With Wendell featuring ZFS and homeserver in quite a lot of videos on L1Techs, we as a community have regular forum threads dealing with homeserver and storage in all kinds of ways.
The intention of this thread is to give an overview on what ZFS is, how to use it, why use it at all and how to make the most out of your storage hardware as well as giving advice on using dedicated devices like CACHE or LOG to improve performance.
I will also mention several easy to apply tuning parameters that will tailor ZFS behaviour to your specific use case along with listing the most important pool- and dataset properties you need to know for proper administration.
1.1 What is ZFS
ZFS is a filesystem like FAT32,NTFS,ext4 for your storage and volume manager at the same time. No maximum file sizes, no practical limit on the size of volumes, grow/shrink partitions at will, copy-on-write principle = no chkdsk ever again, you can’t corrupt the filesystem, snapshots to restore previous states of a filesystem in milliseconds, self-healing of corrupted data blocks and a hundred other features that makes ZFS a carefree experience and solves many problems we all hated when dealing with storage in the past.
The thing ZFS excels at is to only return the data you gave it. Integrity is paramount. If ZFS sees drives reporting errors, it will fix things with redundant data from other drives. If it can’t, because too much drives failed, it will shutdown and lock the pool to prevent further corruption. Other filesystems just don’t care at all resulting in lots of corrupt data until you realize it’s too late.
1.2: There are two ZFS out there? Which one is for me?
There are two kinds of ZFS: The proprietary Oracle ZFS used in their ZFS Storage Appliances and the open source OpenZFS project which was forked a decade ago after Sun Microsystems went to hell. Most of the code is the same which is why you can check Oracle website for administration guides as the core of ZFS remains the same. There are specific features unique to both branches as projects had different priorities regarding features over the last decade.
When I talk about ZFS, I’m always referring to the OpenZFS project as most people here in the audience probably aren’t engaged in the Oracle ecosystem or buy million dollar Storage Appliances for their homelab.
What kind of stuff do I need to build a server?
Not much. An old quad core with additional RAM and proper Network card will be fine.
More cores are better to enable higher compression. From my experience, 6 Zen3 cores will do 10Gbit streams with ZSTD compression just fine. 1G or 2.5G isn’t a problem for any CPU built in the last decade.
You want an extra SATA or NVMe drive as a read-cache. When using HDDs, even an old 240GB SATA SSD will improve things quite a bit for your reads.
It’s rather easy to overbuild a server. So start with little but with room for expansion. Practical use will tell you where deficits are. Adding RAM, more drives, more cache can be added later on.
Overkill doesn’t make things faster, it just makes things more expensive
1.3: How do I get it?
Being Open source, check out Github, otherwise OpenZFS is available on Illumos, FreeBSD and Linux in most repositories. MacOS and Windows have experimental versions which are very much development builds.
Ubuntu 22.04 (and some derivatives like Zorin), Proxmox and TrueNAS ship with ZFS by default and Unraid has a plugin that adds ZFS capability.
Other than that, commercial NAS systems from QNAP (the more expensive 1000$+ models) as well as iXSystems server are preconfigured for ZFS.
But nothing is stopping you from installing ZFS on e.g. Ubuntu server and make your DIY storage server.
Caveats in Linux, why ZFS has no native support and why it can break your system
ZFS isn’t licensed under the GPL (it uses CDDL) and can’t join ext4 or BTRFS as an equally treated filesystem in Linux for this reason.
While FreeBSD uses ZFS as their default filesystem for the root partition, Linux users have to tinker quite a bit to get the so called ZFS-on-root. This is very much the stuff for experienced Linux users. So if your distro (most don’t) doesn’t offer ZFS at installation, you’re out of luck. Or you use the OpenZFS documentation or other guides how to get ZFS on your root partition.
But having an ext4 or BTRFS boot drive and using ZFS for other drives (e.g. /home) is a compromise with much less work involved. Installing the package and creating a pool is all you need then.
But being not part of the Kernel means the OpenZFS team has to ship a new DKMS for every new kernel out there. This doesn’t always happen in time and leading edge distros may find themselves in a situation with a kernel and no compatible ZFS DKMS. The data won’t be lost, but if you can’t load ZFS module, then you can’t access your stuff. Particularly troublesome with ZFS as your root partition.
