I am migrating some files from a QNAP NAS to a Debian+OpenZFS NAS I just put together. It is virtualized, but using PCIe passthrough on Proxmox and ASRockRack X570D4U-2L2T. Both devices have 10Gbps NICs and are connected at 10Gbps.
I installed 2TB Samsung 980 Pros for SLOG as this server will have bursty writes of 10-100GB that I want to ensure saturate the full 10Gbps link which my 4 SATA HDD pool likely cannot keep up with.
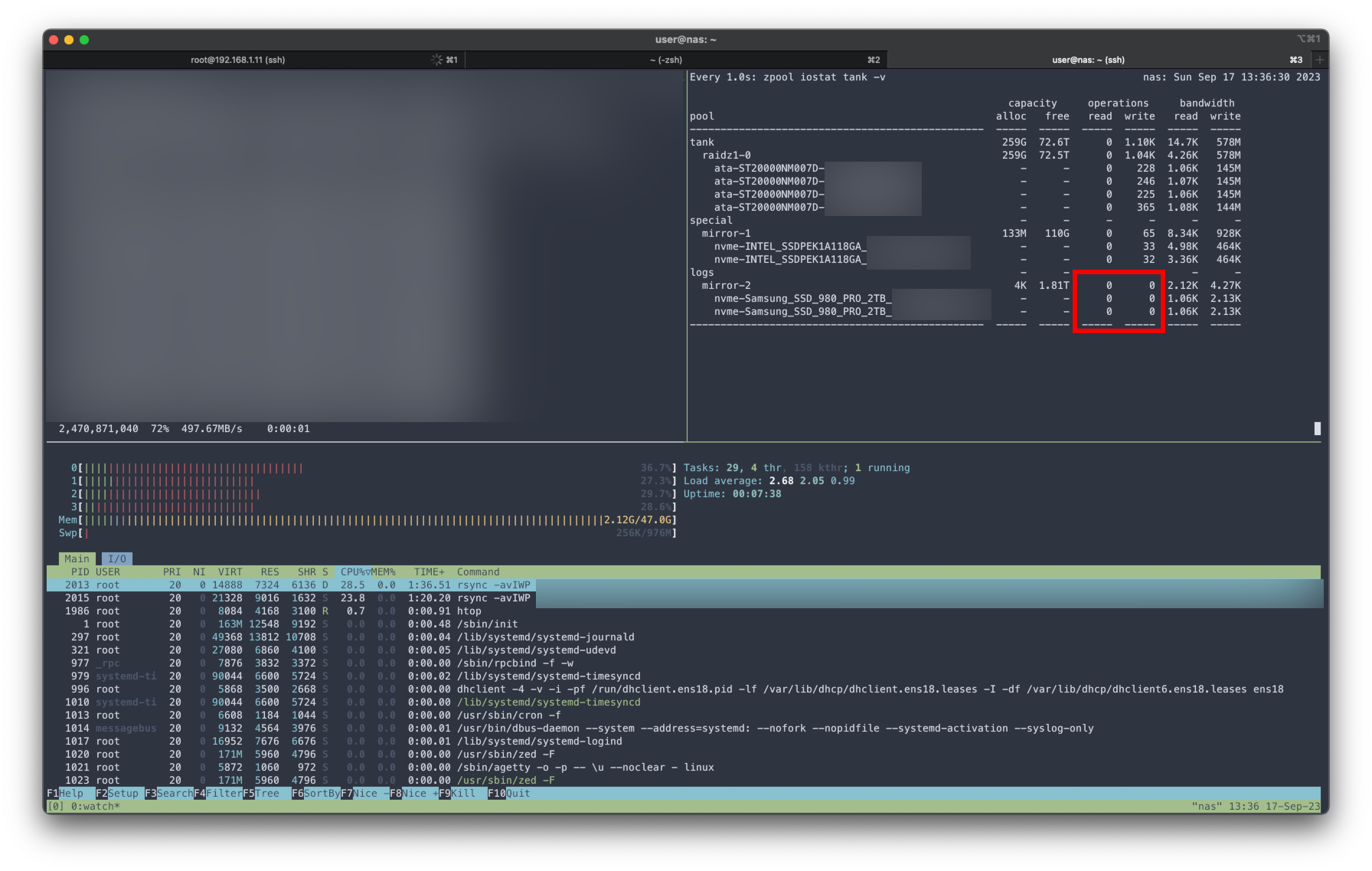
I noticed the SLOG doesn’t appear to be used at all, and my transfer is limited to ~500MB/s (~5Gbps). I haven’t set up a SLOG with ZFS before, does anyone know what is going on?
