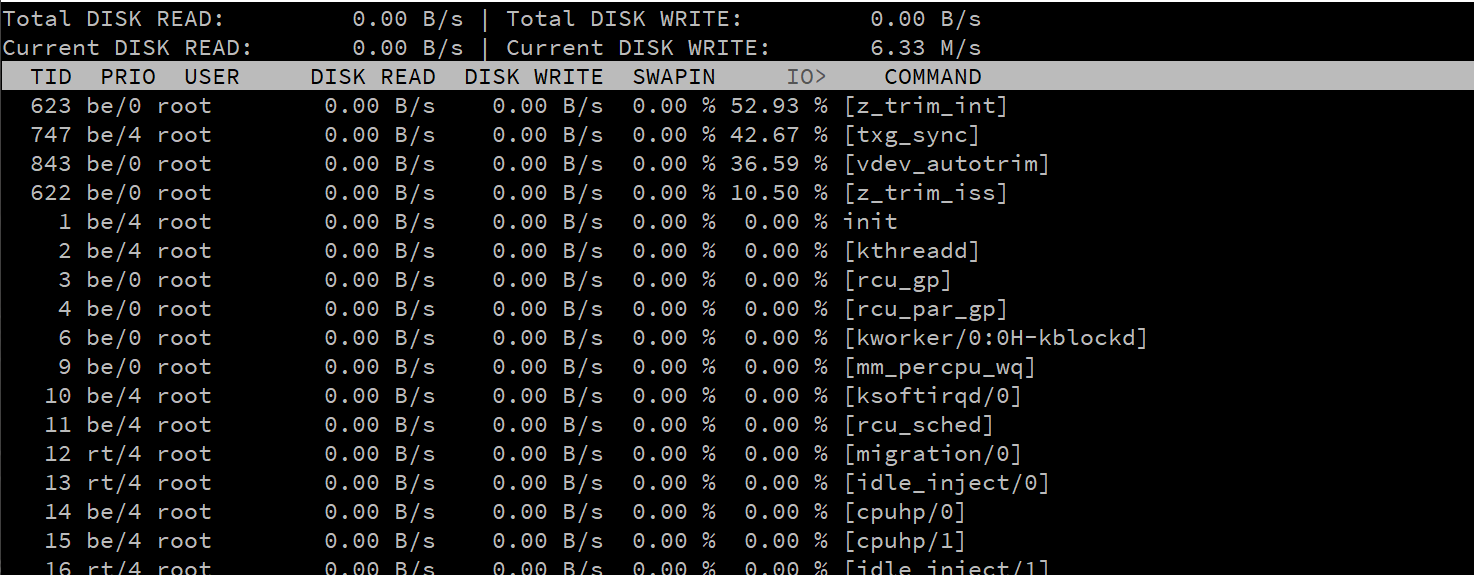
The process I have found that is eating up I/O but NOT doing any read or writes is [txg_sync] and [z_trim_int]… I have found some information from searching but not definitive answers on fixes.
The problem seems to occur when plex is recording to my DVR drive which is a SSHD (I used this because it was cheap) that also has a 1TB samsung SSD as cache and SLOG. Yet plex is installed on the rpool of a pair of 500GB ssd’s in RAID1. Did I make a mistake using this configuration? Should I have installed directly onto the DVR drive? I dont know if plex is DVR recording to the rpool first then to the DVR drive and that is slowing things down… I could really use some help though if anyone has some ideas.
Yes it has been awful, I dont know if its the hybrid drive if they dont work well with linux or what. I tried removing the cache, but it still seems to be awful.
It will jump up to 20% at times or higher when reading from opr writing to that drive, but the smart data and drive tests all come back and its fine…
I think it may be the issue. Im going to try replacing it with a straight spinner to see if that fixes the issue. I thought it might be a problem having the vm installed on the local rpool drive but having a lot of data written to and from the dvr drive. Im going to test it here shortly see if the drive is the problem. Because it is written to and from so often I wanted a cheap option but I guess I have to go a different route.
@Dynamic_Gravity I was under the impression having a cache or a SLOG should speed up the I/O for a drive. Is that not true? I have a cache also for my main media library that is a raid 10 of 4 drives…
It depends on the type of data and workload. Your workload is not an enterprise one with extremely hot datasets. Cache and SLOG are useful but really only come into play under specific requirements that 99.999% of home lab users will not experience. Don’t waste your time with these unless you write RAW 4k footage all day every day, or have literally millions of small tiny files.
I figured, I was just experimenting. Good to know that information. Thank you so much. Any idea what those two processes are? I was hoping to figure out what is happening to better understand the issue I am having. Just for personal knowledge. I like to understand how things work and what is happening to cause the problem is.
The ZFS ZIL is not used as a traditional write cache. When you have no dedicated SLOG device, the ZIL is stored on the pool itself, but it still is used in the same way. Writes that come into the pool are written to the ZIL (no matter where it is located) but the ZIL is never read from unless there is a failure. When the pool is ready to persist the data, it still flushes the data from the RAM buffer directly to disk, it does NOT read the data from the ZIL (or dedicated SLOG device) in order to flush the data to the persistent pool.
