WARNING: May contain signs of someone SLOWLY losing it:
You may want to have this open while reading the below to compare the assembly produced by different compilers:Compiler Explorer
Now to your regularly scheduled programming 
The initial exploration:
I’m now certain this is fundamental in the way GCC is detecting/producing code in general for this program type, and is not architecture dependent at all And/or I’m loosing my marbles(?) 

.
First, I ran with
-O3 -march=nehalem -mtune=native
-O3 -march=nehalem -mtune=native
-O3 -march=nehalem -mtune=native
I’m STILL getting nearly the same results as before, so it isn’t only an AVX thing, as the code didn’t generate any AVX instructions at all, as would be expected, instead generating SSE4_1 and 4_2 instructions.
Below the -march=nehalem -mtune=native I’ve posted march=nehalam only to re-confirm it isn’t related to weird tuning parameters for alder lake. See the “The Compiler results” Header for the data.
For the express reason of ridiculousness, I then tried -O3 -march=nehalem -fno-inline-small-functions -mavx512f -mavx512dq -mavx512ifma -mavx512cd -mavx512bw -mavx512vl -mavx512bf16 -mavx512vbmi -mavx512vbmi2 -mavx512vnni -mavx512bitalg -mavx512vpopcntdq -mavx512vp2intersect -mavx512fp16
This enabled in-lining, which was then disabled, limiting instructions to a max of sse4_2 and older, indicated to tune for nehalem, then allowed for usage of all of the most recent/advanced AVX512 instructions outside of those on Xeon PHI.
None of the 3 compiler families create any AVX512 code, which was slightly surprising, but I suspect may have to do with not having a cost function. I’ve never done such a weird config before, using instructions that only became available a month ago and telling the compiler to use them with a 13 year old architecture (sidebar: how is nehalem 13 years ago??? November 2008 )
Finally, some good news however:
The -fno-inline-small-functions reduced our assembly size slightly, but much more importantly, made it resemble the Clang and ICC/ICX assembly much more often.
for example, the pow() function is now:
GCC no *small* inline
pxor xmm1, xmm1
mov r15d, 1
lea ebp, [r12+4]
sub eax, r12d
cvtsi2sd xmm1, rax
mov rax, QWORD PTR .LC0[rip]
movq xmm0, rax
call pow
cvttsd2si rbx, xmm0
test rbx, rbx
je .L29
.L26:
mov edi, ebp
add r15, 1
call BottomUpTree
mov rdx, rax
mov rdi, rax
call ItemCheck
mov rdi, rdx
call DeleteTree
cmp rbx, r15
jge .L26
or
GCC no inline
.L27:
vxorpd xmm2, xmm2, xmm2
lea r12d, [r13+4]
mov eax, r14d
sub eax, r13d
vcvtusi2sd xmm1, xmm2, eax
mov rax, QWORD PTR .LC0[rip]
vmovq xmm0, rax
call pow
vcvttsd2si rbp, xmm0
test rbp, rbp
je .L23
mov ebx, 1
as opposed to
GCC normal
vxorpd xmm2, xmm2, xmm2
mov r15d, 1
lea ebp, [r12+4]
.LVL34:
sub eax, r12d
vcvtusi2sd xmm1, xmm2, eax
mov rax, QWORD PTR .LC0[rip]
vmovq xmm0, rax
call pow
Where as for the same no inline flag equivalents, clang and intel compilers output:
ICC no inline
.LN48:
vxorpd xmm0, xmm0, xmm0 #105.22
.mov r14d, 1 #109.14
vcvtusi2sd xmm0, xmm0, ebx #105.22
call exp2 #105.22
vcvttsd2si r12, xmm0 #105.22
test r12, r12 #109.26
jle ..B1.14 # Prob 10% #109.26
and
Clang no inline
.LBB4_1: # =>This Loop Header: Depth=1
mov eax, r12d
sub eax, r13d
vcvtusi2sd xmm0, xmm1, eax
call exp2@PLT
vcvttsd2si rbp, xmm0
Down The Rabbit hole
At Treedepth=26 results with all 12 compilers have been taking ~1h per sweep, but with results so consistent, it’s reasonable to cut out everything but the sub groups that perform differently:
GCC-12 for GCC
Clang 13 for Clang
and ICC for Intel
At this point, we can ignore legacy options, and pull out all the stops.
