It will be fine  I would go raidz2 up to maybe 12 disks. Then I would consider raidz3.
I would go raidz2 up to maybe 12 disks. Then I would consider raidz3.
Just use SMART and scrubbing and make it auto-mail you if there’s a problem.
12 disks will have performance degradation ( 128KiB / 10= ~12.8KiB = BAD ). And I don’t want to mess with ZFS cluster size. 10 disks is optimal ( 128 KiB / 8 = 16KiB = good ) and I really can’t fit more HDDs in my case.
https://forum.level1techs.com/t/post-what-new-thing-you-acquired-recently/149881/5738


Yeah, it’s just my arbitrary ballpark numbers.
That’s for the best imo. Because 10 disks on sata is my absolute maximum I would try to run. (Again, just my arbitrary numbers)
Build log update:
- I did a rookie mistake by not checking the specs of the disks:
- ST2000VN000 (x4) have 5900 RPM and 64 MB of cache
- ST2000NC033* (x6) have 7200 RPM and 64 MB of cache
I got some older ST2000NM0033 (09/2013) that have 7200 rpm and 128 MB of Cache. Should I combine these with the NC001s in my array? I think I trust those even less, but idk… better have same RPM disks.
-
One of the VN000s is already reporting SMART errors. I haven’t looked too long at the screen, I just took the SN and device ID (it was /dev/sdk, so I knew which SATA controller it was going in, so it was easy to identify), then shutdown the system and taken the HDD out. It was either “spin_retry_count” or “when_failed” (probably the later), telling me “FAILING_NOW - backup data!!!11! reeeee”
-
The **** server is rebooting at random times. 2 days ago, it rebooted like 4 or 5 times. I did some system updates and it had an uptime of 1 day and something, then rebooted again once today (which is when I observed the smart logs). Proxmox is reporting that I have Foreshadow , also known as L1 Terminal Fault ( L1TF ) bug (basically another one of Intel’s CPU vulnerabilities, I got an Intel Xeon X3450). But I doubt this is the issue of the reboots. And neither journalctl, nor syslog reports anything. Journalctl basically says that there is nothing wrong, while syslog reported a ****ton of RRD and RRDC update errors and only 1 line with lots of “@@@@@@” (I believe this has to be corrupted logs from the reboot) around the time the server restarted.
Any tips on how to update an Intel Server Board ( S3420GP )?
Back with other updates. I’m not sure what is happening and I can’t find any logs, but my server randomly restarts. I brought a Seasonic 430W (older) 80+ Bronze PSU, in the hopes that the PSU is the one that craps out, although the S3420GP does have a blinking Amber LED which doesn’t indicate anything (the manual says either that the RAM had too many corrected errors, the system may be too hot (doubt it), or the system may be failing, which could be possible. And ras-mc-ctl reports no errors.
Because the server keeps restarting, I can’t finish long SMART tests on the HDDs. I managed to find another defective one (which was crapping out a lot), but now I have 11x 2tb 7600rpm disks. And I got 4x 2tb 5900rpm disks on the side (will make a backup system out of them). And I got 2 defective disks laying around, will go throw them at an electronics recycle bin. I do have another similar, slightly weaker system at work which I could swap some components around (replace the motherboard and keep my RAM and CPU). I’ll keep you updated on what is to happen next (this has basically become an old HDD-related build log).

Just replaced the PSU. Let’s see how it fares. I had just the right size of cable length and just so happened that I had the exact number of adapters I needed. I wish I had some sata male to molex or sata male to sata female (I only have Berg to sata and molex to sata) to extend some, but whatever, as long as it works, I’m happy…
1 Like
I’ve had a couple of molex to SATA extenders before, like the one in the pic. Till one literally caught fire while in use. Now I don’t use any. But it is hard to get cable sets for modular psu’s with the right connectors, let alone non-modular ones.
One benefit of old enterprise servers, is the power setup is pretty solid, even if they are loud.
1 Like
That happened to me as well on a 5v cable (the red one) on those kind of connectors. Thankfully, I smelled the burnt plastic in time to prevent it from blowing up or catching on fire. But unfortunately, this PSU is non-modular.
1 Like
I understand, and with all the drives, it’s a compromise that has to be made.