So I don’t recommend using ZFS on leading edge distros. Debian, Ubuntu or generally LTS/Server Kernels are the safe bet when using ZFS.
We all wish it would be different, but licensing and lawyers prevent us from having the good stuff.
1.4: What hardware is required?
ZFS runs on commodity hardware and uses free memory to cache data. There is no special requirement for ZFS. It is often said that ECC RAM is required, but that isn’t true. It’s a recommendation. And using ECC RAM is always recommended, not just for ZFS. So ZFS isn’t different from using e.g. NTFS in that regard.
And ZFS doesn’t like RAID cards at all. Or BIOS RAID. It just wants standard unaltered drives, from your SATA/M.2 port or an HBA.
1.5: ZFS uses a lot of RAM?
ZFS will grab large portions of unused memory (and give it back to the OS if needed elsewhere) to cache data, because DRAM is fast while your storage is slow. Unused RAM is wasted RAM.It’s essentially like a dynamic and intelligent RAMDisk where the most recently and frequently used data is stored so that data is accessed at main memory speed. 30GB/sec Crystal Disk mark stats in your VM while using HDDs? Yeah that’s proper ZFS caching at work.
In fact it is rather hard to measure actual disk performance, because ZFS optimization and caching is omnipresent.
Otherwise ZFS runs fine on systems with just 8GB of memory. It just can’t use many features to speed things up with no memory to work with. In this case you can expect below average filesystem performance and slow disks, pretty much how storage looks elsewhere.
2. Pool config and properties
With all things storage you have to decide on what the priorities are. The magic storage triangle consists of capacity, integrity and performance. It’s a classical pick 2 out of 3 dilemma.
capacity
/\
/ \
/ \
/ \
performance /________\ integrity
ZFS offers all available RAID levels, while RAID0 is called “stripe”, RAID1 is called “mirror” and RAID5 is called RAIDZ. With RAIDZ there are 3 levels each adding an additional disk for parity.
RAIDZ2 and 3 still allow for self-healing and full data integrity even if a disk has failed. Replacing a disk can take days with large HDDs being at full load all the time, so people like to have that extra safety during this critical process.
Usually, parity RAID like RAID5 have to deal with the infamous “RAID5 write hole” which can kill your RAID during a power loss. RAIDZ in ZFS doesn’t have this problem, so we don’t need a battery backup and RAID cards to deal with this flaw.
Otherwise Mirrors are probably the easiest, fastest and most flexible to work with in ZFS. You can add and remove mirrors to the pool and expansion is really easy by just plugging in two new drives. With only 50% storage efficiency, it’s always a hard sell. But the alternatives aren’t without compromises either.
No one can escape the magic triangle ![]()
You can use a pool configuration without any redundancy. You get a warning you can override, but this isn’t a recommended setup for obvious reasons.
I use ZFS on my laptop on a single disk, because I still have snapshot feature, easy ZFS to ZFS backup and ARC cache available that way. So there are valid use cases for non-redundant ZFS pools.
But any proper storage server has some level of redundancy, because no one wants to lose all of their data. Greed gets your data killed eventually.
What is a vdev and do I need one?
Each RAID or single disk is a vdev (virtual or logical device). A pool can have as many vdevs as you like. If I have a mirror of two disks, I can just add another mirror to the pool to double the storage capacity. The data automatically gets striped across vdevs, essentially making it a Raid10 now. Or a RAID50 if you add a new RAIDZ to the pool with an existing RAIDZ.
This is how expansion works: Adding another vdev to the pool. If you have a RAIDZ2 with 6 disks, you need another RAIDZ2 with 6 disks to expand. Mirrors just need 2 drives to do an expansion. Lack of flexibility for RAIDZ Expansion is a thing ZFS is often criticized for. But that’s what we’re dealing with (for now).
BUT: If one vdev dies, the entire pool dies. So make sure each vdev has the same level of redundancy. You don’t want weak links in your chain.
------------------- ARC--------------
ARC stands for adaptive replacement cache. It is the heart and nexus of ZFS and resides within main memory. Every bit of data goes through it and ARC keeps a copy for itself. As far as caching algorithms go, it’s fairly sophisticated.