From now on the baseline compiler flag is -O3 -march=sapphirerapids -mno-amx-tile -mno-amx-int8 -mno-amx-bf16 Which I’ve found to be the most performant set of Pcore only compiler flags on Alder Lake with AVX512 enabled. (Gives a consistent 1 to 2 percent uplift in I/O for example)
Step one: make sure it isn’t weirdness with opt settings:
Results from the baseline above were: -O3 -march=sapphirerapids -mno-amx-tile -mno-amx-int8 -mno-amx-bf16
gcc 12 time taken is 413.502944
clang 13 time taken is 283.297773
intel icc time taken is 246.351291
Then -Ofast -march=sapphirerapids -mno-amx-tile -mno-amx-int8 -mno-amx-bf16 produced
gcc 12 time taken is 391.809389
clang 13 time taken is 281.122563
intel icc time taken is 244.576035
Moving to -O1 -march=sapphirerapids -mno-amx-tile -mno-amx-int8 -mno-amx-bf16 yielded
gcc 12 time taken is 414.762074
clang 13 time taken is 283.058792
intel icc time taken is 246.912347
Which is frankly ludicrous to me that O1 is within margin or error from Ofast and O3, meaning that -O0 was next in line.
Running with -O0 -march=sapphirerapids -mno-amx-tile -mno-amx-int8 -mno-amx-bf16
gcc 12 time taken is 483.183693
clang 13 time taken is 338.256443
intel icc time taken is 355.155574
Now, the results above are slower, but if you look at the performance delta, we’re still in the ~40-50% performance delta range.
I think I need to put this down for a little bit and mull it over.
Path forward
At this point It’s fair to say that this is fundamental to GCC, regardless of version.
Is it a weird edge case? Without a doubt. Simultaneously, for such simple code (it’s just a binary tree after all) it’s very strange to see this sort of behavior.
Next step is to modify the data structures and watch how the compilers changes in terms of performance relative to each other.
Side bar
Slightly concerning is the Clang results having gotten worse after clang 11, and that Clang 13 was stagnant with Clang 12
The Compiler results:
Lots of data:
-O3 -march=nehalem -mtune=native
Running this script can take a long time, but can provide interesting results for your system.
Currently this version tests the MAXIMUM optimizations levels of:
GCC 7 8 9 10 11 12
Clang 11 12 13
Intel ICPX/ICPC
This MAY take a LONG time, I suggest going to get a cup of coffee/tea etc.
cleaning up
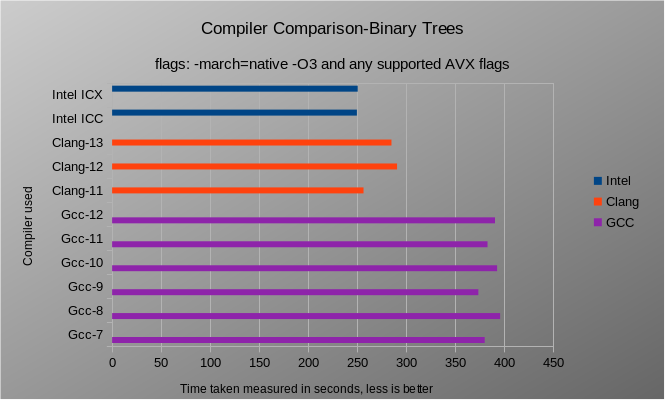
gcc numbers 7 8 9 10 11 12
time taken is 378.633921
time taken is 388.759841
time taken is 398.505542
time taken is 396.185356
time taken is 389.246530
time taken is 383.175040
clang numbers 11 12 13
time taken is 247.940912
time taken is 281.304001
time taken is 281.172159
intel numbers icc icx
time taken is 247.721858
time taken is 247.919625
Above tests were completed with Tree size of 26
You can modify this number via enviroment variable. Remember that larger trees take up more system memory
If no number is printed or you got a segfault, try setting $TREEDEPTH. A low number such as 16 is a good starting point
Also make sure you set your AVX flags correctly. To print the AVX(1, 2 or 512) instructions supported by your system, use the provided "detect_avx.sh" script
You can then use "CFLAGS=`./detect_avx.sh`" to add the flags directly. Any unsupported flags will be caught (and complained about) by your compiler
Different compilers support different levels of AVX. For the sake of convenience this script is setup to use 3 different levels of flags, deliniated at the gcc-10>=, gcc 8-9 and gcc-7<=
if set, they will now be printed:
-O3 -march=nehalem -mtune=native
-O3 -march=nehalem -mtune=native
-O3 -march=nehalem -mtune=native
-O3 -march=nehalem
Welcome to the quick and dirty compiler profiler!
Running this script can take a long time, but can provide interesting results for your system.
