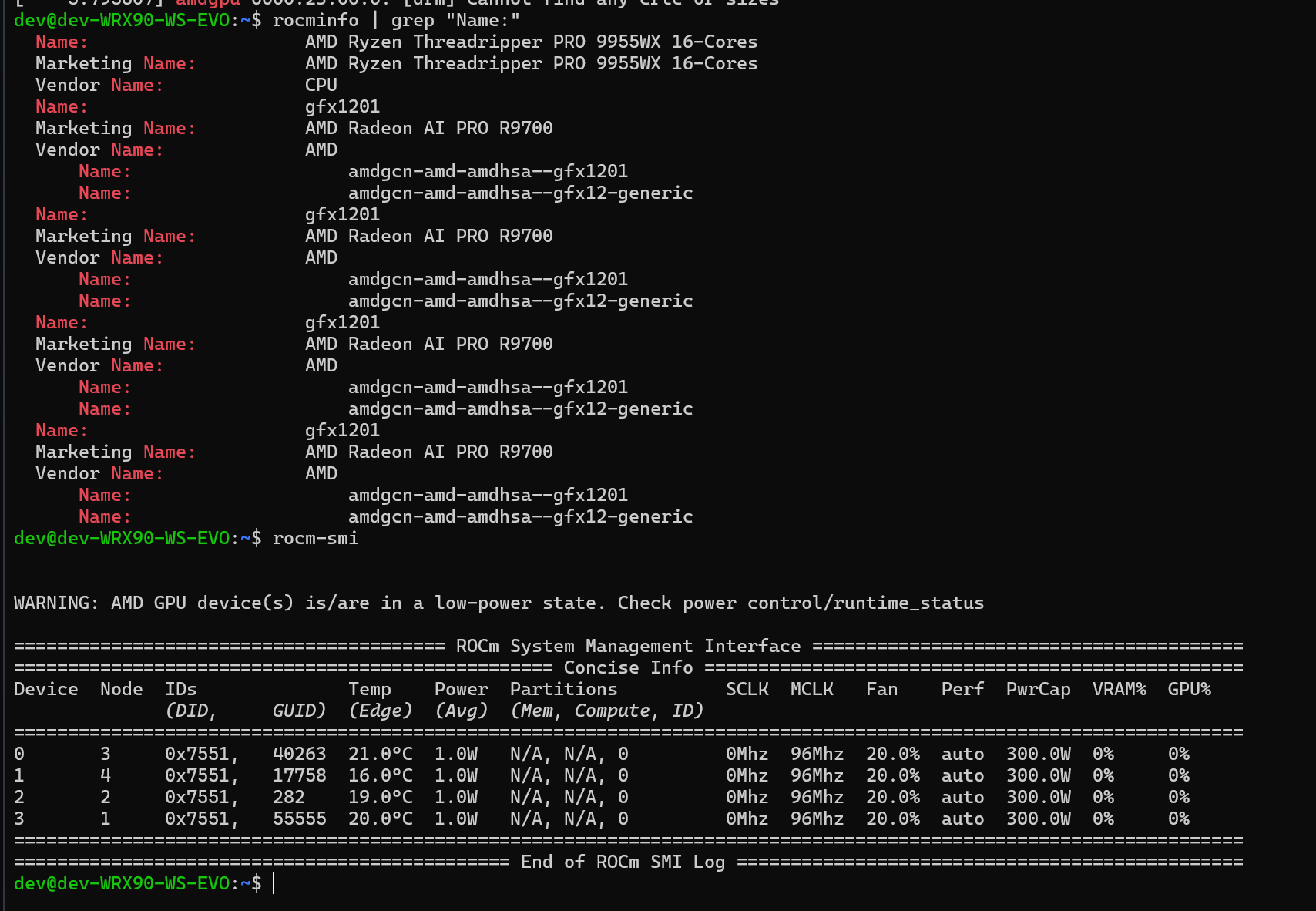
I will stop spamming your thread now. Last one.
