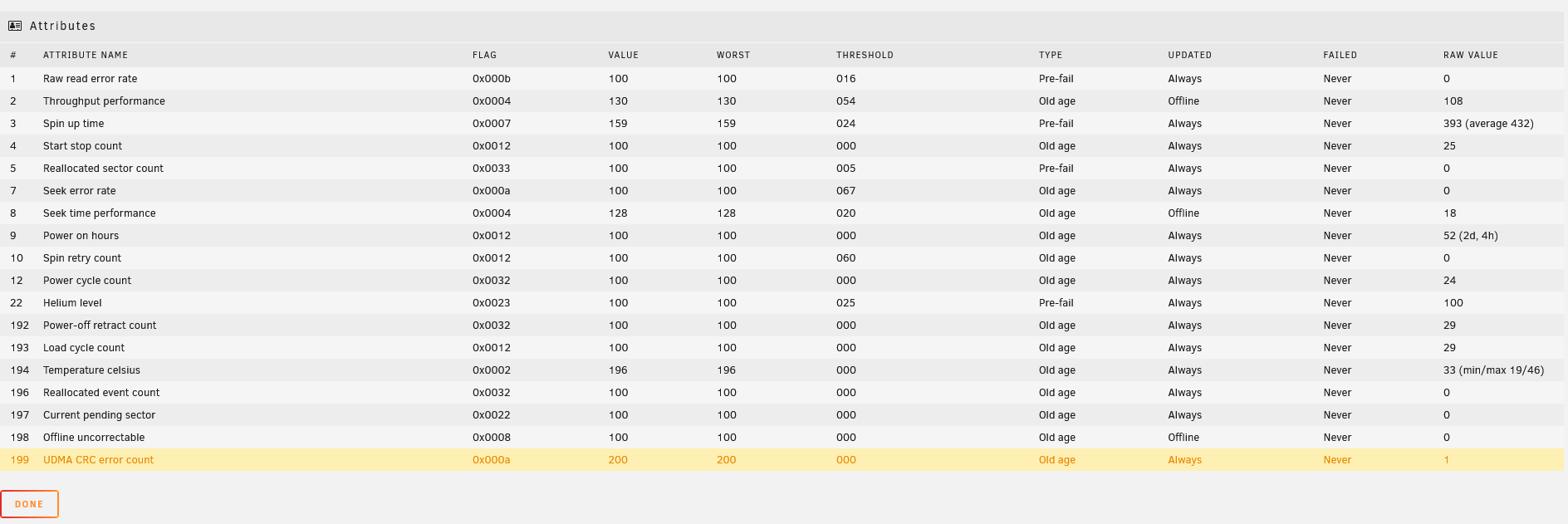
Unraid device sdn SMART health [199]: 27-11-2019 06:40
Warning [TOWER] - udma crc error count is 1
WDC_WD80EMAZ-00W
Warning on 1 the 4 drives inside my new case.
Currently trying out unraid for the first time and while ussing
the binhex-preclear tool.
I got this warning on 1 of those 4 internal drives.
A while ago i order these four, 8 TB drives in WD elements enclosures from amazon.
Upon delivery i did do extended smart checks on them wenn connected to
a windows 10 pc over usb, no faults where found back then.
Months later i ‘‘shucked’’ them (remove from an external enclosure, so they might be used internally).
Two didn’t work with SATA cables wenn connected to the unraid server, the other two did.
(i beleave this is a third pin reset issue)
And 1 of those drives that didn’t work with SATA is the one with the error.
What am i supposed to do with that:‘udma crc error count is 1’ warning ?
Now i have googled this obviously but most advice amounts to changing the SATA cable and that obviously doesn’t apply here.
And i also read that another option is that it represents a bad sector.
But smart reports:
Normally not, although without an exact quote or source I have no way of knowing what exactly they said.
Lets break the name down. UDMA is short for ultra direct memory access. It basicly means the protocol between the motherboard and the drive. CRC is cyclic redundancy check, which is a checksum that can detect if data is corrupted. Error is something failing in this case. Combine those and then UDMA CRC error means that data got corrupted between the drive and the motherboard, one count for each instance over the life of the drive.
So basically, it is something to ignore, since it is a one time error, caused by any number of things. If it keeps going up, then something is bad, but a single-digit count is nothing to worry about.