Because of this behavior, the ZIL/SLOG device is mostly relevant for performance when you are using sync writes. Sync writes tell the system to not return an I/O as complete until the data has been flushed from the buffer to the persistent pool. In this case, ZFS will return the I/O as complete when it has hit the SLOG device, but that doesn’t mean it has been hardened to the pool yet. That process still requires that the RAM buffer is flushed to disk at a later time. If you are using async writes, then the I/O will return complete as soon as the data is in the RAM buffer, no matter if it has been written to the ZIL yet or not. In the case of async operations, the ZIL will actually live in RAM itself - it will not be a persistent log on disk and you will run the risk of losing the data in the case of a crash.
Thank you @Ghan for the great into and @Dynamic_Gravity as well. I am still learning. I try to make small changes and keep them in my play book to revert things as I do them. I will work back on my data pools. I was using a small 32 GB Intel Xpoint optaine drive as SLOG just to try to keep my data safe till I got a decent UPS that will interface well with Proxmox. This weekend I will pull the system down and try to change up the drives to see what happens and run it without cache or SLOG. The main media library has a Data center level SSD so I dont worry about it so much because it does have the capacitor to keep cache alive from what I understand.
From a performance perspective, a dedicated SLOG device such as you describe (I’m using an Optane drive myself for my ZFS pool) will help by reducing write latencies since the I/O can return as soon as the fast SSD has written the data. (Sync writes only!) However, this won’t help your overall throughput over time, since that will still be limited by the speed of the pool. The dedicated SLOG device just lets your pool smooth out random writes by allow the RAM buffer to collect and flush writes in groups at a regular interval instead of forcing the application to wait until the flush happens before returning the I/O operation.
Thank you, I know its overkill for my application but I’m just trying to set up enterprise level items to implement them and see them work or make them work. Its a lot of experimentation. Thank you so much for the info. Some of the stuff I look up is hard to read or find a definitive “answer” in forums or see if the issue was resolved. I will keep this updated on my progress to see if the drive was the issue.
As for SLOG, I know I dont need it, but I wanted to play with it and keep a safety in place. (I have on and off site backups, so not worried but experimenting) I will probably keep this in play despite most of my reads and writes are all sequential for the most part at this time.
I just wondered if maybe it was the SHDD, if anyone had similar issues, or if I set up ZFS wrong in some way, or I having my vm on a diffrent drive was causing the issues…I just thought I’d ask.
No worries! I’m not making any recommendations one way or the other - just helping to explain what is going on so you can make more informed decisions.
Also note that the cache (L2ARC) device would help in a very read-intensive workload since it keeps frequently accessed data cached. However, there is a caution here because ZFS needs to use some RAM to keep track of the L2ARC itself. So you end up losing some primary ARC space in RAM to manage the L2ARC. Depending on the workload, this can actually end up reducing performance!
As for your specific issue here, I would make sure to check all the block sizes involved - that is a frequent performance issue with any kind of ZFS deployment. Based on what I posted above, I would definitely test removing the 1 TB cache drive and see how the SSHD behaves when it is acting alone. I’ve never run Proxmox with ZFS so my knowledge in that area will be a bit limited.
Oh no, thats fine. Thank you for explaining thats what I was here for and why I love this forum. I do know L2ARC is very agressive and uses up to 50% of my ram. That why I’m also taking down the server this weekend to add 32 more GB of ECC ram for 64GB total. Its been a really fun project as I go through my linux books and manuals for proxmox and other distros I am playing with. I’m toying with the idea of installing a GUI on top of proxmox like debian just so I can can have it up and monitor it live on another monitor and make changes a bit easier as I work my way into being able to use the CLI for everything.
Im also toying with installing another “node” on another machine I have running Fedora 33. I do most of my experimenting on at the moment as I learn.
Another thing you may want to try with ZIL on optane is sync=always. This will have the effect of forcing all writes to ZIL / optane first, which may end up being faster than forcing only some writes and waiting on spinning rust for other stuff… Just because optane is so much faster.
An slog + forced sync writes cannot and will not accelerate writes to the main pool.
Forced Sync writes destroy performance because ZFS is having to make double sure that everything is accounted for in case of power failure. It does this by making additional writes to the pool. All an SLOG does is redirect that added load. It cannot make the normal pool write faster. It is also never read from, unless the system crashes.
Be aware that some things, like NFS force sync writes by default (this can be changed). This is why many people add an slog and find better performance, it’s because they were gimped before. It’s best to let applications decide if they need sync writes.
Awesome, thanks for the tips… people must be getting off work… was slow a while lol I’ve been playing around with installing gnome over proxmox…trying to see if it will be useful on another system when i bring the server down anyway for disk changes and possibly migrating my vms to the new machine I just got working.