Data that is used more often gets a higher ranking. If you run out of free memory, ARC will evict the data with the lowest ranking to make space for new stuff. It will prioritize to keep the most recently used (MRU) and most frequently used (MFU) data you read or wrote while also keeping a balance between those two.
So memory is fairly important. More memory, larger ARC. Less stuff has to be evicted and less data has to be fetched from slow storage. If the data is stored with compression, ARC will store the compressed state. This can result in memory of 64GB actually storing 100GB+ of actual data. That’s free real estate.
In an ideal world, we just use DRAM for storage. But the stuff is bloody expensive, so we have to deal with slow storage like HDDs and NVMe for the time being and use some tricks to make the best out of this misery.
2.1 other devices outside of disks storing user data
ZFS has several classes of devices that help and assist the pool to speed things up. Like adding an SSD to act as a read cache. We’ll talk about all of them in the following paragraphs and why you want them or why you don’t need them.
L2ARC aka cache aka read-cache
I told you that ZFS uses memory to keep the most recently used (MRU) and most frequently used (MFU) data in memory so you can access them at main memory speed.
Well, RAM isn’t cheap and there are only so much slots on your board. Thus L2ARC was invented which usually is one or more fast devices (e.g. NVMe SSD) where all the data that spills over from the ARC (main memory) gets stored on. It may have been evicted from ARC, but it is likely that this data will be used again later but your RAM was just to little to store everything.
We don’t get main memory speed if we need the data, but it’s still way faster than getting it from a HDD. And we increase the amount of data that can be cached by the size of the L2ARC device. Essentially you increased your RAM by a TB for caching purposes when using a 1TB NVMe, but making it a bit slower (DRAM vs. NVMe).
L2ARC uses (usually a very small) amount of memory to keep track of stuff that is stored in your L2ARC. For a pool with default settings this isn’t noticeable and the gains far outweight the overhead it produces.
Here some fancy table to illustrate an often misinterpreted and overexaggerated usage of L2ARC headers:
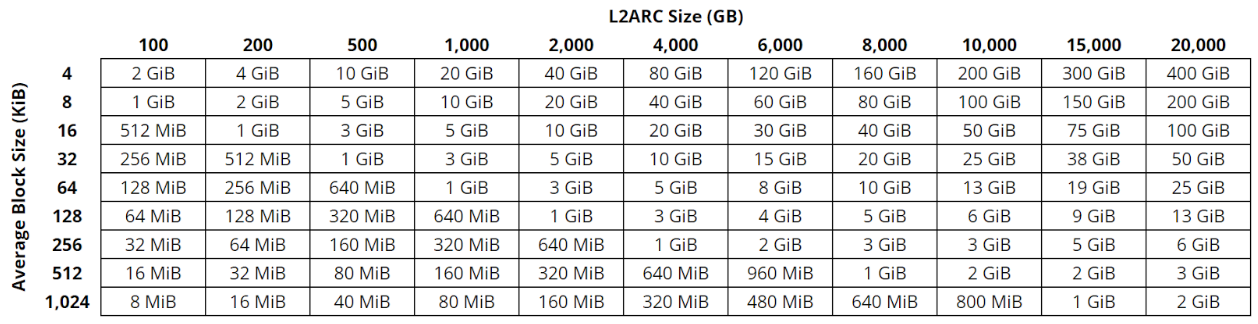
Your typical homeserver ranges from 64k to 256k average record-/blocksize. Some datasets may have less, others will have vastly more.
It’s usually a no-brainer to use L2ARC because you can cache so much more data. And you don’t need expensive enterprise stuff or redundancy because it just stores copies of stuff already present on (redundant) data vdevs.
L2ARC is probably the highest priority when deciding on what vdev to add to the pool, because caching and accelerating reads is generally desired by most people.
You will find many old guides around ZFS and L2ARC on the internet. Most don’t like L2ARC, but these were often written when L2ARC was some fancy expensive PCIe Accelerator card or very expensive 1st gen 100GB SATA. Just going for more memory was the better deal. This changed with cheap consumer NVMe being sold in supermarkets and gas stations.
