Hi,
I had planned to use a RaidZ1 as storage for Seafile (is an alternative to Nextcloud / Owncloud) and maybe 2-3 other VMs with not really high load
The performance for a Z1 raid also seems very bad to me, when testing the individual disks I had about 50% more performance in the same test
But according to this formula, I should have had a factor of 3 higher performance
Streaming write speed: (N - p) * Streaming write speed of single drive
This is my test script:
IODEPTH=16
NUMJOBS=1
BLOCKSIZE=4M
RUNTIME=900
TEST_DIR=/testZFS/fiotest
mkdir -p $TEST_DIR && rm -r $TEST_DIR/*
fio --name=write_throughput --directory=$TEST_DIR --numjobs=$NUMJOBS \
--size=50G --time_based --runtime=$RUNTIME --ramp_time=2s --ioengine=libaio \
--direct=1 --bs=$BLOCKSIZE --iodepth=$IODEPTH --rw=randwrite \
--group_reporting=1 --iodepth_batch_submit=$IODEPTH \
--iodepth_batch_complete_max=$IODEPTH
I created the ZFS pool and the VM with default settings.
once with ashift 9 and once with 12, but that didn’t make much difference
this is are my test devices, which are plugged into an M.2 PCIe4 x4 slot / M.2 Slot on an PCIe4 x16 expansion card (all SSDs are correct detected with PCIe4 x4 lanes each)
2 x Lexar SSD NM790 1TB
2 x KIOXIA-EXCERIA PLUS G3 SSD 1TB
this are the results with ZFSRaidZ1:
WRITE: bw=944MiB/s (990MB/s), 944MiB/s-944MiB/s (990MB/s-990MB/s), io=830GiB (891GB), run=900009-900009msec
Because of the poor performance, I took another step back and took a closer look at the performance of the individual disks
And there I noticed that the performance with ext4 is significantly better than with ZFS
This is the result of the fio benchmark with the same settings as above.
The disks are formatted here with ext4
nvme2 and nvme3 are the two Kioxia and nvme0 and nvme1 are the Lexar
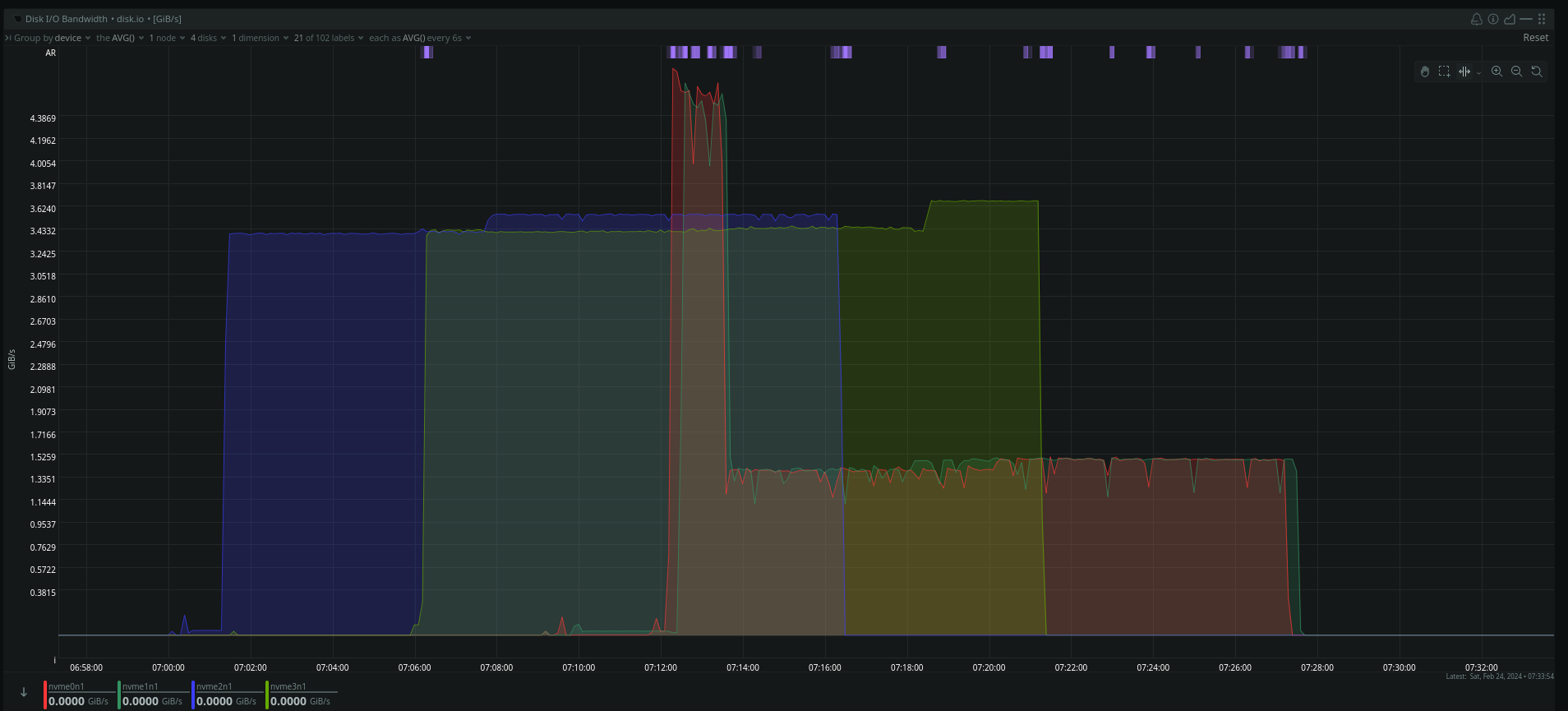
And here is the result with ZFS.