1 Like
Ok, latest update. I had a bad stick of RAM, it wasn’t reporting any error, as mentioned, ras-mc-ctl didn’t see it as bad. I tried my RAM in another server at work, tested it with memtest86 and it also froze (reported no error). Lucky me that the Intel server that I tested this old RAM on had an amber LED light up, indicating the bad RAM while memtest86 was frozen. Took it out, found 2 other 8gb ECC DIMMs of the same model number (lucky me again), tested them. They work fine, no more freezes or random restarts. They work in single channel mode (duh) and at lower speed (800MHz) than they would if they were in dual channel (1067MHz), but i wanted capacity (sweet 24gb of RAM) over speed. Franken2 is now stable.
I went with RAIDz2 with 10 disks and 1 spare. I almost threw the system out when randomly 1 disk disappeared from the pool and from the system. Looking in logs at system messages, it appeared that the sata link was too slow and at the end, the port entered failed-state and disabled itself, lol. It was a bad sata cable, replaced it with an identical one and now it works. Removed and added the disk back in the zpool as I originally configured it and everything is fine. Cloning a 26gb VM, it appears to write with 1.01% / second, so that translates to around 260mbps. Notbad.jpg. I used ashift 9 when creating the pool. Pretty happy about it, hope it will last me for a while.
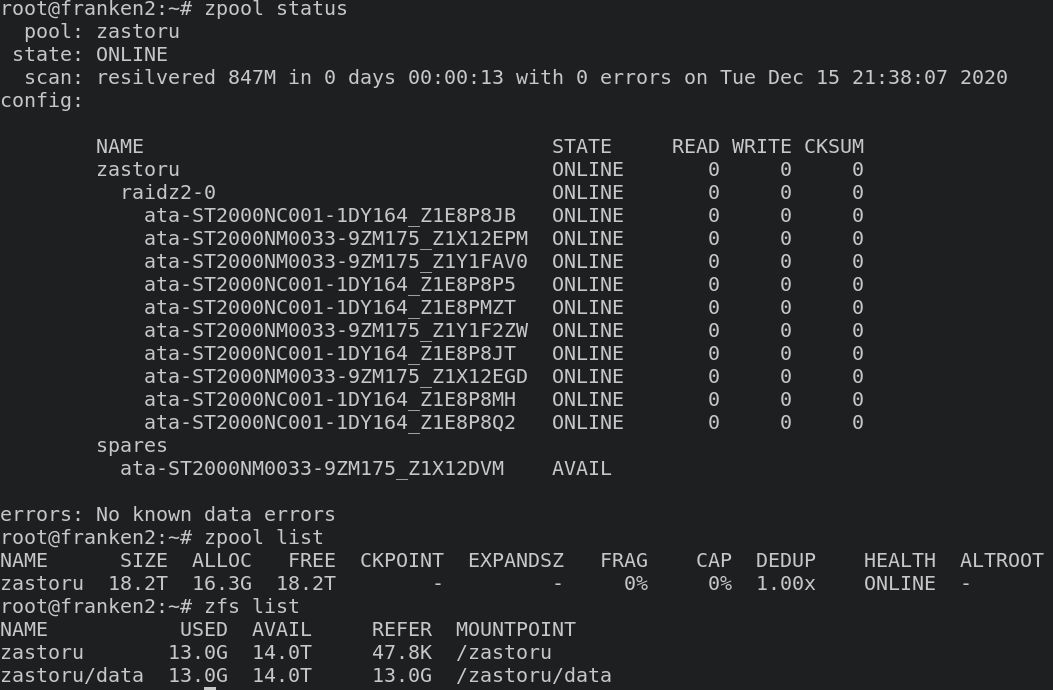
Ooops, just now I noticed I haven’t enabled compression… lz4 enabled now. Thankfully not much data was written on it yet. I have no idea how to scrub, so I should probably research this. I created a wireguard VPN between the sites, the DVR started writing recordings on the VM (I gave it 3TB, the DVR’s internal HDD has 2TB, so it should be plenty for offsite backup).
Now I need a distro that I can trust will work, that I know how to manage and that has packages / repos for some software I need, mainly Zabbix or Prometheus (I’d like to go with the later). CentOS used to be my go-to, but RedHat FML. I am too impatient to wait to see how Rocky Linux will evolve, so it’s either CentOS Stream (which I’m somewhat certain that it’s ok for home use), Oracle Linux (of which I kinda like UEK), or maintaining my own installation from source in Alpine (I really like Alpine and I don’t like docker)… oh, Void Linux has both Zabbix and Prometheus in its main repo. Brilliant, just found my distro for Prometheus and probably more stuff (mail and Matrix server). I just love Void (btw).