You can add or remove a CACHE at any time.
SLOG aka seperate log device aka log aka “write-cache”
ZFS has no “real” write caching like one usually imagines a write cache. But first we have to talk about two kinds of writes:
ASYNC writes:
That’s your standard way of doing things. Most stuff is ASYNC. When it doubt, it’s this.
ZFS writes the data into memory first and bundles up everything in so called transaction groups (TXG) which are written to disk every 5 seconds by default. In essence it converts a bunch of random writes into sequential writes. This obviously increases write performance by quite a lot. There is nothing worse than random I/O. So this makes our HDD write at 200MB/s instead of 3MB/s. Same goes for SSDs with GBs/sec instead of 60MB/sec.
But your volatile memory gets wiped on power loss or system crashing. So having data in memory during an incident makes you lose that data. The copy-on-write nature of ZFS prevents the filesystem from corruption and you revert back to the last TXG, essentially losing the last 5 seconds.
SYNC writes:
But there are some nasty applications that insist on writing to disk immediately or they refuse to proceed with their code. This is because of data integrity concerns mentioned above, which is a valid point. Most storage isn’t as secure as ZFS. But it complicates things.
We’re now back to abyssal write performance and random writes dragging things down.
And that’s where the SLOG comes into play. All writes will go to that device which is very fast and ZFS gets to do its TXG thing as usual. After 5 seconds, SLOG gets wiped and stores the next 5 seconds of data.
We now have a physical copy on the SLOG and ready-to-flush data in memory. Power outages aren’t a concern anymore and we still get fast writes.
This needs a dedicated drive with a lot of write endurance and very good random I/O capabilities.
A mirrored pair of Enterprise-grade NAND Flash with high endurance ratings, Optane or equivalent are the recommended setup. As you only need 5 seconds worth of writes to store, 8-16GB is all you need. You can overprovision your SSD down to that amount to increase endurance.
You can remove a LOG from the pool at any time.
Here some graph with colored arrows to illustrate SYNC:
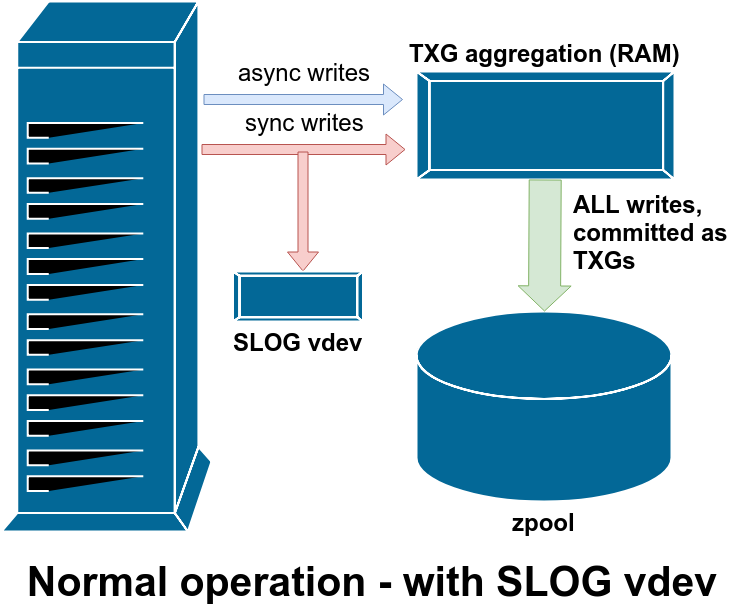
So Exard…I trust my memory and I got UPS and shit. I want to treat all applications the same. That whole SYNC stuff is slow and annoying and I don’t want to spend hundreds of Dollars and use valuable M.2 slots.
Well, you can just set sync=disabled for each individual dataset (or set it pool-wide), making ZFS just lie to the application, pretending it’s all stored on disk already while in fact it’s still in memory.
This is the highest performance option for dealing with SYNC writes. Faster than any SLOG can ever be. But the very complexity of SYNC operations still result in lower performance than ASYNC. The choice is yours, there are good arguments for both options.
You can even set sync=always so every write will be treated as a SYNC write. This obviously will result in higher load for your SLOG as every bit that is written will be written to the SLOG first. Or to your storage if you don’t use a SLOG.