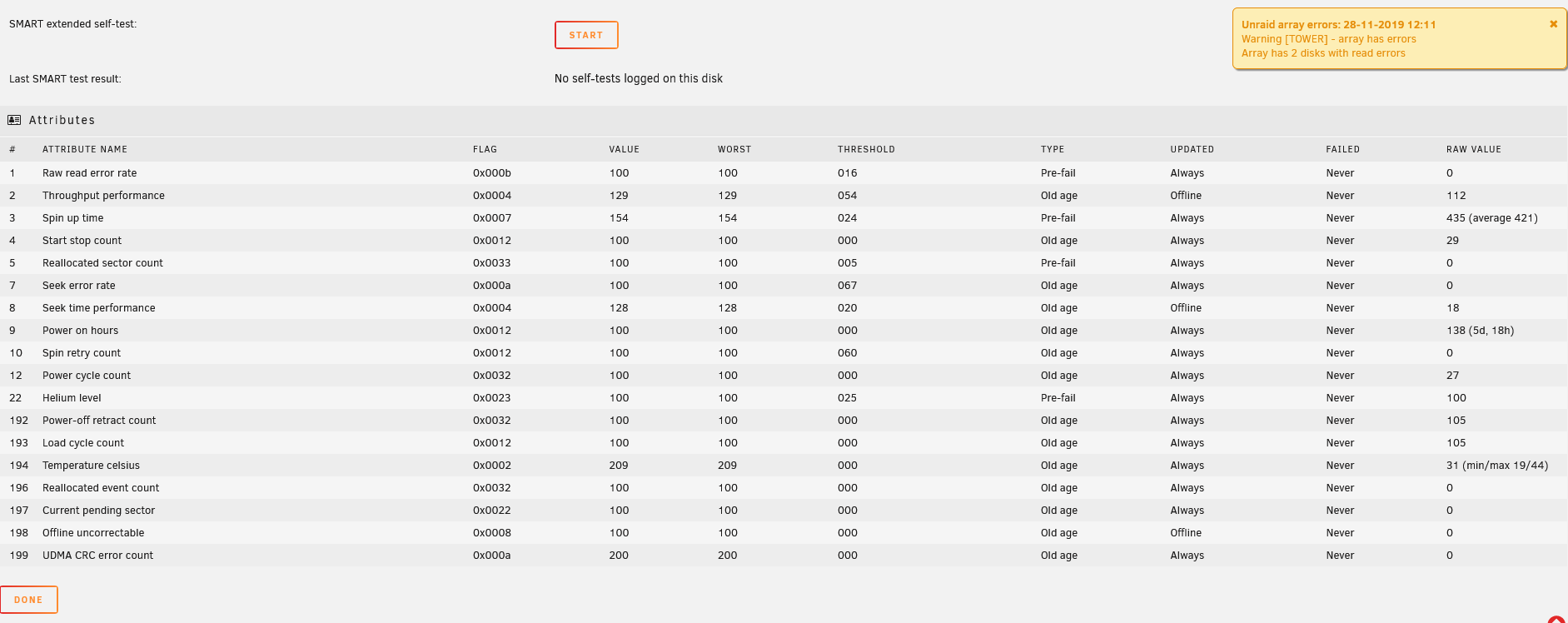
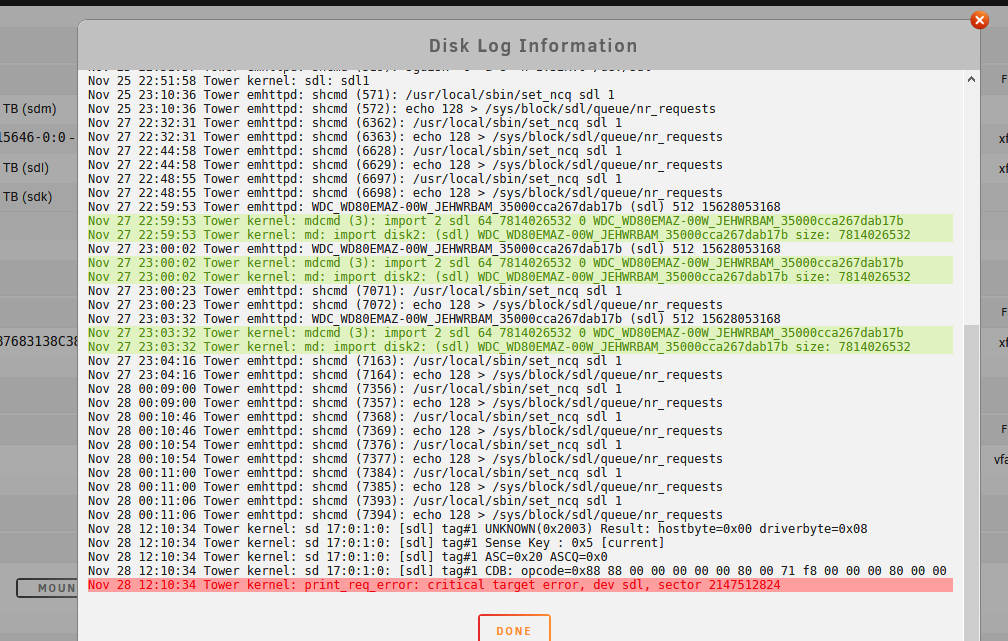
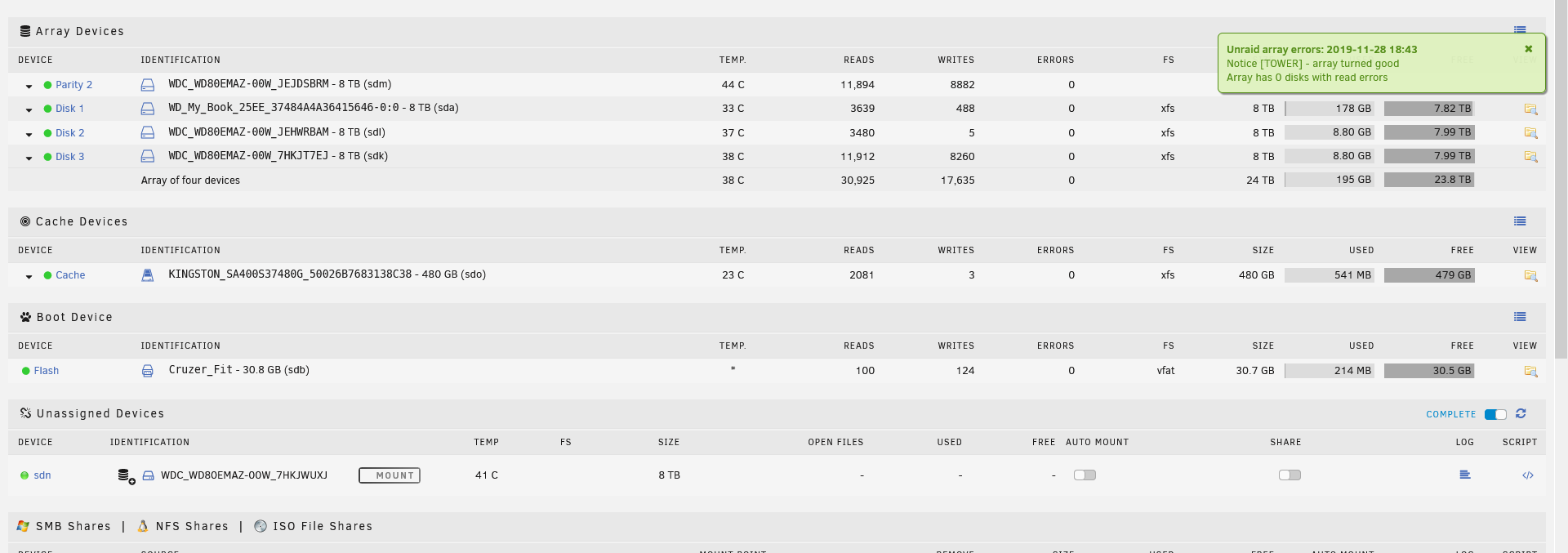
Unraid array errors: 28-11-2019 12:11
Warning [TOWER] - array has errors
Array has 2 disks with read errors
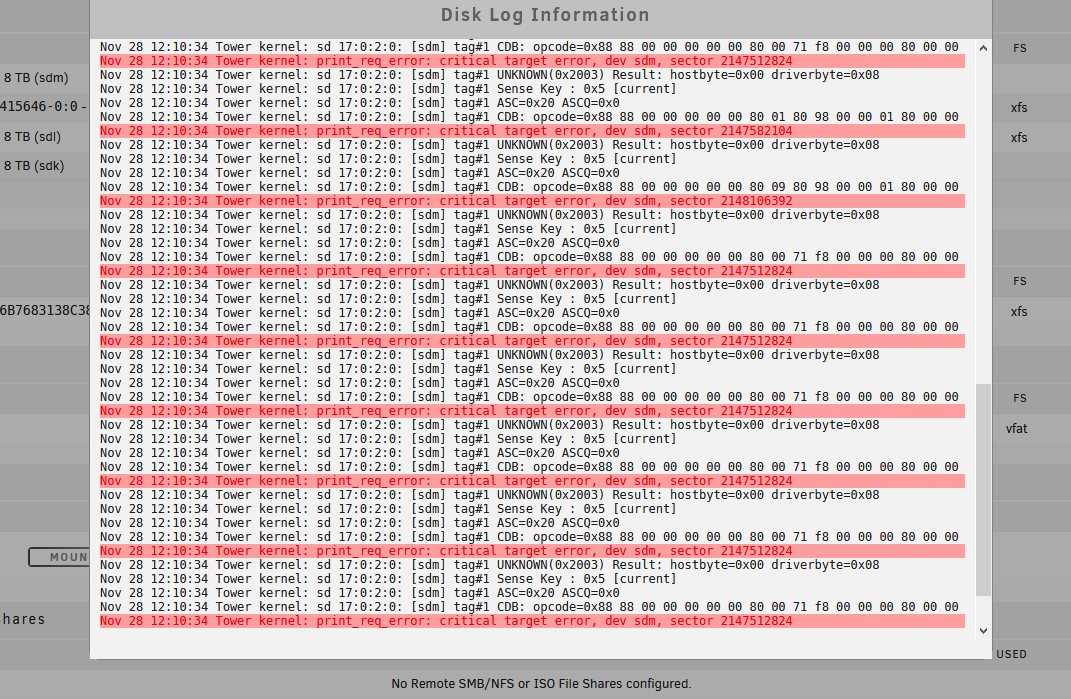
My Unraid GUI disc is reporting:
Errors: 8,947,568 on my parity disc.
None of the smart results on my drives are reporting anything bad or new apart from the 1 udma error.
The parity drive, is different from the one with the single udma error that drive is still unassigned.
This is the smart on that parity drive (sdm) :
It seems like such a coincidence that 3 drive are having issues. Shouldn’t i try and rule out the other components? I also don’t understand why the SMART read out is still 100% fine.
My first instinct would be to verify whether the ram is good. Especially if not using ECC memory (board supports both ECC and non-ECC according to the link).
Thanks for the suggestion, i am using a single 16 GB ECC ram stick.
I have also check in the UEFI if ECC was on. It is!
My second stick of ram still needs to be delivered.
Yesterday this happend
I moved all of my drives into the other backplane that my case has. Meaning that they are now connected to a different SAS cable, backplane and port on the HBA. I also and moved the HBA to another pcie slot.
And…
I still don’t know what is going on but, this is beter then having close to 8,9 million errors.
It should be noted that in the old configuration it generated all those errors around 12:10 am and wen i was made aware of the problem it didn’t generate more errors. Maybe a connector got lose and nothing is broken ? (i’m hoping its this scenario )
And things are yet more complicated…
So the 2 drives i have out of the 4 i bought together have an issue. All of these come from external enclosures. These 2 didn’t seem to work with a SATA cable.
(I didn’t think much of it as i knew about the third pin reset issue with some ''chucked drive’s.)