I will be monitoring the pool and the disks to catch any potential crashes, but given that they haven’t failed the second I started writing data on them, they should be fine (I still don’t count on them). This thread has become more of a blog post, so I will mark @misiektw’s comment as answer, because he really convinced me to go raidz2, despite me being VERY reluctant at the beginning. If anything changes and the spinning rust is too rusty for the job, I may be switching to a saner mirrored vdev from 6 disks and have 4 hot spares or something (6TB should still be plenty for what I need if I don’t host a peertube instance).
I initially wanted this to be a post for garbage collectors like myself, using very used HDDs at home, but as you can probably see, I’m too talkative to keep the topic straight. Again, I’ll update the situation of the RAID config if other disks are going to fail (they are reporting old age and pre-failures, so I am bracing myself for the worst).
1 Like
Just a question, are you aware of the thing you will have to check when replacing a drive?
But looking real good so far, with the trouble shooting and the investigation!
Just put this line in your crontab:
/sbin/zpool scrub zastoru
That’s it. Of course preferably pick a time when you’re not using it. Interval anywhere between week and month should be fine.
Also remember to configure smartd to send you an email if disk is failing.
3 Likes
Doesn’t it set up a monthly scrub when you install the zfs tools? And one can trigge one at any time with just a scrub?
Maybe some distros. So far I had to do it manually. Cron I mean.
2 Likes
Might it be worth suggesting something like zfs-auto-snapshot or sanoid or something too? for regular snapshots, with rotation?
Or doing a recursive snapshot in the crontab?
2 Likes
Sure, if they’re available. I just use my own scripts for almost 8 years, so not really checking new projects in that regard. So can’t really comment what is useful.
2 Likes
I’m not sure I understand the question (other than serial number to see which one to take out). You mean the sector size and specs of the drive, or?.. I don’t want to invest in this build, this is just a junkyard build, mostly for testing and me having some fun. I won’t be buying new disks for it. This is why I’m testing to see what disks could potentially kick the bucket and redo the zpool accordingly to compensate.
Thanks, didn’t expect to be this easy. I also ran it manually and it repaired 0 errors (well, with almost no data, I didn’t expect anything much).
I don’t have a mail server yet and I won’t setup an external one. I’m just monitoring it manually for now. Just had 3 read and 127 write errors (zpool status) on the disk I thought had a bad cable yesterday. Log messages shows that between 23:31:11 and 23:31:39 I had the disk randomly get kicked out of the system and then back in:
Summary
Dec 15 23:31:11 franken2 kernel: [ 6951.804026] ata3: SATA link down (SStatus 0 SControl 300)
Dec 15 23:31:12 franken2 kernel: [ 6953.104090] ata3: SATA link down (SStatus 0 SControl 300)
Dec 15 23:31:12 franken2 kernel: [ 6953.104097] ata3.00: disabled
Dec 15 23:31:12 franken2 kernel: [ 6953.104167] zio pool=zastoru vdev=/dev/disk/by-id/ata-ST2000NM0033-9ZM175_Z1X12EPM-part1 error=5 type=2 offset=19200876032
size=8704 flags=180880
Dec 15 23:31:12 franken2 kernel: [ 6953.104175] ata3.00: detaching (SCSI 2:0:0:0)
Dec 15 23:31:12 franken2 kernel: [ 6953.104293] zio pool=zastoru vdev=/dev/disk/by-id/ata-ST2000NM0033-9ZM175_Z1X12EPM-part1 error=5 type=1 offset=270336 size=