Oh, and here is how I started the container:
(rocm_env) dev@dev-WRX90-WS-EVO:~$ docker run -it --rm -p 8000:8000 --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ipc=host -v ~/.cache/huggingface:/root/.cache/huggingface rocm/vllm-dev:rocm7.1.1_navi_ubuntu24.04_py3.12_pytorch_2.8_vllm_0.10.2rc1
Single requests are much slower. I think it’s because my prompts are fairly small and it’s split up between 4 GPUs so there is some comm traffic that slows it down. Just a guess based on what Gemini said, but it makes sense.
root@10506e8af016:/app# vllm serve mistralai/Mistral-Small-24B-Instruct-2501 --tensor-parallel-size 4 --max-model-len 8192 --host 0.0.0.0 --port 8000
INFO 12-25 21:40:04 [init.py:241] Automatically detected platform rocm.
(APIServer pid=734) INFO 12-25 21:40:06 [api_server.py:1882] vLLM API server version 0.10.2rc2.dev3+gdff7f6f03
(APIServer pid=734) INFO 12-25 21:40:06 [utils.py:328] non-default args: {‘model_tag’: ‘mistralai/Mistral-Small-24B-Instruct-2501’, ‘host’: ‘0.0.0.0’, ‘model’: ‘mistralai/Mistral-Small-24B-Instruct-2501’, ‘max_model_len’: 8192, ‘tensor_parallel_size’: 4}
(APIServer pid=734) INFO 12-25 21:40:10 [init.py:744] Resolved architecture: MistralForCausalLM
(APIServer pid=734) torch_dtype is deprecated! Use dtype instead!
(APIServer pid=734) INFO 12-25 21:40:10 [init.py:1773] Using max model len 8192
(APIServer pid=734) INFO 12-25 21:40:10 [scheduler.py:222] Chunked prefill is enabled with max_num_batched_tokens=2048.
(APIServer pid=734) /opt/venv/lib/python3.12/site-packages/vllm/transformers_utils/tokenizer_group.py:27: FutureWarning: It is strongly recommended to run mistral models with --tokenizer-mode "mistral" to ensure correct encoding and decoding.
(APIServer pid=734) self.tokenizer = get_tokenizer(self.tokenizer_id, **tokenizer_config)
(APIServer pid=734) The tokenizer you are loading from ‘mistralai/Mistral-Small-24B-Instruct-2501’ with an incorrect regex pattern: mistralai/Mistral-Small-3.1-24B-Instruct-2503 · regex pattern. This will lead to incorrect tokenization. You should set the fix_mistral_regex=True flag when loading this tokenizer to fix this issue.
INFO 12-25 21:40:13 [init.py:241] Automatically detected platform rocm.
(EngineCore_0 pid=876) INFO 12-25 21:40:14 [core.py:648] Waiting for init message from front-end.
(EngineCore_0 pid=876) INFO 12-25 21:40:14 [core.py:75] Initializing a V1 LLM engine (v0.10.2rc2.dev3+gdff7f6f03) with config: model=‘mistralai/Mistral-Small-24B-Instruct-2501’, speculative_config=None, tokenizer=‘mistralai/Mistral-Small-24B-Instruct-2501’, skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config={}, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=8192, download_dir=None, load_format=auto, tensor_parallel_size=4, pipeline_parallel_size=1, disable_custom_all_reduce=True, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(backend=‘auto’, disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend=‘’), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=0, served_model_name=mistralai/Mistral-Small-24B-Instruct-2501, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, pooler_config=None, compilation_config={“level”:3,“debug_dump_path”:“”,“cache_dir”:“”,“backend”:“”,“custom_ops”:,“splitting_ops”:[“vllm.unified_attention”,“vllm.unified_attention_with_output”,“vllm.mamba_mixer2”,“vllm.mamba_mixer”,“vllm.short_conv”,“vllm.linear_attention”],“use_inductor”:true,“compile_sizes”:,“inductor_compile_config”:{“enable_auto_functionalized_v2”:false},“inductor_passes”:{},“cudagraph_mode”:1,“use_cudagraph”:true,“cudagraph_num_of_warmups”:1,“cudagraph_capture_sizes”:[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],“cudagraph_copy_inputs”:false,“full_cuda_graph”:false,“pass_config”:{},“max_capture_size”:512,“local_cache_dir”:null}
(EngineCore_0 pid=876) WARNING 12-25 21:40:14 [multiproc_worker_utils.py:273] Reducing Torch parallelism from 16 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed.
