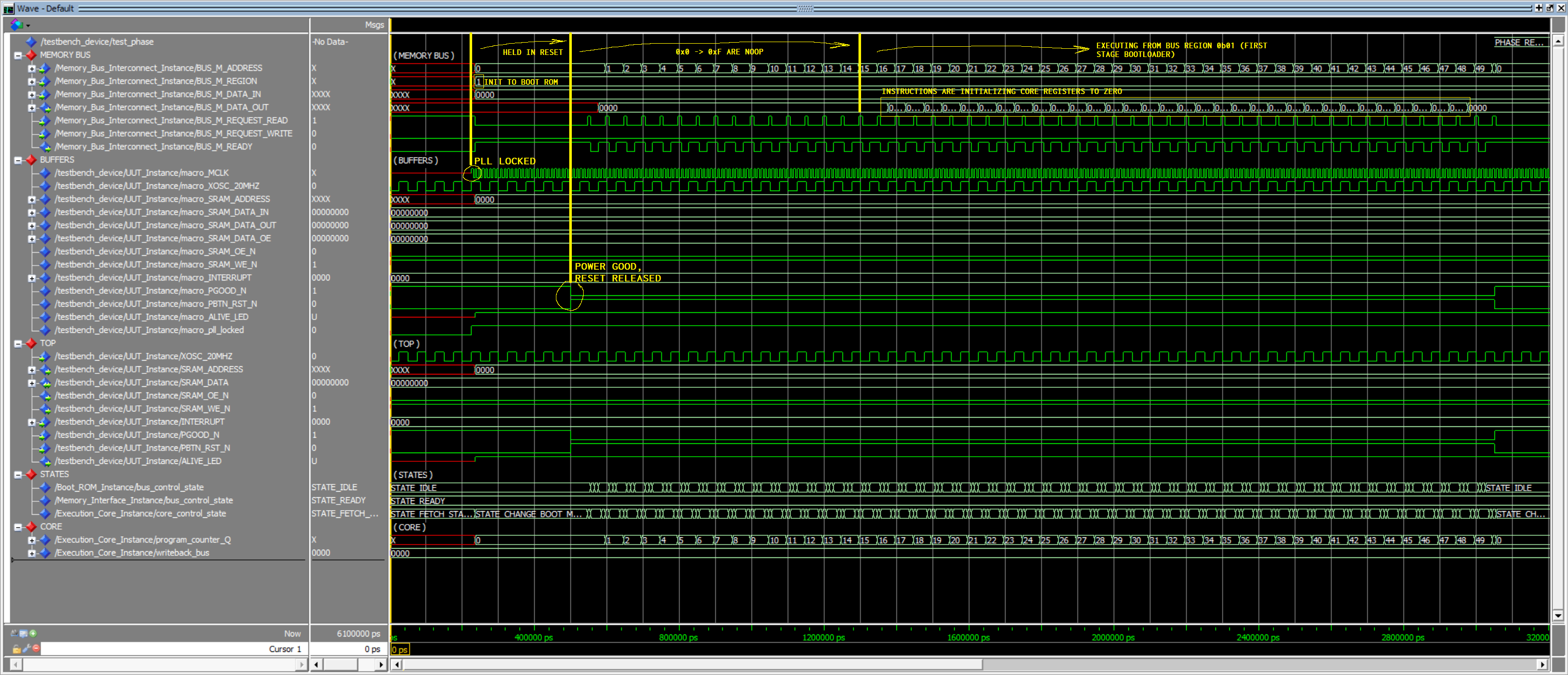
In large part, the processor core itself is done and I’m going everything uploaded w/ commentary over the four day weekend here.