8192 flags=b08c1
Dec 15 23:31:12 franken2 kernel: [ 6953.104362] zio pool=zastoru vdev=/dev/disk/by-id/ata-ST2000NM0033-9ZM175_Z1X12EPM-part1 error=5 type=1 offset=200038889062
4 size=8192 flags=b08c1
Dec 15 23:31:12 franken2 kernel: [ 6953.104404] zio pool=zastoru vdev=/dev/disk/by-id/ata-ST2000NM0033-9ZM175_Z1X12EPM-part1 error=5 type=1 offset=200038915276
8 size=8192 flags=b08c1
Dec 15 23:31:12 franken2 kernel: [ 6953.109878] sd 2:0:0:0: [sdc] Synchronizing SCSI cache
Dec 15 23:31:12 franken2 kernel: [ 6953.109907] sd 2:0:0:0: [sdc] Synchronize Cache(10) failed: Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Dec 15 23:31:12 franken2 kernel: [ 6953.109908] sd 2:0:0:0: [sdc] Stopping disk
Dec 15 23:31:12 franken2 kernel: [ 6953.109914] sd 2:0:0:0: [sdc] Start/Stop Unit failed: Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Dec 15 23:31:13 franken2 kernel: [ 6954.371962] ata3: SATA link down (SStatus 0 SControl 300)
Dec 15 23:31:13 franken2 kernel: [ 6954.411057] ata3: limiting SATA link speed to 1.5 Gbps
Dec 15 23:31:19 franken2 kernel: [ 6960.200027] ata3: link is slow to respond, please be patient (ready=0)
Dec 15 23:31:22 franken2 kernel: [ 6963.612085] ata3: SATA link up 1.5 Gbps (SStatus 113 SControl 310)
Dec 15 23:31:22 franken2 kernel: [ 6963.631802] ata3.00: ATA-9: ST2000NM0033-9ZM175, SN03, max UDMA/133
Dec 15 23:31:22 franken2 kernel: [ 6963.631805] ata3.00: 3907029168 sectors, multi 0: LBA48 NCQ (depth 32), AA
Dec 15 23:31:22 franken2 kernel: [ 6963.634593] ata3.00: configured for UDMA/133
Dec 15 23:31:22 franken2 kernel: [ 6963.634810] scsi 2:0:0:0: Direct-Access ATA ST2000NM0033-9ZM SN03 PQ: 0 ANSI: 5
Dec 15 23:31:22 franken2 kernel: [ 6963.635193] sd 2:0:0:0: Attached scsi generic sg2 type 0
Dec 15 23:31:22 franken2 kernel: [ 6963.635254] sd 2:0:0:0: [sdc] 3907029168 512-byte logical blocks: (2.00 TB/1.82 TiB)
Dec 15 23:31:22 franken2 kernel: [ 6963.635268] sd 2:0:0:0: [sdc] Write Protect is off
Dec 15 23:31:22 franken2 kernel: [ 6963.635303] sd 2:0:0:0: [sdc] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
Dec 15 23:31:22 franken2 kernel: [ 6963.697674] sdc: sdc1 sdc9
Dec 15 23:31:22 franken2 kernel: [ 6963.698583] sd 2:0:0:0: [sdc] Attached SCSI disk
Dec 15 23:31:23 franken2 kernel: [ 6963.984293] ata3: hard resetting link
Dec 15 23:31:24 franken2 kernel: [ 6965.590390] ata3: SATA link down (SStatus 0 SControl 310)
Dec 15 23:31:24 franken2 kernel: [ 6965.606812] ata3: hard resetting link
Dec 15 23:31:26 franken2 kernel: [ 6966.896168] ata3: SATA link down (SStatus 0 SControl 310)
Dec 15 23:31:26 franken2 kernel: [ 6966.902397] ata3: hard resetting link
Dec 15 23:31:27 franken2 kernel: [ 6968.180148] ata3: SATA link down (SStatus 0 SControl 310)
Dec 15 23:31:27 franken2 kernel: [ 6968.180160] ata3.00: disabled
Dec 15 23:31:27 franken2 kernel: [ 6968.180194] sd 2:0:0:0: [sdc] tag#27 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Dec 15 23:31:27 franken2 kernel: [ 6968.180196] sd 2:0:0:0: [sdc] tag#27 Sense Key : Illegal Request [current]
Dec 15 23:31:27 franken2 kernel: [ 6968.180199] sd 2:0:0:0: [sdc] tag#27 Add. Sense: Unaligned write command
Dec 15 23:31:27 franken2 kernel: [ 6968.180202] sd 2:0:0:0: [sdc] tag#27 CDB: Read(10) 28 00 e8 e0 84 00 00 00 d0 00
Dec 15 23:31:27 franken2 kernel: [ 6968.180270] ata3: EH complete
Dec 15 23:31:27 franken2 kernel: [ 6968.181777] ata3.00: detaching (SCSI 2:0:0:0)
Dec 15 23:31:27 franken2 kernel: [ 6968.185661] sd 2:0:0:0: [sdc] Synchronizing SCSI cache