(EngineCore_0 pid=876) INFO 12-25 21:40:14 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0, 1, 2, 3], buffer_handle=(4, 16777216, 10, ‘psm_9d939a9f’), local_subscribe_addr=‘ipc:///tmp/42c5b777-729d-4bc4-893e-cdef5539d298’, remote_subscribe_addr=None, remote_addr_ipv6=False)
INFO 12-25 21:40:17 [init.py:241] Automatically detected platform rocm.
INFO 12-25 21:40:17 [init.py:241] Automatically detected platform rocm.
INFO 12-25 21:40:17 [init.py:241] Automatically detected platform rocm.
INFO 12-25 21:40:17 [init.py:241] Automatically detected platform rocm.
(VllmWorker TP1 pid=949) INFO 12-25 21:40:19 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, ‘psm_022650eb’), local_subscribe_addr=‘ipc:///tmp/89e7fcbe-2bbd-4c64-86b7-4d53f023bcd4’, remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker TP2 pid=950) INFO 12-25 21:40:19 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, ‘psm_e95f6a81’), local_subscribe_addr=‘ipc:///tmp/ccc715e1-7117-4ce6-adb4-373048ddf6a5’, remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker TP0 pid=948) INFO 12-25 21:40:19 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, ‘psm_0a2f3e78’), local_subscribe_addr=‘ipc:///tmp/3a7f499a-83ef-4aba-9c9f-003f8e0975ae’, remote_subscribe_addr=None, remote_addr_ipv6=False)
(VllmWorker TP3 pid=951) INFO 12-25 21:40:19 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[0], buffer_handle=(1, 10485760, 10, ‘psm_e7af2da4’), local_subscribe_addr=‘ipc:///tmp/8ca7025c-1abb-4182-93de-a262e079d811’, remote_subscribe_addr=None, remote_addr_ipv6=False)
[W1225 21:40:19.351781877 ProcessGroupNCCL.cpp:981] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS is the default now, this environment variable is thus deprecated. (function operator())
[W1225 21:40:19.493788193 ProcessGroupNCCL.cpp:981] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS is the default now, this environment variable is thus deprecated. (function operator())
[W1225 21:40:19.711231544 ProcessGroupNCCL.cpp:981] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS is the default now, this environment variable is thus deprecated. (function operator())
[W1225 21:40:19.720086647 ProcessGroupNCCL.cpp:981] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS is the default now, this environment variable is thus deprecated. (function operator())
[Gloo] Rank 2 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 0 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 1 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 3 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 1 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 0 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 3 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 2 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
(VllmWorker TP1 pid=949) INFO 12-25 21:40:19 [init.py:1432] Found nccl from library librccl.so.1
(VllmWorker TP0 pid=948) INFO 12-25 21:40:19 [init.py:1432] Found nccl from library librccl.so.1
(VllmWorker TP3 pid=951) INFO 12-25 21:40:19 [init.py:1432] Found nccl from library librccl.so.1
(VllmWorker TP1 pid=949) INFO 12-25 21:40:19 [pynccl.py:70] vLLM is using nccl==2.27.7
(VllmWorker TP2 pid=950) INFO 12-25 21:40:19 [init.py:1432] Found nccl from library librccl.so.1
(VllmWorker TP0 pid=948) INFO 12-25 21:40:19 [pynccl.py:70] vLLM is using nccl==2.27.7
(VllmWorker TP3 pid=951) INFO 12-25 21:40:19 [pynccl.py:70] vLLM is using nccl==2.27.7
(VllmWorker TP2 pid=950) INFO 12-25 21:40:19 [pynccl.py:70] vLLM is using nccl==2.27.7