SLOG only works and accelerates sync writes, which will get you to maybe 80% async performance. If SLOG isn’t getting any IOPS, they are already handled by main memory instead of the two NVMe which is just better.
Async performance (most writes are async) is limited by the drives performance however. You can’t make those 4 HDDs faster than their sequential speed, which is 150-250MB/s per drive on modern drives. And if using RAIDZ, it’s even slower in general. Parity RAID = lots of capacity + sucks at writes
I get full 150-250 MB/s per mirror vdev. ZFS is very good at aggregating all the async writes into perfect sequential workload.
500MB/s with a single vdev is ok. Just keep in mind that RAIDZ slows down as the pool ages and gets filled. Your pool will eventually converge to 100-200MB/s as it fills up and ages.
Only way to get 10Gbit writes is either with good compression ratios, more drives (more vdevs) and/or mirrors.
I don’t understand what you mean by this. Everything always goes through main RAM first, no way around that. But I expected RAM to dump to the SLOG (which can easily handle 10Gbps from the network) which would flush to the HDD vdev (which seems to be limited to ~5Gbps) as the HDDs are able.
If the writes are async, there is no need for a slog as an intermediate storage. Log devices are purely for sync writes that demand to be immediately written to disk (which is slow because ZFS can’t aggregate them into sequential writes). A log isn’t a write cache. It only stores the data (as an assurance) so the data doesn’t remain in (volatile) main memory in case of a power failure in the system.
Oh and no need for 2TB. A log only needs 16GB of capacity. Basically 5 seconds worth of maximum write throughput, so 8GB will be plenty for a 10Gbit connection, but I always say 16GB just in case network or settings change. You want to use that capacity for other things by partitioning the drives.
you can enforce using the Log by setting sync=always. But it will just make everything slower, but will assure you that the log is working properly. By using iostat as you already did or in arc_summary
Wouldn’t be getting 10Gbps rather than 5Gbps be a reason? Between not hitting the HDDs directly and not needing to calculate parity at write time (SLOG is mirrored) the higher throughput seems like an easy win for bursty workloads without risking data loss.
I guess if it is not being treated as a write cache the behavior makes sense, but I don’t see the value in the SLOG if it doesn’t perform in this way.
No it doesn’t. But if you are dealing with sync random writes, having a log is a blessing because it handles like normal async writes. No screaming write heads and angry drives with 1-10MB/s writes dragging down the pool.
ZFS makes the drives as fast as they can possibly go and is very good at it. If you want more performance than sequential write of your disks, look for other options or optimize your pool config to allow the required write throughput.
I’d keep the log just for e.g. NFS stuff. 16GB of NVMe is dirt cheap/bassically free if you got the drives anyway.
The server will be a NFS server (it’s currently a client for this migration) which will be used by compute nodes (K3s) for long term storage of media files, and as a backup target (for Longhorn). Each worker node will have 2.5Gbps NIC. Is it still worthwhile to keep the SLOG or should I just reuse these elsewhere?
NFS uses sync a lot to remain consistency across server and clients. So you will run into sync writes eventually. Enough that it matters and that it keeps the pool busy? Who knows…but if you need a log, you really need it.
I personally don’t like random access noise from my HDDs. It’s mechanical stress, annoying to hear and slow. Always reminds me of the 90s back when I had my swap on HDD. I want my drives to always write clean and big chunks instead of chasing bytes across the platter.
I’d partition the drive and give each drive a 16GB partition and use that for the log. Unless you absolutely have no use for NVMe in that server otherwise.
I know several users here have both cache and log on the same NVMe drive on seperate partitions or namespaces. I wouldn’t call it best practice, but it’s very convenient because PCIe lanes and NVMe slots aren’t free and log just needs 16GB.
In that case, I’ll probably just swap in smaller NVMe. No need to waste 2TB on this. The ARC hit ratio is relatively low, so using the rest for L2ARC doesn’t make sense either.