Dec 15 23:31:27 franken2 kernel: [ 6968.185699] sd 2:0:0:0: [sdc] Synchronize Cache(10) failed: Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Dec 15 23:31:27 franken2 kernel: [ 6968.185701] sd 2:0:0:0: [sdc] Stopping disk
Dec 15 23:31:27 franken2 kernel: [ 6968.185711] sd 2:0:0:0: [sdc] Start/Stop Unit failed: Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Dec 15 23:31:28 franken2 kernel: [ 6969.464234] ata3: SATA link down (SStatus 0 SControl 300)
Dec 15 23:31:29 franken2 kernel: [ 6970.768204] ata3: SATA link down (SStatus 0 SControl 300)
Dec 15 23:31:35 franken2 kernel: [ 6976.584361] ata3: link is slow to respond, please be patient (ready=0)
Dec 15 23:31:39 franken2 kernel: [ 6980.404353] ata3: SATA link up 3.0 Gbps (SStatus 123 SControl 300)
Dec 15 23:31:39 franken2 kernel: [ 6980.405267] ata3.00: ATA-9: ST2000NM0033-9ZM175, SN03, max UDMA/133
Dec 15 23:31:39 franken2 kernel: [ 6980.405269] ata3.00: 3907029168 sectors, multi 0: LBA48 NCQ (depth 32), AA
Dec 15 23:31:39 franken2 kernel: [ 6980.406366] ata3.00: configured for UDMA/133
Dec 15 23:31:39 franken2 kernel: [ 6980.406561] scsi 2:0:0:0: Direct-Access ATA ST2000NM0033-9ZM SN03 PQ: 0 ANSI: 5
Dec 15 23:31:39 franken2 kernel: [ 6980.406920] sd 2:0:0:0: Attached scsi generic sg2 type 0
Dec 15 23:31:39 franken2 kernel: [ 6980.407064] sd 2:0:0:0: [sdc] 3907029168 512-byte logical blocks: (2.00 TB/1.82 TiB)
Dec 15 23:31:39 franken2 kernel: [ 6980.407093] sd 2:0:0:0: [sdc] Write Protect is off
Dec 15 23:31:39 franken2 kernel: [ 6980.407123] sd 2:0:0:0: [sdc] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
Dec 15 23:31:39 franken2 kernel: [ 6980.474631] sdc: sdc1 sdc9
Dec 15 23:31:39 franken2 kernel: [ 6980.475166] sd 2:0:0:0: [sdc] Attached SCSI disk
I’m again thankful for all the support. You guys rock.
1 Like
I was hoping to point out that ashif=9 ties you to 512 byte sector sizes, which may cause performance issues if you have to replace a drive, and get one which is “Advanced Format” or has 4K sectors.
But I guess you would probably just replace a dead drive with an older one off eBay, and older 2TB drives are mostly 512 bytes anyway…
Nevermind, looks like you are getting along well with it, so will leave you in peace
1 Like
Sure it looks like disconnecting cable. That’s why I said earlier that using sata for many disks is a headache. They are very unreliable.
But zfs handles those errors very gracefully, to the point that any “normal” raid controller would loose your data.
Here’s extreme case of sata links failing, but zfs recovering anyway:
https://forum.level1techs.com/t/storage-server-bugging-out
1 Like
I appreciate all the information I can learn about ZFS, for future builds and hopefully future jobs. And oh sh*t, I didn’t even realize that I got some 4K sector size disks 
fdisk -l /dev/sdc
Disk /dev/sdc: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
Disk model: ST2000NM0033-9ZM
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
fdisk -l /dev/sdb
Disk /dev/sdb: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
Disk model: ST2000NC001-1DY1
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: gpt
Disk identifier: B8214A1C-3C7D-DD4A-ABBA-1CF7DE80B4FD
I wanted more storage, but I guess what I have is a little excessive. Time to redo the zpool with ashift 12?  I’m all in your hands guys. I’m not sure how I forgot the sector size.
I’m all in your hands guys. I’m not sure how I forgot the sector size.
@misiektw Well, I technically have 4 SATA controllers (the on-board one and 3x PCI-E expansion cards, each with 2 SATA ports). But this is good to know. Thanks for the info.
2 Likes