(VllmWorker TP0 pid=948) INFO 12-25 21:40:23 [shm_broadcast.py:289] vLLM message queue communication handle: Handle(local_reader_ranks=[1, 2, 3], buffer_handle=(3, 4194304, 6, ‘psm_fcb6458b’), local_subscribe_addr=‘ipc:///tmp/126e5418-32f4-4119-aab8-c550c5d590f6’, remote_subscribe_addr=None, remote_addr_ipv6=False)
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
[Gloo] Rank 1 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 2 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 0 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
[Gloo] Rank 3 is connected to 3 peer ranks. Expected number of connected peer ranks is : 3
(VllmWorker TP2 pid=950) INFO 12-25 21:40:23 [parallel_state.py:1134] rank 2 in world size 4 is assigned as DP rank 0, PP rank 0, TP rank 2, EP rank 2
(VllmWorker TP1 pid=949) INFO 12-25 21:40:23 [parallel_state.py:1134] rank 1 in world size 4 is assigned as DP rank 0, PP rank 0, TP rank 1, EP rank 1
(VllmWorker TP0 pid=948) INFO 12-25 21:40:23 [parallel_state.py:1134] rank 0 in world size 4 is assigned as DP rank 0, PP rank 0, TP rank 0, EP rank 0
(VllmWorker TP3 pid=951) INFO 12-25 21:40:23 [parallel_state.py:1134] rank 3 in world size 4 is assigned as DP rank 0, PP rank 0, TP rank 3, EP rank 3
(VllmWorker TP3 pid=951) INFO 12-25 21:40:23 [gpu_model_runner.py:1932] Starting to load model mistralai/Mistral-Small-24B-Instruct-2501…
(VllmWorker TP0 pid=948) WARNING 12-25 21:40:23 [rocm.py:354] Model architecture ‘MistralForCausalLM’ is partially supported by ROCm: Sliding window attention (SWA) is not yet supported in Triton flash attention. For half-precision SWA support, please use CK flash attention by setting VLLM_USE_TRITON_FLASH_ATTN=0
(VllmWorker TP2 pid=950) INFO 12-25 21:40:23 [gpu_model_runner.py:1932] Starting to load model mistralai/Mistral-Small-24B-Instruct-2501…
(VllmWorker TP1 pid=949) INFO 12-25 21:40:23 [gpu_model_runner.py:1932] Starting to load model mistralai/Mistral-Small-24B-Instruct-2501…
(VllmWorker TP0 pid=948) INFO 12-25 21:40:23 [gpu_model_runner.py:1932] Starting to load model mistralai/Mistral-Small-24B-Instruct-2501…
(VllmWorker TP1 pid=949) INFO 12-25 21:40:23 [gpu_model_runner.py:1964] Loading model from scratch…
(VllmWorker TP1 pid=949) WARNING 12-25 21:40:23 [rocm.py:354] Model architecture ‘MistralForCausalLM’ is partially supported by ROCm: Sliding window attention (SWA) is not yet supported in Triton flash attention. For half-precision SWA support, please use CK flash attention by setting VLLM_USE_TRITON_FLASH_ATTN=0
(VllmWorker TP2 pid=950) INFO 12-25 21:40:23 [gpu_model_runner.py:1964] Loading model from scratch…
(VllmWorker TP2 pid=950) WARNING 12-25 21:40:23 [rocm.py:354] Model architecture ‘MistralForCausalLM’ is partially supported by ROCm: Sliding window attention (SWA) is not yet supported in Triton flash attention. For half-precision SWA support, please use CK flash attention by setting VLLM_USE_TRITON_FLASH_ATTN=0
(VllmWorker TP3 pid=951) INFO 12-25 21:40:23 [gpu_model_runner.py:1964] Loading model from scratch…
(VllmWorker TP3 pid=951) WARNING 12-25 21:40:23 [rocm.py:354] Model architecture ‘MistralForCausalLM’ is partially supported by ROCm: Sliding window attention (SWA) is not yet supported in Triton flash attention. For half-precision SWA support, please use CK flash attention by setting VLLM_USE_TRITON_FLASH_ATTN=0
(VllmWorker TP0 pid=948) INFO 12-25 21:40:23 [gpu_model_runner.py:1964] Loading model from scratch…
(VllmWorker TP2 pid=950) INFO 12-25 21:40:24 [rocm.py:248] Using Triton Attention backend on V1 engine.
