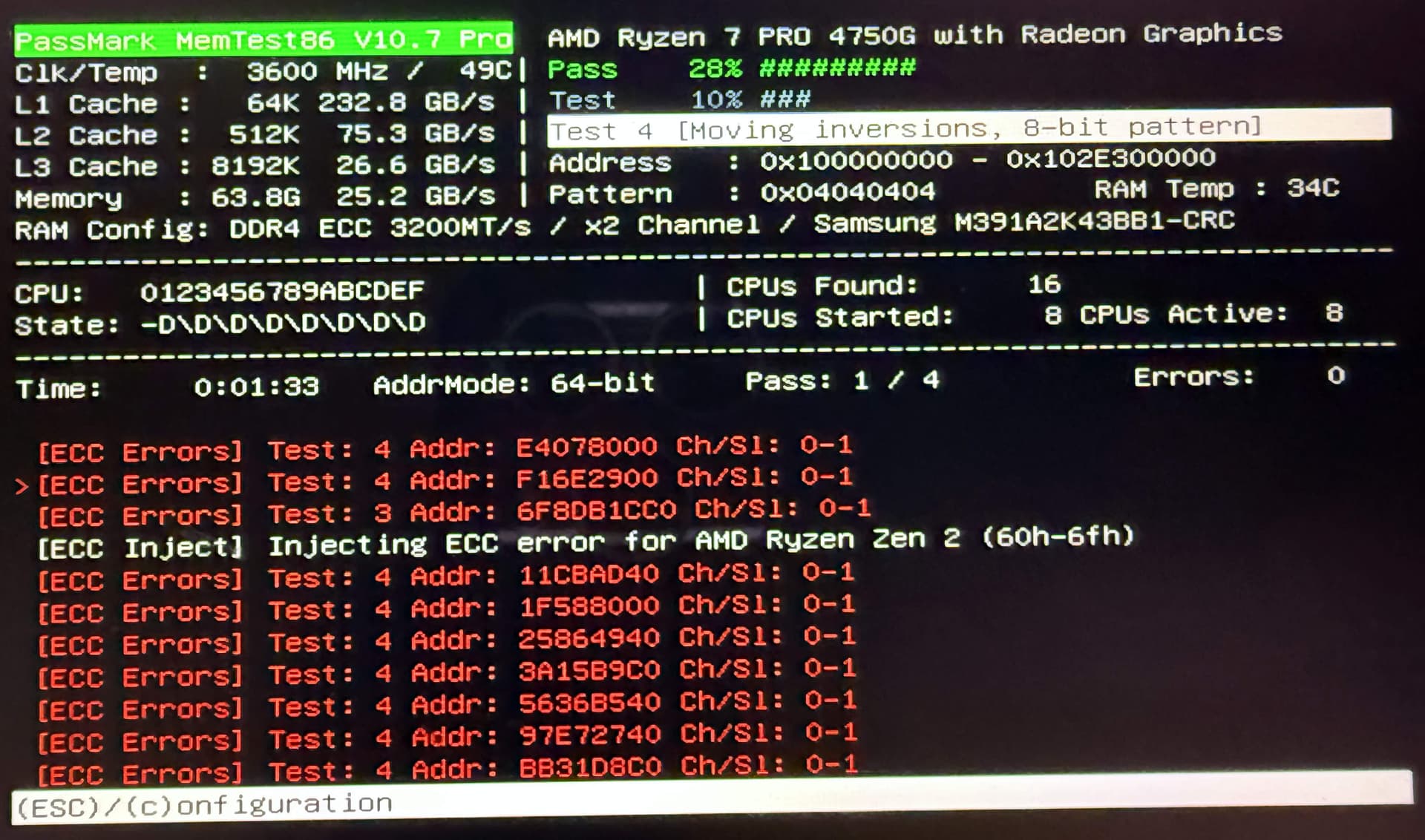
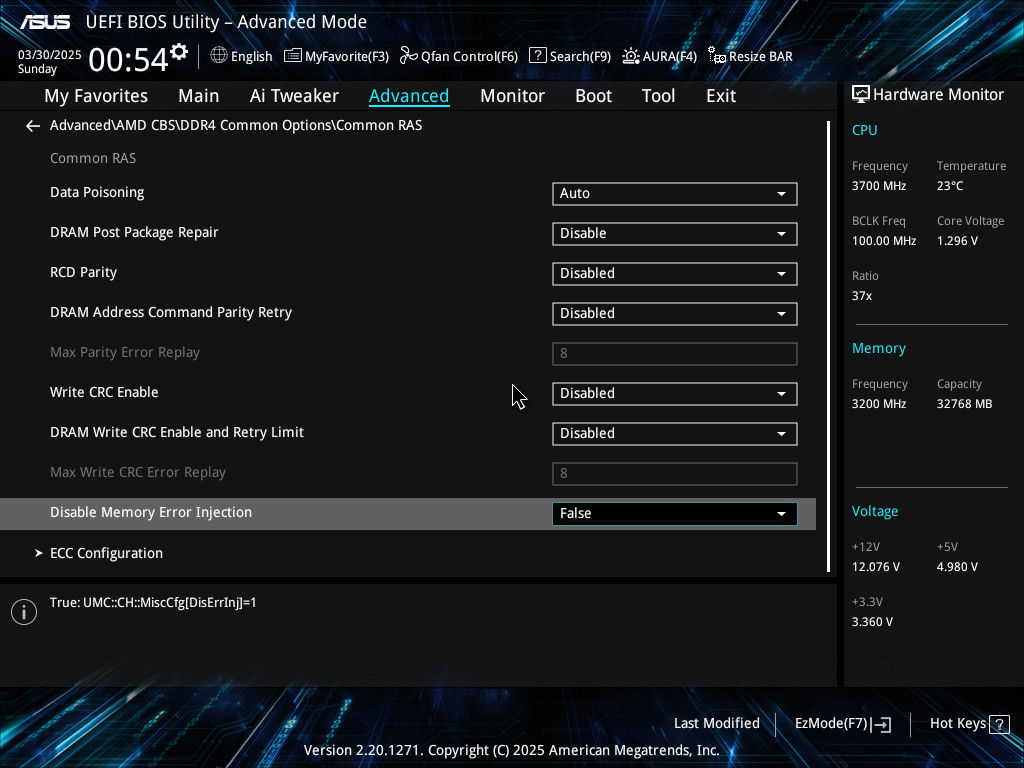
Preamble
Writing up the validation exercise I did on the following system:
- CPU: Ryzen 5 5600X
- Motherboard: Gigabyte B550 Aorus Pro AC
- Firmware F18d (2024 Sept, AGESA 1.2.0.CC)
- RAM: 4x16GB 2133 MT/s CL15 ECC UDIMMs pulled from another system
- OS: MemTest86 V10.6 Free & Debian Bookworm (12.10)
- The Debian OS install was sacrificial. Don’t do this testing on a system with data you care about.
I was trying to validate that ECC is both working and errors are reported in Debian. I installed Debian along with the edac-utils and rasdaemon apt packages. It’s possible that only the former was needed. I also installed the memtester apt package to perform stress testing within Debian.
Validation
Running ras-mc-ctl --status will give ras-mc-ctl: drivers not loaded. on a system without ECC RAM (or without the drivers running…try a reboot). On a system with ECC RAM, the output should be ras-mc-ctl: drivers are loaded.. Running ras-mc-ctl --error-count outputs all the recorded errors (presumably since a reboot):
Label CE UE
mc#0csrow#2channel#1 0 0
mc#0csrow#2channel#0 0 0
mc#0csrow#1channel#0 0 0
mc#0csrow#0channel#0 0 0
mc#0csrow#1channel#1 0 0
mc#0csrow#0channel#1 0 0
mc#0csrow#3channel#1 0 0
mc#0csrow#3channel#0 0 0
Once you get here, the system appears to have working ECC. To test it, you have some options:
- Physically disturb the RAM (e.g. overheat it, short data pins to GND, etc). Too bold for me.
- Inject errors via software. Not all platforms support this, and mine doesn’t appear to Ref1, Ref2
- Overclock the RAM to the point of instability. Consumer motherboards tend to allow that.
