So I’ve recently been smashing my media library on my lounge room TV which is currently kitted out with a 2.1 Stereo setup.
One thing I’ve noticed is that any films that have a mix of dialogue and action sequences have the dialogue whisper quiet and the action sequences deafeningly loud. Although I appreciate the fine art of mixing the audio to be realistic, it is, from a practical movie going experience, a minor inconvenience. I’m not 100% sure, but it might have something to do with smooshing a 5.1 mix into the 2.1 stereo speaker system from the source file.
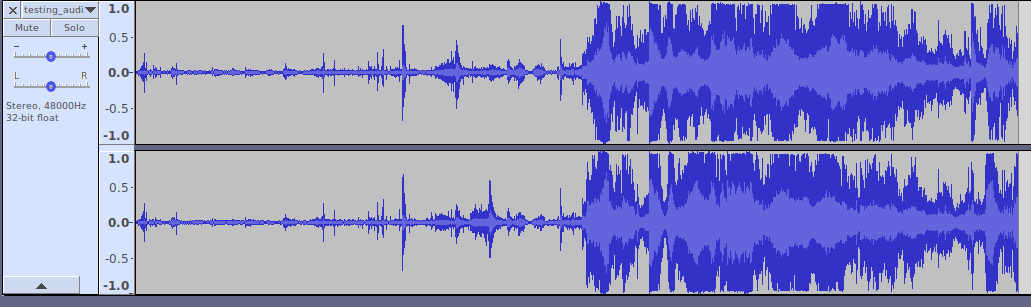
For example, I took an audio sample from one of my films and cut it to be an extreme example (a hard cut from dialogue straight into guns and explosions!). See below:
From my very feeble and basic understanding (plz forgive me audio engineers and mixers) I was looking into audio normalisation with the ffmpeg package but I may have been barking up the wrong tree.
Essentially, what I’d like to do is have a very stable audio signal throughout the entire film so I’m not constantly changing the volume - I think the equivalent would be from Adobe; specifically, the dynamics processing filters for this kind of task.
I was wondering if there was a practical way of applying this in a batch script or programmatically so I can just dump it on my media folder and let the magic happen.
So in essence, there are two main questions:
Is there a specific method I should be looking into for this task?
Is there a viable way of doing any of this?
If this is dumb, let me know as I may have a few hacky ways to work around this in Python - but, I’m open to more legitimate suggestions from smarter minds than my own.
Depending on playback device you might be able to use a nightmode that does exactly what you want. But I think the main issue is the stereo nature of your setup trying to output multichannel sound.
So the playback device at the moment is an Apple TV that just streams my local media files from my PC. Unfortunately, it misses out on the subtleties and nuance of mix control so I don’t think there’s a way of changing the 5.1 to 2.1 settings from the playback device, unfortunately.
This does raise an idea of simply changing the source file on my PC to have a 2.1 mix by default - I will look into this!
It will copy the original audio into the new video file so you still have both. Then you can experiment with some compand options.
Although with with multiple audio tracks and some mixing involved you might have to write a proper script to handle a video file.
You could find all video files in a folder with find and file --mime-type.
I have some script that does something similar
# Find all files of mimetype video with name_pattern
find . -type f -name "$name_pattern" \
-exec sh -c '[ $(file -b --mime-type "{}" | cut -f 1 -d /) = video ] && echo "{}"' \; \
| while read vid
do
# Loop body
# ffmpeg something
done
You could probably cut down that huge find one-liner but I was determined to do it without a loop (at first).
Edit:
You could also construct the ffmpeg command for each file, write it to a temporary file and execute that with parallel. Should be way faster.
Edit 2:
IMPORTANT
If you use ffmpeg in such a while read loop you have to pass the -nostdin option to ffmpeg. Otherwise ffmpeg will read keep reading a single character from stdin, thus screwing up your filenames.
This one cost me some hours a while ago.
Quick update since I finally decided to sit myself down and commit to a quick session of scripting and learning how the parameters worked for this package.
In short, thanks very much @zxip for pointing me towards the compand filter as this pretty much does exactly what I want it to do (at face value at this stage, I have yet to test it on the main system but the waveforms are looking much better!) .
So for example to save some for when I inevitably forget how it works, the ffmpeg parsing pretty much looked like this:
So essentially, -i is the input file as shown in the .mp4 file above. This is then parsed through the -filter:a which is essentially saying, ‘the filter stream I want you to use is the audio one as denoted by a’. Then all the fancy parameters for the compand filter followed by a destination output file; in this case simply another .mp4 file.
I’m just using the default suggested parameters as proposed by the documentation i.e:
Now, for the fun bit. Here’s some comparisons for before and after compression to the audio streams.
As you can see, a big difference on the whisper quiet audio with fattening of the initial wave forms. Furthermore, there seems to be some more aggressive compression during the action sequences thus reducing the peaks that might make your speakers do back flips.
Anyway, I have yet to go any further with this but it is super fun so thanks for the reply!