If you are unsure how much of a difference a SLOG will make and what utility the concept of TXGs provide, you can change sync setting during operation at any point and test how performance and pool reacts.
I did test transferring a million small files to my pool with and without SLOG and with changing sync settings. The HDDs told me immediately (judging from screaming drive noises) what their preferences were ![]() It wasn’t a surprise, I was just impressed by how much of a difference in performance it was.
It wasn’t a surprise, I was just impressed by how much of a difference in performance it was.
So we just dealt with bad random write performance. If anyone complains about HDDs are bad at this, it doesn’t matter to you when using ZFS.
But I want a proper write cache
Just write some 50GB of data at network speed and let ZFS figure out when and how to write stuff to disk? That’s what most people imagine a write cache does. There is no such thing in ZFS for several reasons and it’s not even on the list of planned features. It ain’t gonna happen.
But ZFS has some 200 cogs to tweak things:
If you have enough memory, you can raise the limits on transaction group timeouts and the amount of dirty data within the ARC (the stuff that’s not yet written to disk) to make a pseudo-write cache. Obviously comes with a bunch of disadvantages regarding safety and general waste of memory.
But we’ll talk about zfs tuning parameters later.
— Special allocation class aka special aka special vdev —
Wouldn’t it be great to store all the small files on an SSD and the large files on HDDs? Each utilizing their own strength and negating the weakness of a particular type of storage. Usually this doesn’t work. But with ZFS you can.
Even the man himself, Wendell, raised attention for this (relatively) new and niche feature of ZFS.
Special allocation classes have multiple uses: To store metadata, to store small files or to store the table used for deduplication. This is all that nasty little stuff your HDD hates and where you get 2-5MB/sec and HDD access noise is all over the place if you have to read a lot of it. The very reason why we switched to SSDs asap.
What is metadata?
Every block has metadata associated with it. When was the block written?, whats the compression? block checksum? disk offset…basically the whole administrative package leaflet for your data so everything is correct, measured and noted for further reference. By default ZFS stores 3 copies just to make sure this doesn’t get lost.
And for each record or block, one “piece” of metadata is produced. So the amount of metadata scales linearly with the recordsize or blocksize you are using. e.g. a 8k blocksize ZVOLs produce 16x as much metadata as a 128k blocksize ZVOL.
So no one actually knows how much GB of metadata you can expect unless you tell them what record-/blocksize you usually see and use on your pool. Typically it’s maybe 0.5% of your data, but can vary greatly as mentioned above.
If you feel like small files and metadata don’t get cached by ARC+L2ARC enough, special vdev can improve things. But so does increasing cache. Or tuning parameters. Hard to tell what’s best and useful as a general recommendation.
special_small_blocks:
This is your dataset property to set the limit on how big the files on your special vdev can be, everything larger gets allocated to your standard data vdevs.
zfs set special_small_blocks=64k sets the special vdev to store only files smaller or equal to that value.
I’m personally using 128k value while my datasets usually go with 256k or higher recordsize. Value has to be lower than your recordsize to make sense.
If the device is full, ZFS just allocates further data to standard data vdevs as normal. So things don’t suddenly break if you run out of space.
Hardware recommendation for special
You want a device which is faster than your standard storage and is good at random reads. So any decent consumer SATA or NVMe will be fine. It just needs equal or better redundancy than your data vdevs. This is because the stuff actually lives there and isn’t some cache device storing copies. If special vdev dies, your pool dies. Metadata dead = Pool dead. So use a mirror or better.
You can remove a special vdev if everything else in your pool is also mirrors. If using RAIDZ, you can’t remove the special vdev.
3. Datasets and Zvols
— Datasets and properties —
Each dataset is it’s own filesystem you can mount, export and tailor to your needs. You can imagine them being folders/directories within a pool.
Generally you want to have a lot of them and not run everything in a single dataset (the pool itself is a dataset too). If you want to rollback to a previous snapshot, just restore the snapshot of the dataset. No need to rollback the entire pool. And you may not want the craziest compression for everything, but just for some purely archival datasets.