(VllmWorker TP2 pid=950) INFO 12-25 21:40:24 [triton_attn.py:257] Using vllm unified attention for TritonAttentionImpl
(VllmWorker TP3 pid=951) INFO 12-25 21:40:24 [rocm.py:248] Using Triton Attention backend on V1 engine.
(VllmWorker TP3 pid=951) INFO 12-25 21:40:24 [triton_attn.py:257] Using vllm unified attention for TritonAttentionImpl
(VllmWorker TP1 pid=949) INFO 12-25 21:40:24 [rocm.py:248] Using Triton Attention backend on V1 engine.
(VllmWorker TP1 pid=949) INFO 12-25 21:40:24 [triton_attn.py:257] Using vllm unified attention for TritonAttentionImpl
(VllmWorker TP0 pid=948) INFO 12-25 21:40:24 [rocm.py:248] Using Triton Attention backend on V1 engine.
(VllmWorker TP0 pid=948) INFO 12-25 21:40:24 [triton_attn.py:257] Using vllm unified attention for TritonAttentionImpl
(VllmWorker TP2 pid=950) INFO 12-25 21:40:24 [weight_utils.py:304] Using model weights format [‘.safetensors’]
(VllmWorker TP1 pid=949) INFO 12-25 21:40:24 [weight_utils.py:304] Using model weights format ['.safetensors’]
(VllmWorker TP0 pid=948) INFO 12-25 21:40:24 [weight_utils.py:304] Using model weights format [‘.safetensors’]
(VllmWorker TP3 pid=951) INFO 12-25 21:40:24 [weight_utils.py:304] Using model weights format ['.safetensors’]
model-00004-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.89G/4.89G [04:09<00:00, 19.6MB/s]
model-00001-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [04:44<00:00, 16.8MB/s]
model-00003-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [04:53<00:00, 16.3MB/s]
model-00002-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [04:58<00:00, 16.0MB/s]
model-00007-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.89G/4.89G [05:00<00:00, 16.3MB/s]
model-00005-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [05:24<00:00, 14.7MB/s]
model-00006-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [05:28<00:00, 14.5MB/s]
model-00010-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.90G/3.90G [02:12<00:00, 29.4MB/s]
model-00008-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [03:20<00:00, 23.9MB/s]
model-00009-of-00010.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [02:47<00:00, 28.5MB/s]
consolidated.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 47.1G/47.1G [12:40<00:00, 62.0MB/s]
(VllmWorker TP2 pid=950) INFO 12-25 21:53:04 [weight_utils.py:325] Time spent downloading weights for mistralai/Mistral-Small-24B-Instruct-2501: 760.692362 seconds | 5.38G/47.1G [07:06<13:52, 50.2MB/s]
model.safetensors.index.json: 29.9kB [00:00, 242MB/s]████▌ | 7.54G/47.1G [07:31<03:33, 185MB/s]
Loading safetensors checkpoint shards: 0% Completed | 0/10 [00:00<?, ?it/s] | 7.97G/47.1G [07:34<04:17, 152MB/s]
Loading safetensors checkpoint shards: 10% Completed | 1/10 [00:00<00:02, 4.41it/s]████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 47.1G/47.1G [12:40<00:00, 514MB/s]
Loading safetensors checkpoint shards: 20% Completed | 2/10 [00:00<00:01, 4.10it/s]████████████████████████████████████████████████████████████████████████████████████████████████████████████▊ | 4.71G/4.78G [02:40<00:03, 21.2MB/s]