Currently this version tests the MAXIMUM optimizations levels of:
GCC 7 8 9 10 11 12
Clang 11 12 13
Intel ICPX/ICPC
This MAY take a LONG time, I suggest going to get a cup of coffee/tea etc.
cleaning up
gcc numbers 7 8 9 10 11 12
time taken is 377.909626
time taken is 402.613440
time taken is 380.637230
time taken is 381.880265
time taken is 394.721852
time taken is 384.849122
clang numbers 11 12 13
time taken is 247.223285
time taken is 281.160776
time taken is 281.889140
intel numbers icc icx
time taken is 251.820126
time taken is 250.232138
Above tests were completed with Tree size of 26
You can modify this number via enviroment variable. Remember that larger trees take up more system memory
If no number is printed or you got a segfault, try setting $TREEDEPTH. A low number such as 16 is a good starting point
Also make sure you set your AVX flags correctly. To print the AVX(1, 2 or 512) instructions supported by your system, use the provided "detect_avx.sh" script
You can then use "CFLAGS=`./detect_avx.sh`" to add the flags directly. Any unsupported flags will be caught (and complained about) by your compiler
Different compilers support different levels of AVX. For the sake of convenience this script is setup to use 3 different levels of flags, deliniated at the gcc-10>=, gcc 8-9 and gcc-7<=
if set, they will now be printed:
-O3 -march=nehalem
-O3 -march=nehalem
-O3 -march=nehalem
export CFLAGS=’-O3 -march=nehalem -fno-inline-small-functions -mavx512f -mavx512dq -mavx512ifma -mavx512cd -mavx512bw -mavx512vl -mavx512bf16 -mavx512vbmi -mavx512vbmi2 -mavx512vnni -mavx512bitalg -mavx512vpopcntdq -mavx512vp2intersect -mavx512fp16’
Welcome to the quick and dirty compiler profiler!
Running this script can take a long time, but can provide interesting results for your system.
Currently this version tests the MAXIMUM optimizations levels of:
GCC 7 8 9 10 11 12
Clang 11 12 13
Intel ICPX/ICPC
This MAY take a LONG time, I suggest going to get a cup of coffee/tea etc.
cleaning up
gcc numbers 7 8 9 10 11 12
time taken is 387.134731
time taken is 402.971395
time taken is 399.359678
time taken is 394.730115
./quick_benchmark.sh: line 31: ./cpu_gcc11_fast_opt: No such file or directory
time taken is 406.477327
clang numbers 11 12 13
time taken is 248.450385
time taken is 282.136717
time taken is 281.579489
intel numbers icc icx
time taken is 253.399868
time taken is 253.133112
Above tests were completed with Tree size of 26
You can modify this number via enviroment variable. Remember that larger trees take up more system memory
If no number is printed or you got a segfault, try setting $TREEDEPTH. A low number such as 16 is a good starting point
Also make sure you set your AVX flags correctly. To print the AVX(1, 2 or 512) instructions supported by your system, use the provided "detect_avx.sh" script
You can then use "CFLAGS=`./detect_avx.sh`" to add the flags directly. Any unsupported flags will be caught (and complained about) by your compiler
Different compilers support different levels of AVX. For the sake of convenience this script is setup to use 3 different levels of flags, deliniated at the gcc-10>=, gcc 8-9 and gcc-7<=
if set, they will now be printed:
-O3 -march=nehalem -fno-inline-small-functions -mavx512f -mavx512dq -mavx512ifma -mavx512cd -mavx512bw -mavx512vl -mavx512bf16 -mavx512vbmi -mavx512vbmi2 -mavx512vnni -mavx512bitalg -mavx512vpopcntdq -mavx512vp2intersect -mavx512fp16
-O3 -march=nehalem
-O3 -march=nehalem
GCC 11 fails due to lack of support for some AVX flags. Running it with AVX512FP16 removed yields a time of
export TREEDEPTH=26
gcc-11 binarytrees.c -o tmp $CFLAGS -lm
./tmp $TREEDEPTH
time taken is 412.476479
echo $CFLAGS
-O3 -march=nehalem -fno-inline-small-functions -mavx512f -mavx512dq -mavx512ifma -mavx512cd -mavx512bw -mavx512vl -mavx512vbmi -mavx512vbmi2 -mavx512vnni -mavx512bitalg -mavx512vpopcntdq -mavx512vp2intersect
 Using 8 different XMM registers, many of which seem to be used to fetch memory in more continuous chuncks(?) but also then casting down so older SIMD for other operations, moving them back and fourth within each other etc.
Using 8 different XMM registers, many of which seem to be used to fetch memory in more continuous chuncks(?) but also then casting down so older SIMD for other operations, moving them back and fourth within each other etc.