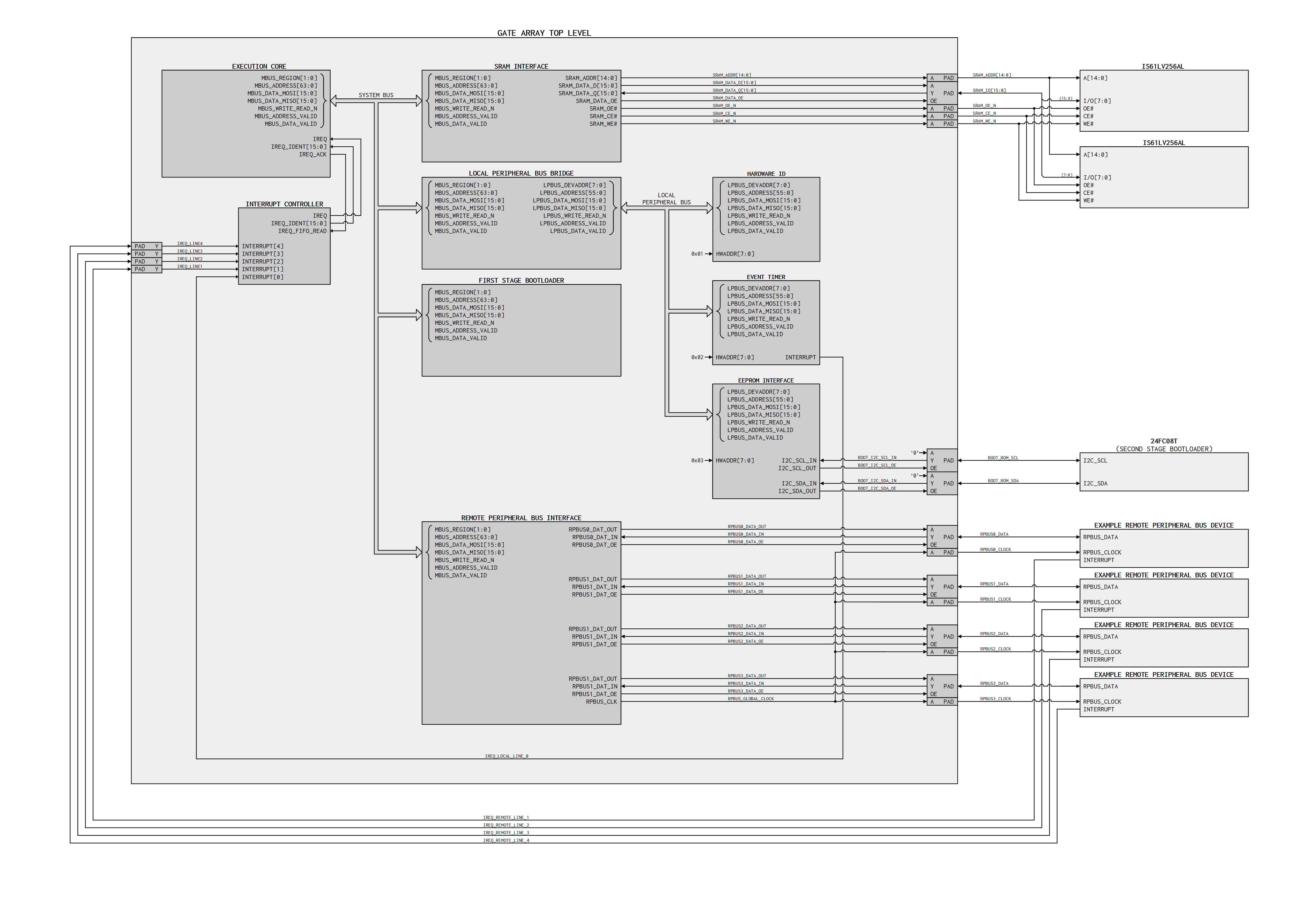
^ That simulation isn’t really going to mean anything to anyone yet, but you’re mostly looking at the top-level system memory bus (which connects the core to the main memory controller, bootloader, local peripherals, and remote I/O bus… shown is the bus port into the execution core) and I/O buffers. Just know that it starts up and reaches the first stage bootloader, which is currently nonexistent.
No activity at the top level pins, because the first stage bootloader is a chunk of 256x16b entirely in FPGA fabric; its job will be to load the second stage bootloader (equivalent to the x86 BIOS) from an I2C EEPROM, but that machine code isn’t written yet. It has a 32kb (1k x 32) write-through cache, but there aren’t any read/writes to system memory to show yet, so it’s just idling.