Loading safetensors checkpoint shards: 30% Completed | 3/10 [00:00<00:01, 3.81it/s]███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.78G/4.78G [02:47<00:00, 15.4MB/s]
Loading safetensors checkpoint shards: 40% Completed | 4/10 [00:01<00:01, 3.81it/s]
Loading safetensors checkpoint shards: 50% Completed | 5/10 [00:01<00:01, 3.79it/s]
Loading safetensors checkpoint shards: 60% Completed | 6/10 [00:01<00:01, 3.73it/s]
Loading safetensors checkpoint shards: 70% Completed | 7/10 [00:01<00:00, 3.69it/s]
Loading safetensors checkpoint shards: 80% Completed | 8/10 [00:02<00:00, 3.69it/s]
(VllmWorker TP2 pid=950) INFO 12-25 21:53:07 [default_loader.py:267] Loading weights took 2.61 seconds
Loading safetensors checkpoint shards: 90% Completed | 9/10 [00:02<00:00, 3.93it/s]
(VllmWorker TP1 pid=949) INFO 12-25 21:53:07 [default_loader.py:267] Loading weights took 2.64 seconds
Loading safetensors checkpoint shards: 100% Completed | 10/10 [00:02<00:00, 4.00it/s]
Loading safetensors checkpoint shards: 100% Completed | 10/10 [00:02<00:00, 3.88it/s]
(VllmWorker TP0 pid=948)
(VllmWorker TP0 pid=948) INFO 12-25 21:53:08 [default_loader.py:267] Loading weights took 2.60 seconds
(VllmWorker TP3 pid=951) INFO 12-25 21:53:08 [default_loader.py:267] Loading weights took 2.56 seconds
(VllmWorker TP2 pid=950) INFO 12-25 21:53:08 [gpu_model_runner.py:1986] Model loading took 11.0645 GiB and 763.990910 seconds
(VllmWorker TP1 pid=949) INFO 12-25 21:53:08 [gpu_model_runner.py:1986] Model loading took 11.0645 GiB and 764.199423 seconds
(VllmWorker TP0 pid=948) INFO 12-25 21:53:08 [gpu_model_runner.py:1986] Model loading took 11.0645 GiB and 764.318582 seconds
(VllmWorker TP3 pid=951) INFO 12-25 21:53:08 [gpu_model_runner.py:1986] Model loading took 11.0645 GiB and 764.454001 seconds
(VllmWorker TP3 pid=951) INFO 12-25 21:53:11 [backends.py:538] Using cache directory: /root/.cache/vllm/torch_compile_cache/1d1592f64b/rank_3_0/backbone for vLLM’s torch.compile
(VllmWorker TP1 pid=949) INFO 12-25 21:53:11 [backends.py:538] Using cache directory: /root/.cache/vllm/torch_compile_cache/1d1592f64b/rank_1_0/backbone for vLLM’s torch.compile
(VllmWorker TP0 pid=948) INFO 12-25 21:53:11 [backends.py:538] Using cache directory: /root/.cache/vllm/torch_compile_cache/1d1592f64b/rank_0_0/backbone for vLLM’s torch.compile
(VllmWorker TP3 pid=951) INFO 12-25 21:53:11 [backends.py:549] Dynamo bytecode transform time: 2.58 s
(VllmWorker TP1 pid=949) INFO 12-25 21:53:11 [backends.py:549] Dynamo bytecode transform time: 2.58 s
(VllmWorker TP2 pid=950) INFO 12-25 21:53:11 [backends.py:538] Using cache directory: /root/.cache/vllm/torch_compile_cache/1d1592f64b/rank_2_0/backbone for vLLM’s torch.compile
(VllmWorker TP0 pid=948) INFO 12-25 21:53:11 [backends.py:549] Dynamo bytecode transform time: 2.58 s
(VllmWorker TP2 pid=950) INFO 12-25 21:53:11 [backends.py:549] Dynamo bytecode transform time: 2.58 s
(VllmWorker TP0 pid=948) INFO 12-25 21:53:13 [backends.py:194] Cache the graph for dynamic shape for later use
(VllmWorker TP3 pid=951) INFO 12-25 21:53:13 [backends.py:194] Cache the graph for dynamic shape for later use
(VllmWorker TP2 pid=950) INFO 12-25 21:53:13 [backends.py:194] Cache the graph for dynamic shape for later use