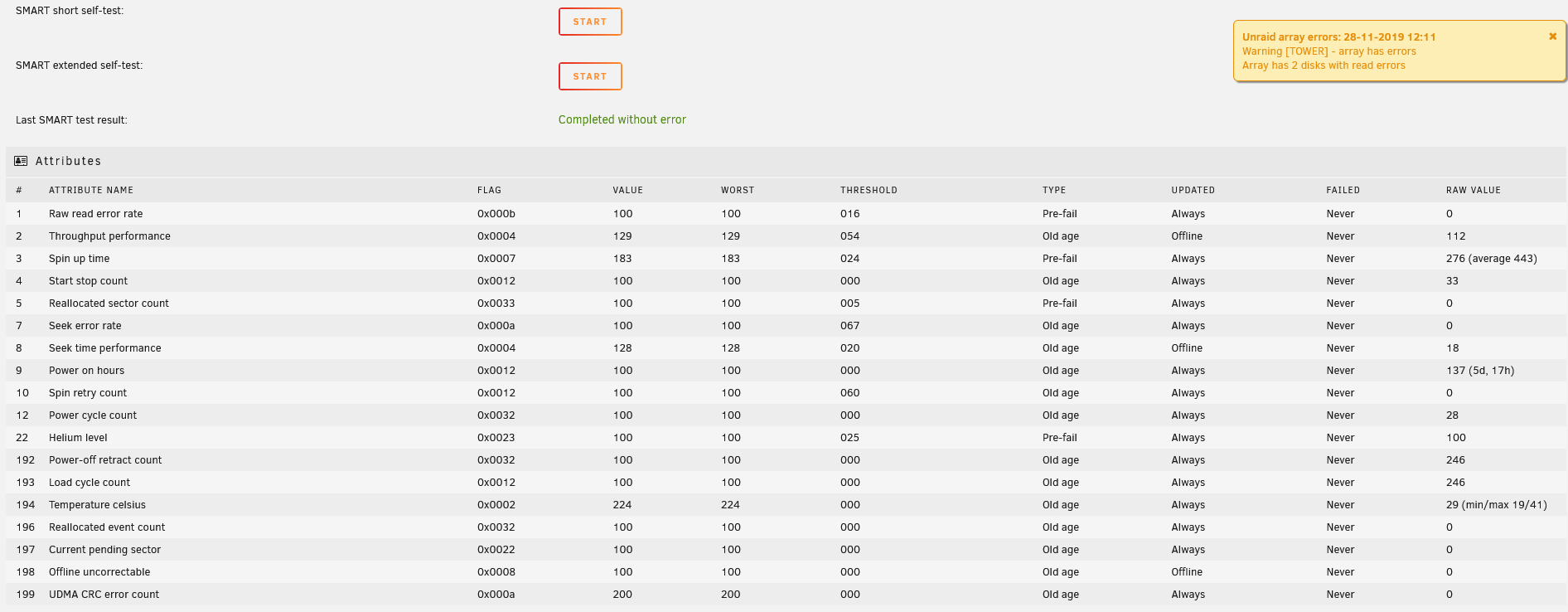
Both have this issue:
SMART Status not supported: Incomplete response, ATA output registers missing
SMART overall-health self-assessment test result: PASSED
Warning: This result is based on an Attribute check.
Have found some info on this online, copied and pasted some random commands by strangers into the terminal
Now it did give a warning, wen i did the pre-clear on these 2 disc.
Which i am now betting referred to this issue. Kinda glossed over that at the time.
One of these disc refuses to mount.
Unmountable: Unsupported partition layout
Even though it has just been formatted by Unraid and had been pre-cleared before that.
Edit: Doing a third format fixed the mounting issue.
Still trying to figure it out, in way over my head!
Luckily there is nothing stored on this system apart from test files.
But things are getting a bit frustrating.
All the responses to this thread have been much appreciated though !
Hi there! From my experience the CRC errors can be caused by the cables, connections/ports, controllers, or even RAM. For example, if your RAM is bad then it can corrupt the data being written to and from the controller.
However, most of the time it’s just a loose connection or cable that’s gone bad. I’ve seen SATA cables get super brittle from too much heat over time. The ends cracked and the cable wouldn’t stay on the drives in the case. Their office was so hot and the case didn’t have sufficient cooling to counter it. The end result was plastic/rubber had hardened and cracked. Without a snug, tight fit the data will most definitely get corrupted.
If you’re using a backplane then there’s still usually a cable that runs from the backplane to the motherboard or add-on controller/RAID card. SAS cables are still cables.
Some people think it’s from slower speed cables. In networking, what happens when you connect say a CAT5 cable on a gigabit router? It’ll just negotiate a slower connection speed (100mb/s instead of 1,000mb/s), not corrupt the data. Now poor quality or loose connection is a different story.
Like the said, the best way to eliminate the causes is to test using different ports and cables then transfer some data from another source. If your sample size is large enough then you’ll likely see the number of errors increase (S.M.A.R.T measurement will go down from 100%). If it doesn’t change then you found the issue. If you’re not sure then will just have to monitor it going forward to see if it changes.


 )
)