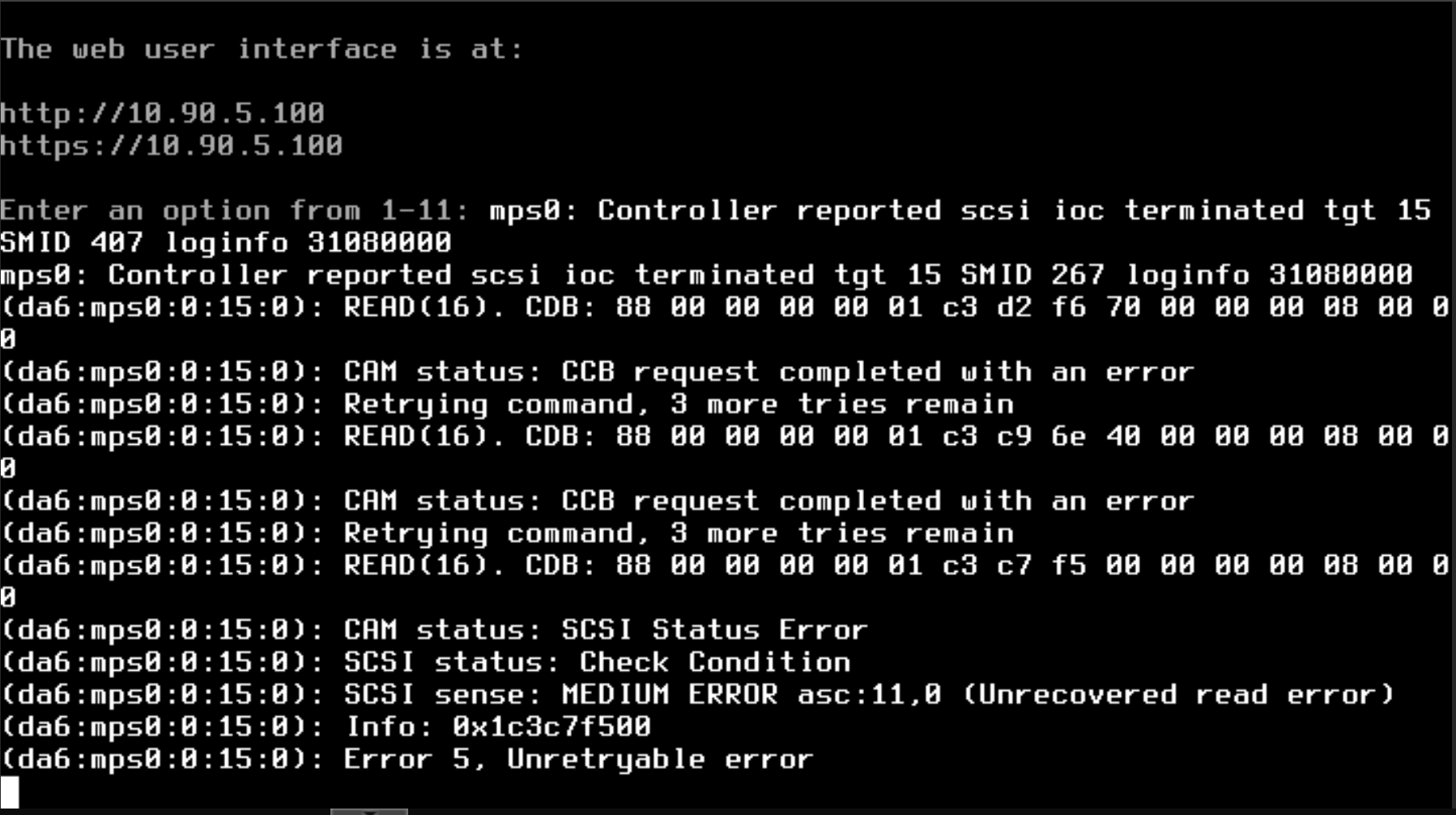
Hi everyone,
Not my first time I have had drives go bad… but it is the first time I have had 2 fault at the same time. Thankfully its a Z2 array, and I have a cold spare waiting to go in. But with 2 drives down, I am a little weary of how to approach this.
Would it make sense to do a zpool clear to force it to think everything is ok, and then replace one of the drives with my cold spare? See how the resilver goes, do a scrub, and monitor the situation? I don’t want to get myself into a worse situation by jumping to any conclusions prematurly.
I have had a few SMART errors pop up over the past few SMART tests, I guess I didn’t dig deep enough into them because I had thought the drives were still working fine (I have had eronious errors in the past that didn’t actually result in bad drives or any corruption). Looking at the SMART status of da5 (Drive with 62 faults according to zpool status), I am seeing:
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 199 199 051 Pre-fail Always - 43
3 Spin_Up_Time 0x0027 186 161 021 Pre-fail Always - 5700
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 234
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 028 028 000 Old_age Always - 52765
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 228
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 224
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 131
194 Temperature_Celsius 0x0022 121 105 000 Old_age Always - 29
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 055 000 Old_age Always - 608
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 1
SMART Error Log Version: 1
No Errors Logged
da7 (Drive with 61 faults):
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 1
3 Spin_Up_Time 0x0027 184 159 021 Pre-fail Always - 5766
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 235
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 028 028 000 Old_age Always - 52758
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 228
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 224
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 107
194 Temperature_Celsius 0x0022 120 105 000 Old_age Always - 30
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
Zpool status:
pool: pergamum
state: DEGRADED
status: One or more devices are faulted in response to persistent errors.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Replace the faulted device, or use 'zpool clear' to mark the device
repaired.
scan: scrub repaired 1.89M in 06:25:16 with 0 errors on Thu Dec 21 06:25:36 2023
config:
NAME STATE READ WRITE CKSUM
pergamum DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gptid/ab0351e8-44ea-11e8-8cad-e0071bffdaee ONLINE 0 0 0
gptid/abbfceac-44ea-11e8-8cad-e0071bffdaee ONLINE 0 0 0
gptid/e3c7752a-1fc4-11ea-8e70-000c29cab7ac ONLINE 0 0 0
gptid/6ebdcf54-ac93-11ec-b2a3-279dd0c48793 ONLINE 0 0 0
gptid/ae0d7e64-44ea-11e8-8cad-e0071bffdaee ONLINE 0 0 0
gptid/aeca106f-44ea-11e8-8cad-e0071bffdaee ONLINE 0 0 0
gptid/af89686d-44ea-11e8-8cad-e0071bffdaee FAULTED 61 0 0 too many errors
gptid/b04ad4fc-44ea-11e8-8cad-e0071bffdaee ONLINE 0 0 0
gptid/b10b6452-44ea-11e8-8cad-e0071bffdaee FAULTED 62 0 0 too many errors
gptid/b1d949c1-44ea-11e8-8cad-e0071bffdaee ONLINE 0 0 0
errors: No known data errors
What should my next steps here be?
To stave off any questison about hardware, it can all be found in my signature, but the controller is a H310 to a SAS expander, and has been in good working order for 7+ years (minus a few drive failures over the years). Its possible a SAS → SATA cable (or two) is going bad, its happened to me before. But I am thinking this is not that sort of situation.