(VllmWorker TP1 pid=949) INFO 12-25 21:53:13 [backends.py:194] Cache the graph for dynamic shape for later use
(VllmWorker TP3 pid=951) INFO 12-25 21:53:24 [backends.py:215] Compiling a graph for dynamic shape takes 11.97 s
(VllmWorker TP1 pid=949) INFO 12-25 21:53:24 [backends.py:215] Compiling a graph for dynamic shape takes 11.97 s
(VllmWorker TP0 pid=948) INFO 12-25 21:53:24 [backends.py:215] Compiling a graph for dynamic shape takes 12.04 s
(VllmWorker TP2 pid=950) INFO 12-25 21:53:24 [backends.py:215] Compiling a graph for dynamic shape takes 12.04 s
(VllmWorker TP0 pid=948) INFO 12-25 21:53:25 [monitor.py:34] torch.compile takes 14.62 s in total
(VllmWorker TP2 pid=950) INFO 12-25 21:53:25 [monitor.py:34] torch.compile takes 14.62 s in total
(VllmWorker TP3 pid=951) INFO 12-25 21:53:25 [monitor.py:34] torch.compile takes 14.54 s in total
(VllmWorker TP1 pid=949) INFO 12-25 21:53:25 [monitor.py:34] torch.compile takes 14.56 s in total
(VllmWorker TP2 pid=950) INFO 12-25 21:53:27 [gpu_worker.py:276] Available KV cache memory: 13.46 GiB
(VllmWorker TP1 pid=949) INFO 12-25 21:53:27 [gpu_worker.py:276] Available KV cache memory: 13.46 GiB
(VllmWorker TP3 pid=951) INFO 12-25 21:53:27 [gpu_worker.py:276] Available KV cache memory: 13.46 GiB
(VllmWorker TP0 pid=948) INFO 12-25 21:53:27 [gpu_worker.py:276] Available KV cache memory: 13.46 GiB
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:850] GPU KV cache size: 352,752 tokens
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:854] Maximum concurrency for 8,192 tokens per request: 43.06x
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:850] GPU KV cache size: 352,752 tokens
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:854] Maximum concurrency for 8,192 tokens per request: 43.06x
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:850] GPU KV cache size: 352,752 tokens
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:854] Maximum concurrency for 8,192 tokens per request: 43.06x
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:850] GPU KV cache size: 352,752 tokens
(EngineCore_0 pid=876) INFO 12-25 21:53:27 [kv_cache_utils.py:854] Maximum concurrency for 8,192 tokens per request: 43.06x
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 67/67 [00:13<00:00, 5.04it/s]
(VllmWorker TP0 pid=948) INFO 12-25 21:53:41 [gpu_model_runner.py:2687] Graph capturing finished in 14 secs, took 3.81 GiB
(VllmWorker TP1 pid=949) INFO 12-25 21:53:41 [gpu_model_runner.py:2687] Graph capturing finished in 14 secs, took 3.81 GiB
(VllmWorker TP2 pid=950) INFO 12-25 21:53:41 [gpu_model_runner.py:2687] Graph capturing finished in 14 secs, took 3.81 GiB
(VllmWorker TP3 pid=951) INFO 12-25 21:53:41 [gpu_model_runner.py:2687] Graph capturing finished in 14 secs, took 3.81 GiB
(EngineCore_0 pid=876) INFO 12-25 21:53:41 [core.py:217] init engine (profile, create kv cache, warmup model) took 32.93 seconds
(EngineCore_0 pid=876) /opt/venv/lib/python3.12/site-packages/vllm/transformers_utils/tokenizer_group.py:27: FutureWarning: It is strongly recommended to run mistral models with --tokenizer-mode "mistral" to ensure correct encoding and decoding.