I’ll probably get the PCB put together first so I can write that bootloader while it’s in flight, but first I’ve got three weeks of progress to get documented. 
2 Likes
Here’s a quick overview of the instruction set:
Words are 16 bits, and so each instruction word is in the form of 0xSSTT, where SS is the source address, and TT is the target address. Let’s say you want to add the contents of general purpose registers 0 and 3 ($R.0, $R.3), and then branch to the address in general purpose register 7 ($R.7) if the result is zero:
R.0 -> ADD.A // Move R.0 to Add Operand A
R.1 -> ADD.B // Move R.1 to Add Operand B
R.7 -> GA.0 // Move R.7 to Global Address [15:0]
ADD.Y -> BR.0 // Branch if ADD.Y == 0
…which translated to machine code looks something like:
0x0A01
0x0D02
0x111C
0x0120
3 Likes
Thanks for the post, I understood your example. So the “address” is not purely an address but it acts as data/instruction based on its position and its value.
Does the compute happens while reading (the source) or does there exist two sets of register (one for each Source and Target with same address) and compute happens in every clock.
Yep, that’s correct - ‘address’ might not be a good term for it, I’ll see if I can think of a better way to describe that.
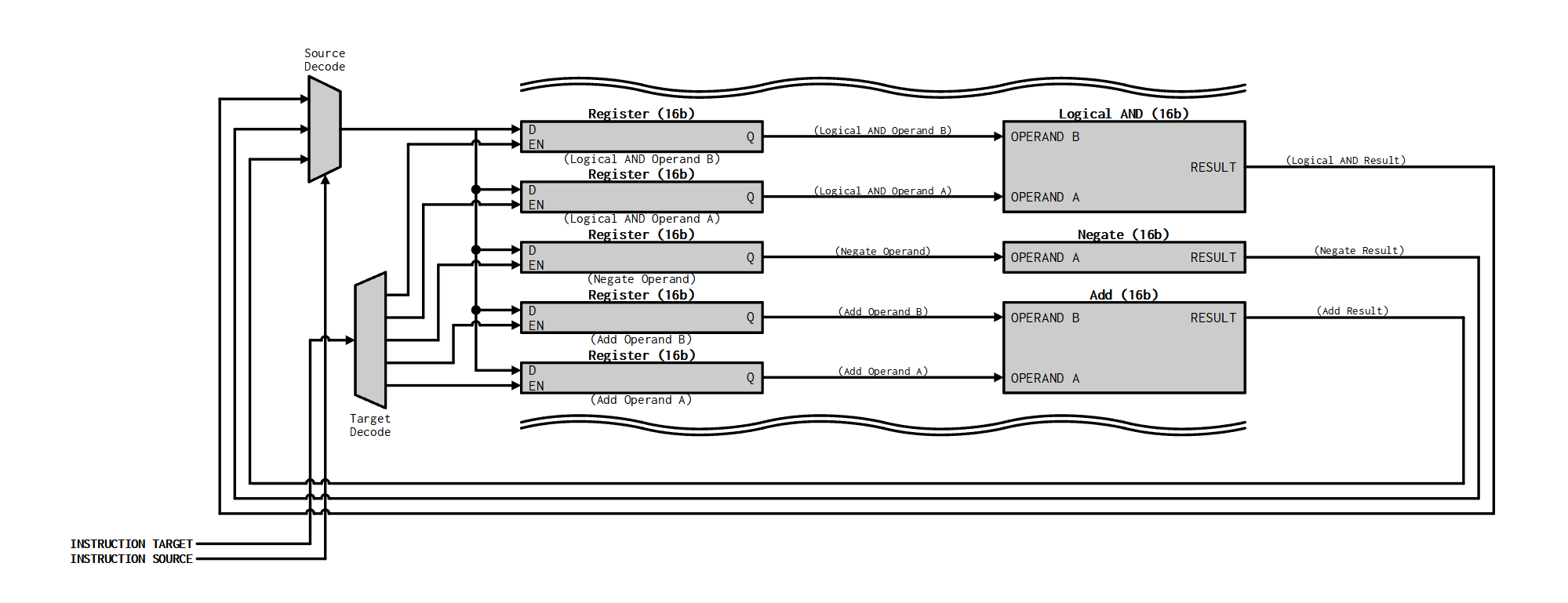
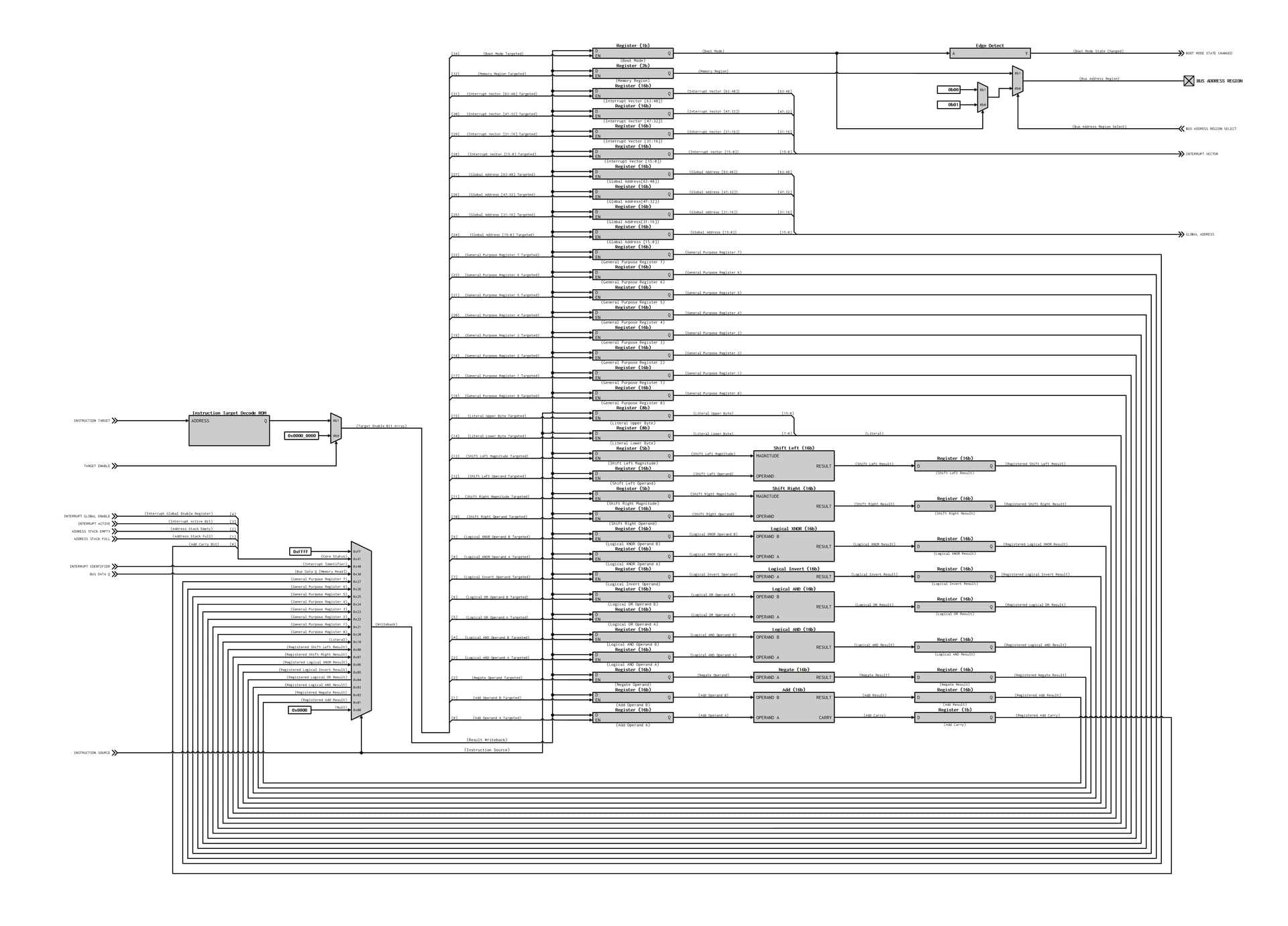
Here’s a simplified snippet of the core’s datapath:
The way it’s written, all calculations execute in parallel on every clock, but there will only be one register which is written to on any given clock. I guess a better way to put it is that one calculation is updated and all others will hold their value on every clock.