The first block is the Lexar, the second the Kioxia and the third the Kioxia again, but this time with 1MB / 4MB recordsize
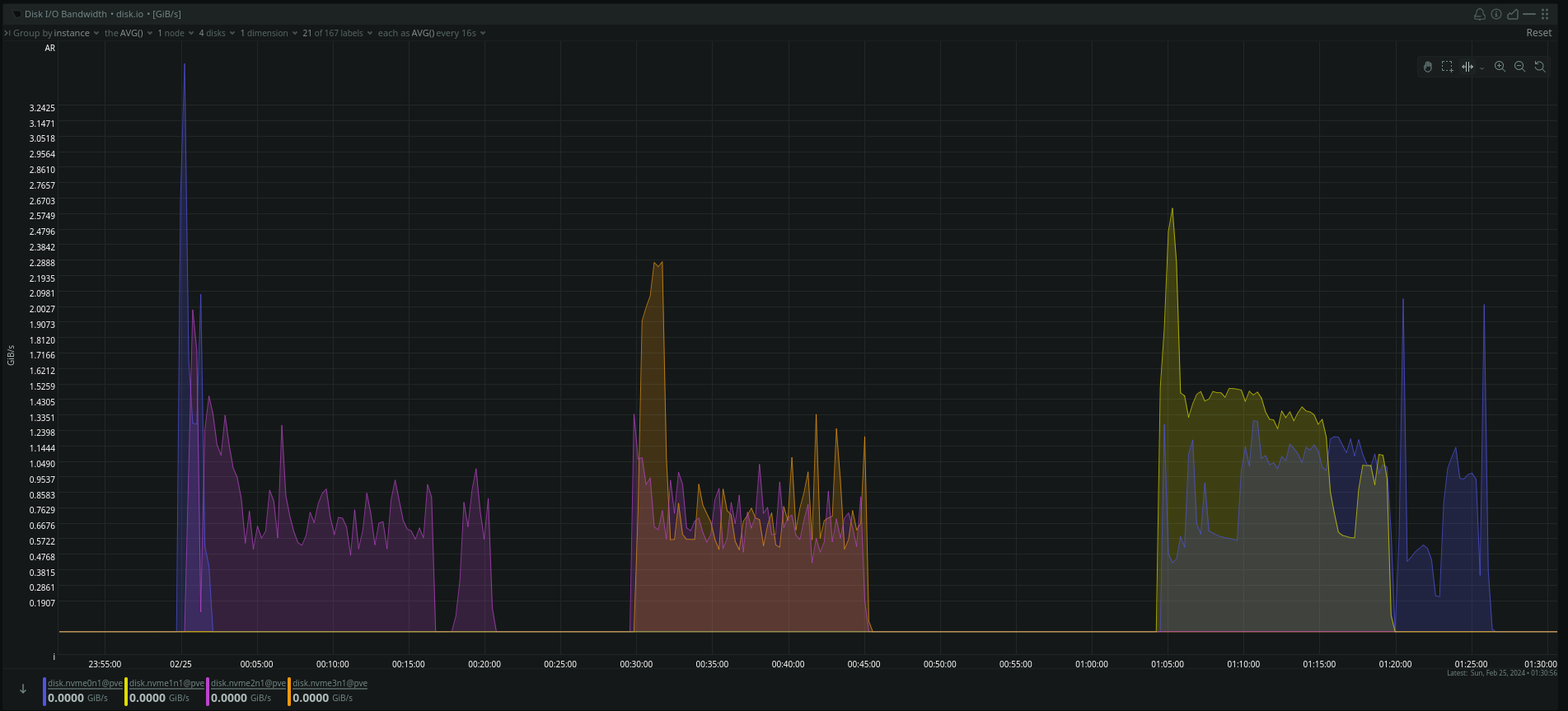
Even when I increased the recordsize from the default 128KB to 1MB or 4MB, I only got about 1200MB/s with the Kioxia SSDs.
Here are the values from the ext4 test
Kioxia: approx. 3400MB/s
Lexar: Short peak at approx. 4500MB/s and then approx. 1400MB/s
Any ideas why the SSDs with ZFS have such significantly lower performance?
Edit:
Screenshots replaced, because I figured out how to display the individual results instead of the sum in netdata