(EngineCore_0 pid=876) self.tokenizer = get_tokenizer(self.tokenizer_id, **tokenizer_config)
(EngineCore_0 pid=876) The tokenizer you are loading from ‘mistralai/Mistral-Small-24B-Instruct-2501’ with an incorrect regex pattern: mistralai/Mistral-Small-3.1-24B-Instruct-2503 · regex pattern. This will lead to incorrect tokenization. You should set the fix_mistral_regex=True flag when loading this tokenizer to fix this issue.
(APIServer pid=734) INFO 12-25 21:53:42 [loggers.py:142] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 22047
(APIServer pid=734) INFO 12-25 21:53:42 [async_llm.py:166] Torch profiler disabled. AsyncLLM CPU traces will not be collected.
(APIServer pid=734) INFO 12-25 21:53:42 [api_server.py:1680] Supported_tasks: [‘generate’]
(APIServer pid=734) WARNING 12-25 21:53:42 [init.py:1673] Default sampling parameters have been overridden by the model’s Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with --generation-config vllm.
(APIServer pid=734) INFO 12-25 21:53:42 [serving_responses.py:126] Using default chat sampling params from model: {‘temperature’: 0.15}
(APIServer pid=734) INFO 12-25 21:53:42 [serving_chat.py:137] Using default chat sampling params from model: {‘temperature’: 0.15}
(APIServer pid=734) INFO 12-25 21:53:42 [serving_completion.py:79] Using default completion sampling params from model: {‘temperature’: 0.15}
(APIServer pid=734) INFO 12-25 21:53:42 [api_server.py:1957] Starting vLLM API server 0 on http://0.0.0.0:8000
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:36] Available routes are:
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /openapi.json, Methods: GET, HEAD
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /docs, Methods: GET, HEAD
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /docs/oauth2-redirect, Methods: GET, HEAD
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /redoc, Methods: GET, HEAD
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /health, Methods: GET
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /load, Methods: GET
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /ping, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /ping, Methods: GET
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /tokenize, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /detokenize, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/models, Methods: GET
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /version, Methods: GET
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/responses, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/responses/{response_id}, Methods: GET
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/responses/{response_id}/cancel, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/chat/completions, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/completions, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/embeddings, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /pooling, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /classify, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /score, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/score, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/audio/transcriptions, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/audio/translations, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /rerank, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v1/rerank, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /v2/rerank, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /scale_elastic_ep, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /is_scaling_elastic_ep, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /invocations, Methods: POST
(APIServer pid=734) INFO 12-25 21:53:42 [launcher.py:44] Route: /metrics, Methods: GET
(APIServer pid=734) INFO: Started server process [734]
(APIServer pid=734) INFO: Waiting for application startup.
(APIServer pid=734) INFO: Application startup complete.
(APIServer pid=734) The tokenizer you are loading from ‘mistralai/Mistral-Small-24B-Instruct-2501’ with an incorrect regex pattern: mistralai/Mistral-Small-3.1-24B-Instruct-2503 · regex pattern. This will lead to incorrect tokenization. You should set the fix_mistral_regex=True flag when loading this tokenizer to fix this issue.
(APIServer pid=734) INFO 12-25 21:56:21 [chat_utils.py:470] Detected the chat template content format to be ‘string’. You can set --chat-template-content-format to override this.
(APIServer pid=734) INFO 12-25 21:56:22 [loggers.py:123] Engine 000: Avg prompt throughput: 19.3 tokens/s, Avg generation throughput: 2.0 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.1%, Prefix cache hit rate: 0.0%
(APIServer pid=734) INFO 12-25 21:56:32 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 26.9 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.1%, Prefix cache hit rate: 0.0%
(APIServer pid=734) INFO: 172.17.0.1:49464 - “POST /v1/chat/completions HTTP/1.1” 200 OK
(APIServer pid=734) INFO 12-25 21:56:42 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 21.1 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
(APIServer pid=734) INFO 12-25 21:56:52 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%