Each target is usually a register (‘control’ targets like branch/jump don’t actually hold anything)… the enable signal to each of these registers is decoded from the instruction target field. The registers are all hardwired to their respective functional blocks. The results from those functional blocks are returned through a single massive writeback bus that’s a few hundred bits wide into a multiplexer which selects the data being moved, which is selected by the instruction source field.
The really nice part about this architecture is that it’s extremely easy to add new instructions/operations - just put another set of target registers on the bus, give them an ‘address’, and add the output into the source decode mux. Because adding new operations only adds more width to the datapath and doesn’t make it longer/slower, there is only a small hit to performance from making that big source decode multiplexer larger.
So, here’s what the holdup has been:
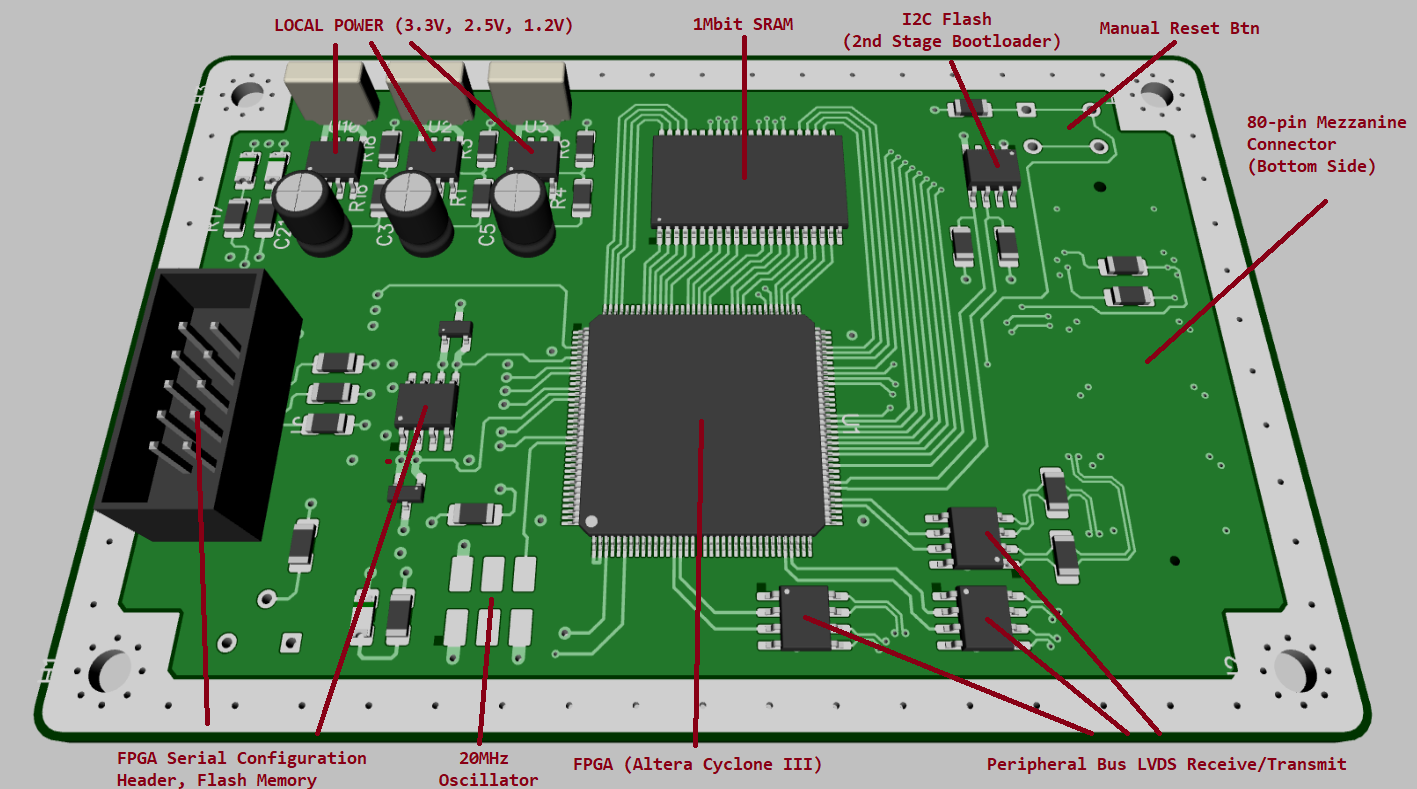
The netlist check is done; I need to make the silkscreen look nice, add some sort of identification/revision text in the top copper, and it’s going out to JLCPCB to start production and should be here in 5-10 business days. Because a 6.7x6.7" ITX 4-layer board bumps the price from $4 to $60, I’m just going to throw together something small to break out the pins on the 80-pin mezzanine connector (not pictured, Amphenol BergStak header) for the first round of development.
