I have a NAS, which runs linux. I have ZFS installed
I’ve set it up with /etc/modprobe.d/zfs.conf to use 18GB of ram minimum, but 32GB maximum.
Everytime I look at it though, it appears to only use the minimum, regardless of the system having basically another 32GB free. Does anyone know why this would be?
I thought ZFS would automatically utilise that space if available? Am I missing something?
Obviously I want that RAM to be utilised…And I’m sure if I go in and change the minimum, then more WOULD be used
ARC only caches things that have previously been used. So after a reboot the ARC is basically empty. If you access data, it gets copied into ARC and is cached in later reads. MRU/MFU algorithms ensure that the most important data is kept in the ARC, while less often/recently used stuff gets evicted. But as long as the ARC didn’t reach the Maximum size yet, everything will enter ARC.
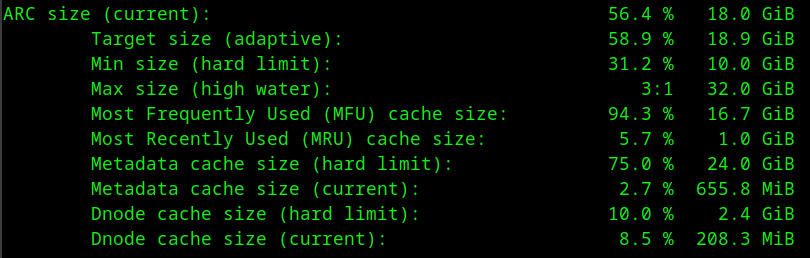
Yeah. 19GB used out of 32GB.
I never set a minimum because ARC never cedes those 10GB to the OS and other applications, potentially causing problems.
No. Minimum only defines the amount of space that can be given back to the OS if applications demand memory. ARC will shrink adaptively depending on what other applications need and will refuse to do so after it reached its minimum.
ARC is memory and memory is wiped on reboot. There is no record kept on HDDs or where ever. You can warm up the ARC with some scripts on boot with pre-defined files/directories if this helps.
No it doesn’t do that and I am not sure if I really want the extra bookkeeping, especially since zfs can be nice on desktop systems also but for that I want a more dynamic ARC. I would go the warm-up way that @Exard3k mentioned or just leave it until your reboot intervals go down.
The problem is…what data should be proactively put into the ARC? You certainly can’t move the entire pool into memory. And even if you keep track of blocks that have been accessed a month ago, which is extra metadata for bookkeeping, your habits may have changed and you always have that 20GB of e.g. Elden Ring game files preloaded into ARC although you don’t play it anymore.
ARC is designed for servers that run 24/7 to improve cache hits over time and adapt dynamically to your workload without too much overhead.
If you’re feeling that persistence and cached reads are important while having regular reboots, consider using an SSD as L2ARC and enable persistent L2ARC. I have a rather big L2ARC and I see good performance after reboot, not memory speeds, but certainly not slow HDD performance.
ARC is great, but needs time to fill and figure out what’s important data.
Correct. Once ARC is at maximum, it has to decide what data to keep and what to delete/evict. Everything that gets evicted from of the ARC, gets moved to the L2ARC and some bookkeeping is left inside the ARC so it knows “hey I don’t have that data, but I put it into L2ARC. No need to get it from HDD”.
A certain amount of data that is close to eviction also gets stored in the L2ARC, so ARC can delete it if necessary without having the pressure of waiting for the L2ARC to store it. Makes the transition very smooth
Just because it was evicted doesn’t mean it’s not important data. But it’s more data than your memory can handle.
I don’t suppose either of you have any tips for not rebooting? I guess there is ways to do most things without reboot apart from kernel updates (Not updating the kernel often?)
I’m running Proxmox and I reboot like every two weeks to get updates. But if the system is running fine and you don’t have open ports to the internet, there is no need to reboot a NAS or server. Linux and ZFS will do fine running for months if not years.
It sounds like you’re having something similar happen here. The ZFS target size reduces over time, so the ARC never uses the maximum configured size.
Are you acessing the same files over and over again, or are you reading lots of large, different files? The latter doesn’t really need a large ARC, and may be why ZFS is not trying to push the target size back up.
Be aware that trying to pre-warm cache can be counter-productive if you’re
pre-warming the wrong data - either files you think are hot that aren’t - or potentially files that aren’t hot at the time you think they are and potentially evicting other more relevant data already in the cache
pre-warming data that may be relevant but not what end users are actually requesting during the pre-warming (e.g., you are attempting to pre-cache folder A whilst user is actually right then trying to access folder B
ZFS can cache at the block (i.e., parts of files) level as users request said blocks - by copying files you’re pre-caching entire files which may reduce cache effectiveness