Ok final edit, think I have a pretty good max performance bar

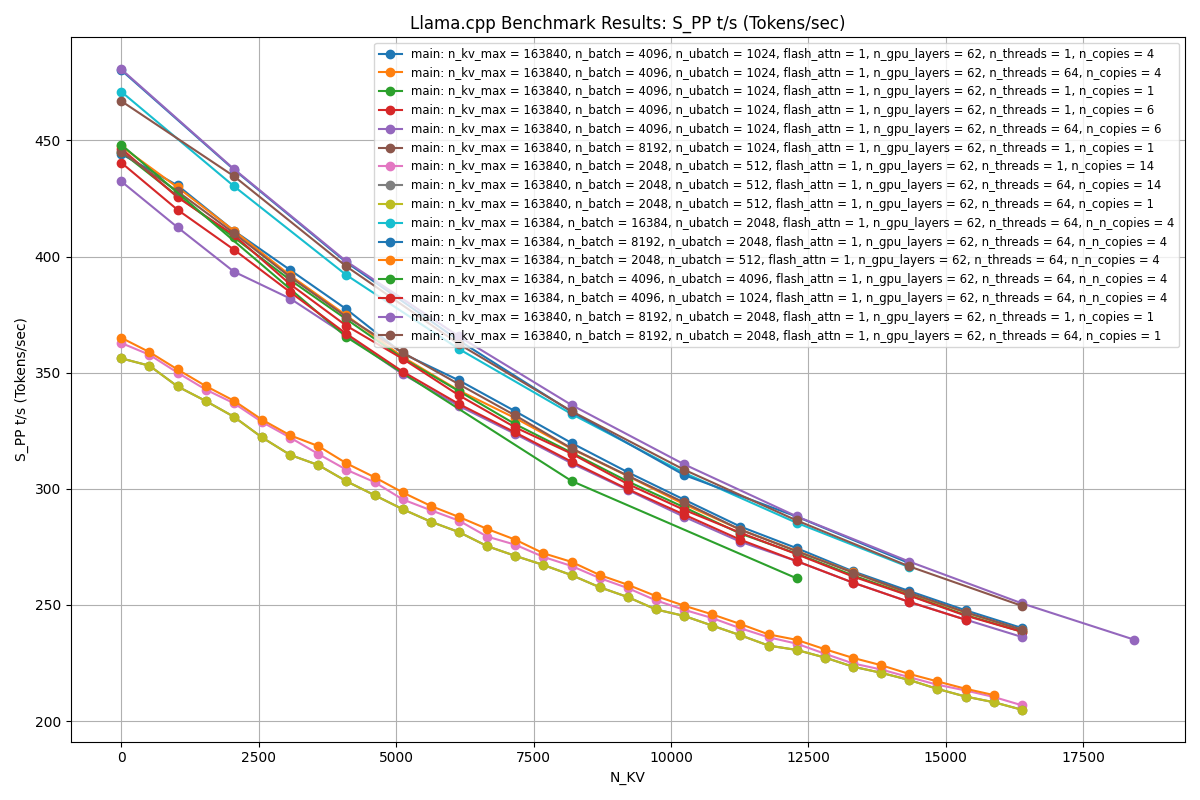
For max token/s for prompt processing: parallelism = 1, batch = 8192, u_batch = 2048, threads = 1
For max token/s for model processing: parallelism = 4, batch = 2048, u_batch = 512, threads = 64
Unexpected result for me, the top model processing settings result in the worst prompt processing. Something to think about I guess.