Labels for anyone interested:
2 Likes
Welp it’s gonna be a close one - nothing left to do now but to write the first stage bootloader and clench as the two boards are fabbed. Moved some things around so that this whole assembly can still be useful after Devember is done.
Software development time while we wait. I’ll need to write:
- First Stage Bootloader (“1SBL”) - embedded in ROM, only function is to poll all bus devices if they are 1) present, 2) alive, and 3) contain a valid second stage bootloader image, and then copy that image into memory before rebooting from the 1SBL ROM region into the primary system memory region.
- Second Stage Bootloader (“2SBL”) - contained in an onboard I2C flash IC, comparable to the BIOS on an x86 system. Finds, loads, and executes the OS kernel. In this case, the 2SBL is just going to be a small chunk of diagnostic code that will respond over a serial port that the CPU is alive and the 2SBL was successfully executed, which is the arbitrary point at which I’m calling success.
2 Likes
Ordering parts has been fun:
-
There are no FPGAs in existence right now. This whole thing was originally going to be on a Lattice MachXO2 (they’re super easy to use), but there are none available and lead times are pushed out until the middle of next year at the earliest.
-
Development board prices are jacked to the tits. After seeing the Lattice FPGA situation, I was going to grab a Digilent Spartan6 CMOD (FPGA on a little DIP-48 breakout board) - the MSRP used to be $35; they now retail for $90. So, I’ve rejected all of the above and just rolled my own since I have a few old Cyclone III FPGAs on hand.
-
The LDO regulator inventory has gone to hell. Unless you can make do with a '1117 or are willing to pay $10+ for a single Analog Devices IC, good luck.
-
Why are all of the 0.1" pin headers gone?! Yeah you can still find what you’re looking for from some random manufacturer if you look hard enough, but it’s nice to have same product line (eg TE BergStik/Wurth WR-PHD/etc) and not just slap whatever you can find on there.
-
Solid polymer electrolytic caps still exist but are anywhere from 100-350% marked up now.
Welp, here’s the dev board, in all of its mostly assembled glory:
Just a serial port, two EEPROMs, a couple buttons, and some memory hanging off of an FPGA. Unfortunately, my brilliant ass missed a couple of odd resistor values in the BOM that were for the 1.2V and 2.5V rails’ feedback, so that’s where the demo hardware is gonna wrap for now. Trying to power it up without those rails would just blow the FPGA up.
I’mma finally get around to uploading the firmware, schematics, block diagrams, and the bootloader over the weekend here. And, even if it’s not for Devember I’ll still be working on this and will post updates as I have them.
7 Likes
Wow! Amazing work. I’ve not been following your project as much as I wanted because I have been working on my Masters dissertation and starting a new company. So I just checked in and OMG! I am seriously impressed at the amount of work you have done. Mind blown.

I’ve been updating block diagrams as I go through and clean up the RTL/check it into the SVN repo. I’ll post them here as I get them fixed up. You’ll have to open image in new tab because they’re huge.