We create new filesystems with zfs create tank/movies
Upper limit on datasets is 2^48, so make use of it ![]()
There are like 50 properties. You usually can ignore most of them, some provide useful statistics but a couple of them are essential in building an efficient and well managed pool.
zfs get all tank/dataset returns a list for all of them. To check if everything looks right.
zfs get compressratio tank/dataset only returns the compression ratio from data within that dataset.
My Top10 properties (you probably run into at some point) are:
click to expand:
recordsize
Setting the upper limit on how big chunks ZFS allocates to disk. 128k is default. Datasets with purely small stuff benefit from lower recordsize while large media datasets work just fine with 1M or higher. Can speed up reads and writes. You can split a 1MB file into 256 pieces or use a large 1M box . Your HDD loves the large ones. But reading and writing the whole MB just to change a bit somewhere in the middle is far from efficient. It’s always a trade-off.
compression
set your favorite compression algorithm. LZ4 is default, really fast compared to achieved compression. ZSTD is the new and fancy kid on the block and very efficient. GZIP is available too, but slow. I always recommend to use compression. LZ4 algorithm is gigabytes per second per core just to give you an idea how cheap compression is these days.
atime
You want to turn this off immediately unless you absolutely need atime.
casesensitivity
Useful when dealing with Windows clients and everything where case sensitivity may become a problem
sync
Consult the SLOG paragraph above on why you may want to change sync
copies
You can store multiple copies of data in a dataset. It’s like a RAID1 on a single disk but only within this dataset. Useful for very important data or when you don’t have redundancy in the first place but still want self-healing of corrupt data. Obviously doesn’t protect against drive failure.
mountpoint
Well, it’s where you want the dataset to be mounted in the system.
primarycache & secondarycache
You can exclude datasets from cache. Or exclude everything by default and only allow some datasets to use cache. primary being ARC and secondary being L2ARC.
----- ZVOLS -----
If datasets are your filesystems you can mount and share, Zvols (ZFS Volume) are volumes that are exported as raw block devices just like your HDD/SSD in e.g. /dev/sda or /dev/nvme0
With ZFS, you can create these devices at will. We can format it, mount it, share it via iSCSI. We’re not using files or folders anymore, but entire (virtual) disks.
We create Zvols with zfs create -V 2TB tank/zvolname
Your Windows VM just sees a hard disk, not some network share. And although Windows formats the disk with NTFS, it is ultimately stored on our ZFS pool and we get all the features like snapshots, compression, self-healing, resizing, integrity, etc. Things you normally won’t get with NTFS.
Hardware that can boot from iSCSI can just use your Zvol as its boot drive. There are a lot of cool things you can do.
For home usage, sharing the Zvol via iSCSI is also an alternative way of providing storage outside of SMB or NFS. If you don’t want network folders but an entire disk, Zvols are for choice.
I have around 30 Zvols on my pool, most serve as VM disks and some are shared via iSCSI to other PCs. Some things just don’t work well via “network folder”, be it permissions, protocol overhead or OS/application not treating an SMB share like it would for a local drive.
We talked about dataset properties…Zvols have similar properties. But the most important difference is recordsize is replaced with volblocksize.
Determining the optimal blocksize is a science by itself. Here are some basic guidelines you should consider:
You ideally should match blocksize with the cluster size of the underlying filesystem that will be used.
Low values are better for random read and writes and larger values offer better throughput.
If you only have 128kb boxes and want to store a 1kb file, that’s a lot of wasted space. ZFS compresses rather well, but it’s still far from optimal. On the other hand, reading 256 blocks (4k volblocksize) to read a single 1MB file takes a lot of time. With 128k volblocksize, you only need to read 8.
I know that TrueNAS and Proxmox have default settings when creating Zvols and they aren’t bad as a general recommendation. Just keep in mind that you can’t change blocksize after creation. And digging into the low-level details of storage concepts and sector/cluster/block-sizes may provide you with more optimal blocksizes for your use case.
We can also create Zvols with thin-provisioning. This only uses the space on the ZFS pool that is actually being used instead of allocating the maximum value at creation.
We use the -s sparse option to do this: zfs create -s -V 2TB tank/zvolname
Keep in mind that Zvols can’t be used by multiple clients like a general SMB/NFS share.
To be continued…