FPGA Top Level
Core Datapath
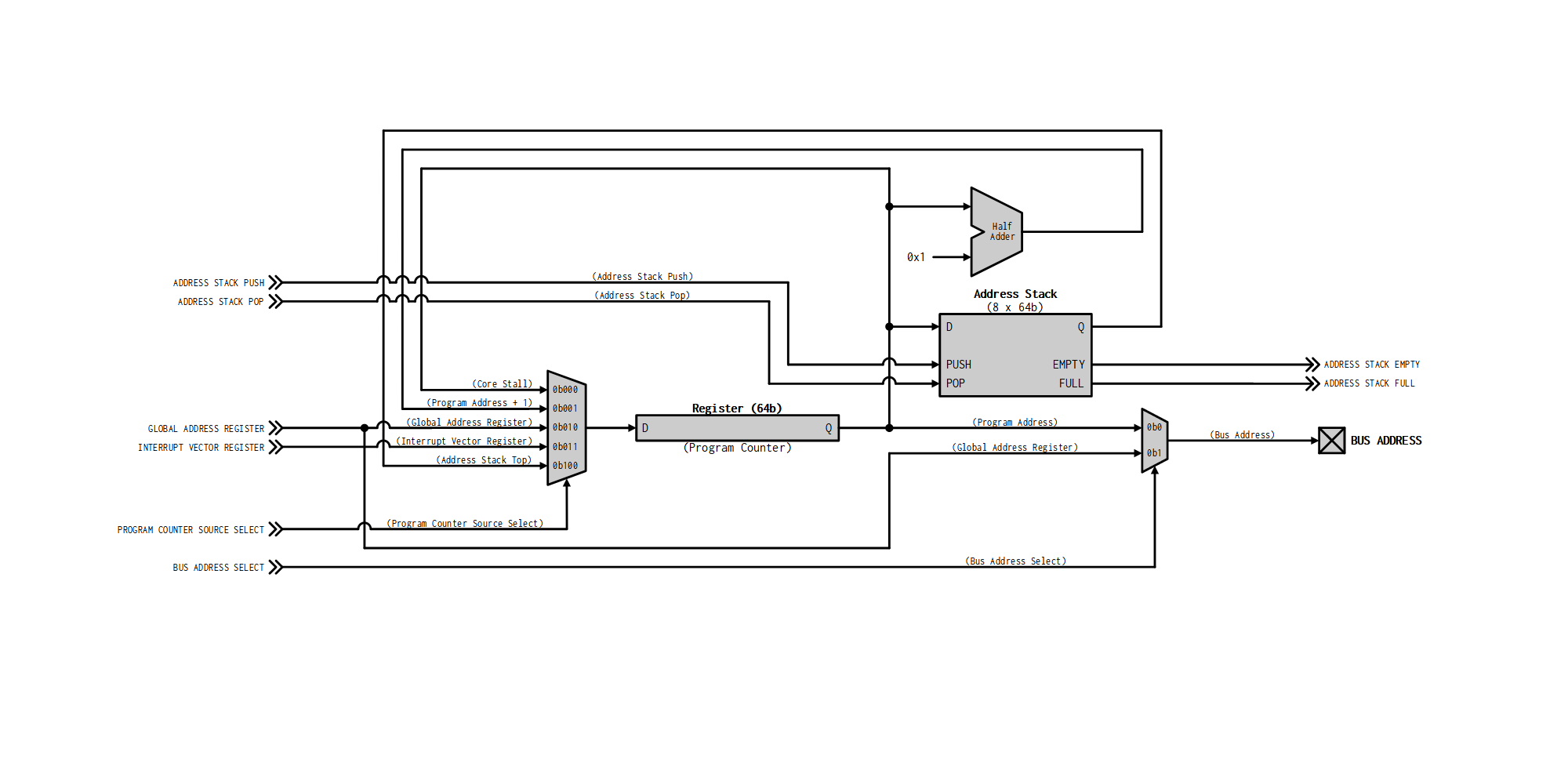
Core Address Control
Yeah this one will never have a Finished tag in the same way that the X86 architecture doesn’t have a Finished tag, but I’m going to keep chronicling the whole thing for next December when I should hopefully be ready to build a compiler for the thing.
And in somewhat related news, the HDL is being re-targeted to an older FPGA from the mid 90s (Xilinx XC3000A series) which I have several dozen of. Not a major overhaul but some things will need split up. I’ll probably just tear all the functional units out of the core and slap them on a 16(writeback)+16(instruction)-bit bus.
Reason being, due to component shortages I’m completely unable to source any more of the configuration devices for the Altera Cyclone III.
Yep, just the little SOIC-8 flash memory, that they vendor-locked to Intel branded EPCSxx chips. It’ll take a few of them to fit the entire design but I’m actually surprised how easy these are to work with.
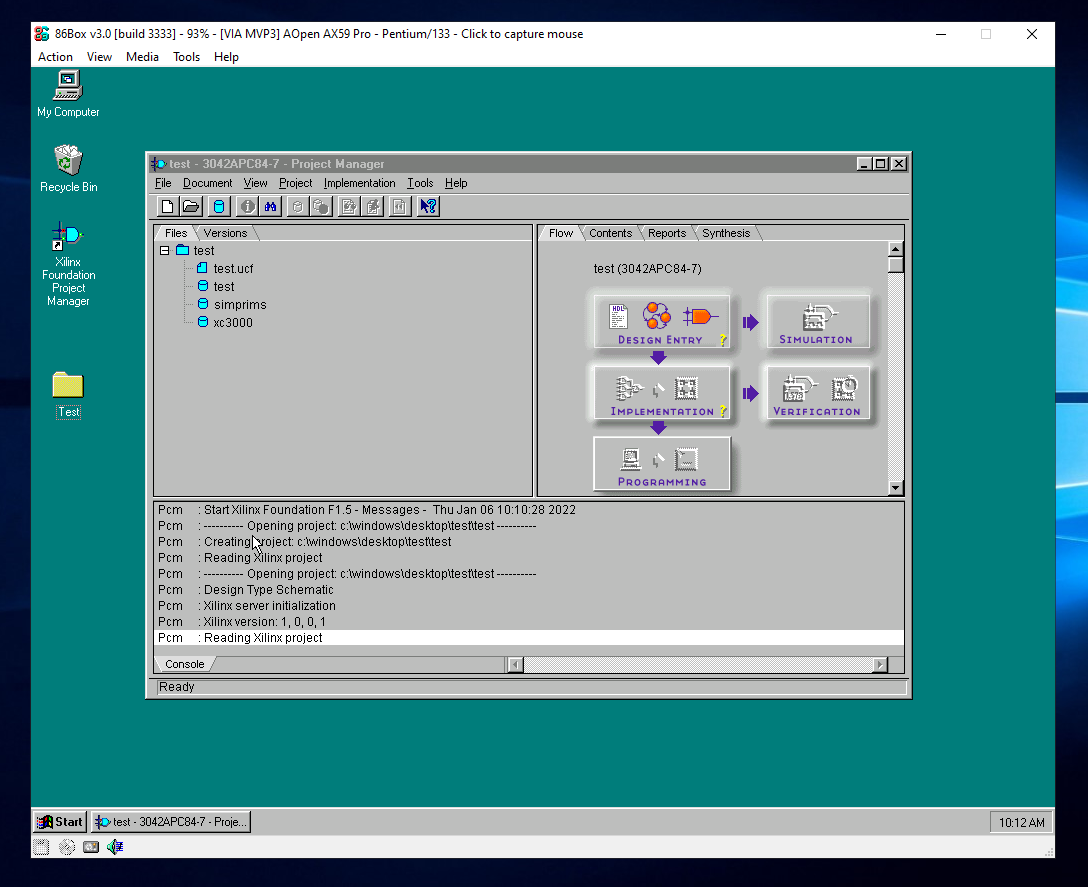
Welcome back, Windows 95. The last supported OS for Xilinx Foundation 1.5i (the last IDE for the XC3000 series), and the only one I’ve been able to get it running on.
Currently emulated on an 86Box Pentium II system, but it’s miserable and so I’ve got a good old Intel 486 Overdrive that’s about to become the new HDL development platform.
TL;DR: New FPGAs are expensive and currently nonexistent, so I’m going back to 1995.
2 Likes
This is very cool! Looking forward to seeing where this goes.