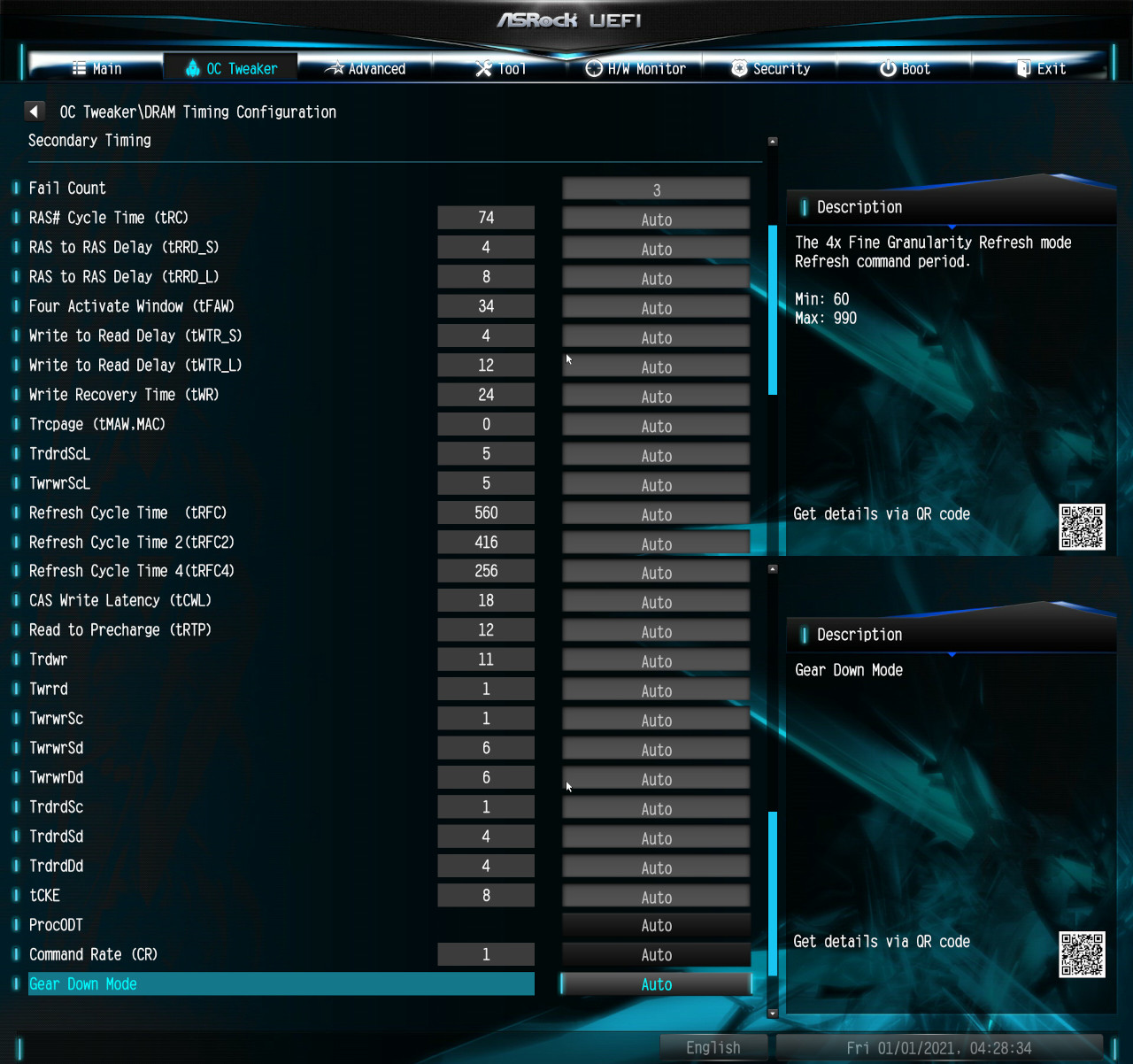
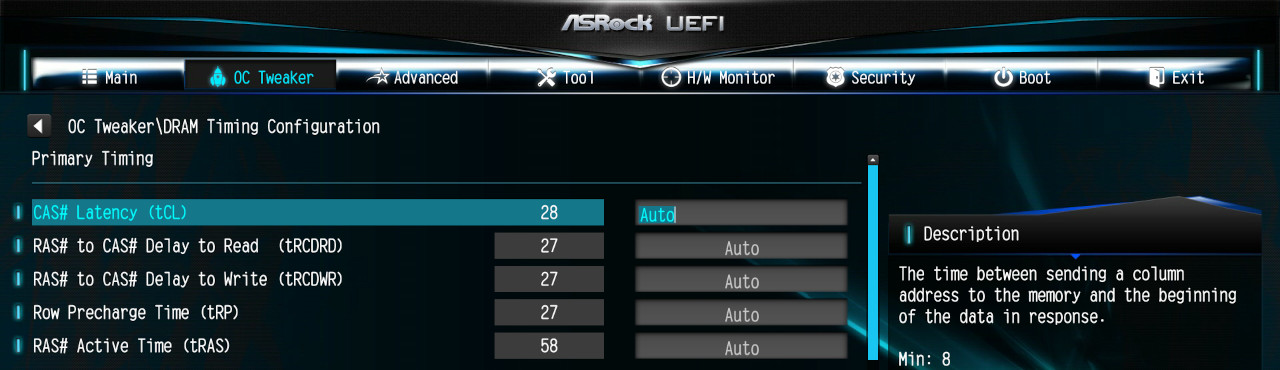
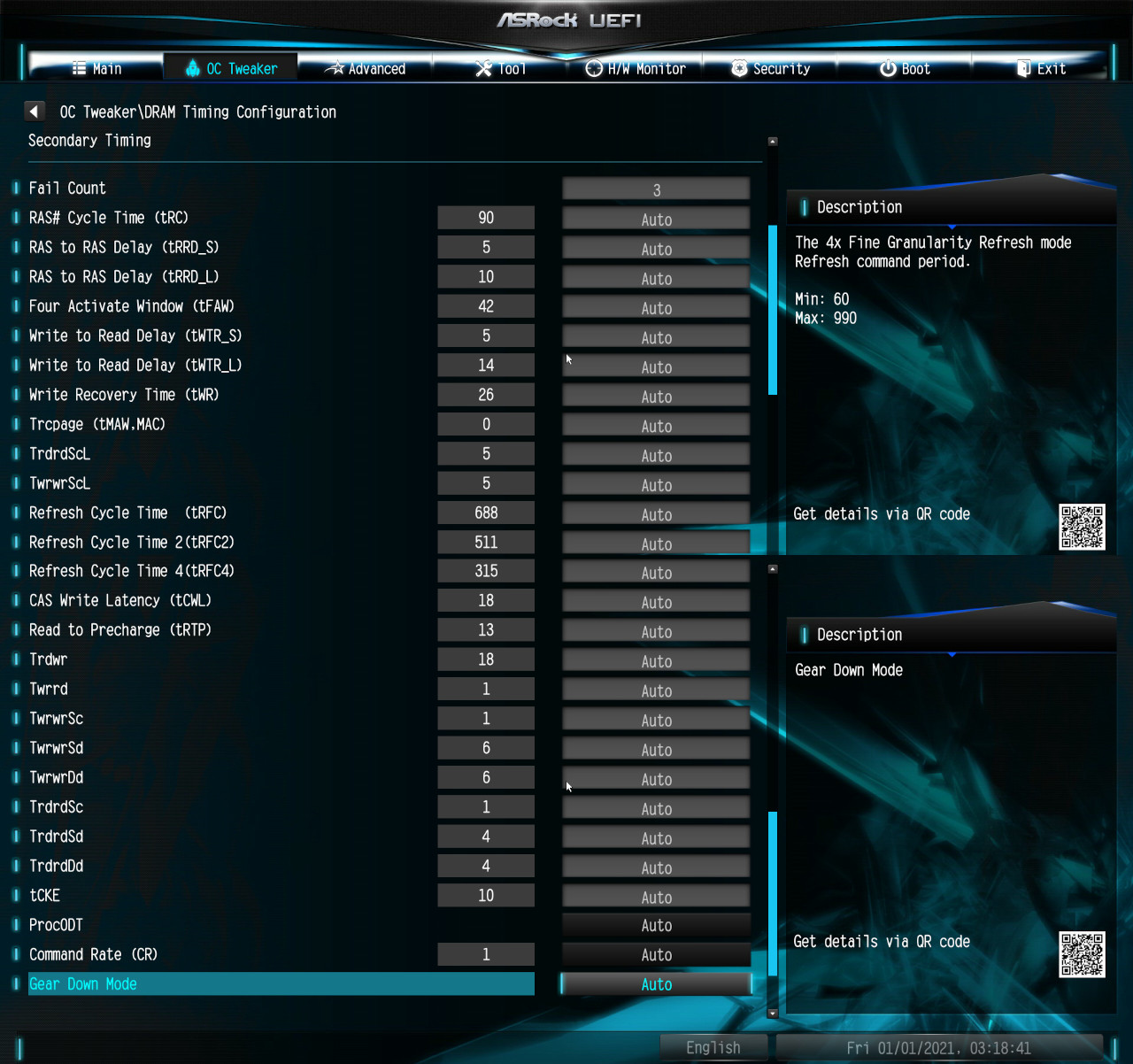
I went with the last option. I fixed the following settings:
- RAM Command Rate: 1T
- RAM Gear Down Mode: Disabled
- RAM Power Down: Disabled
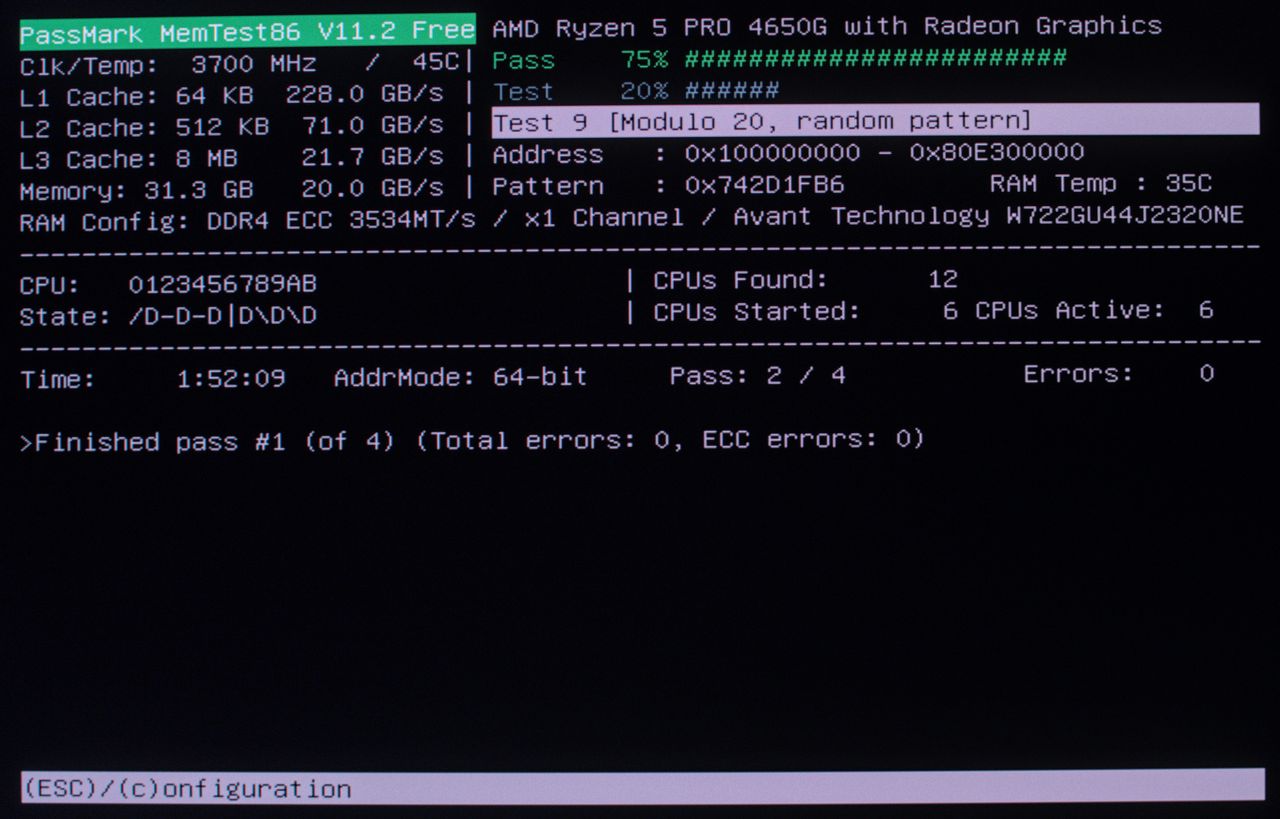
From there I iteratively lowered the CAS Latency from Auto (15) to 12, and subsequently to 10. 10 completed POST but gives ECC errors in MemTest86 within 15 seconds of stress testing:
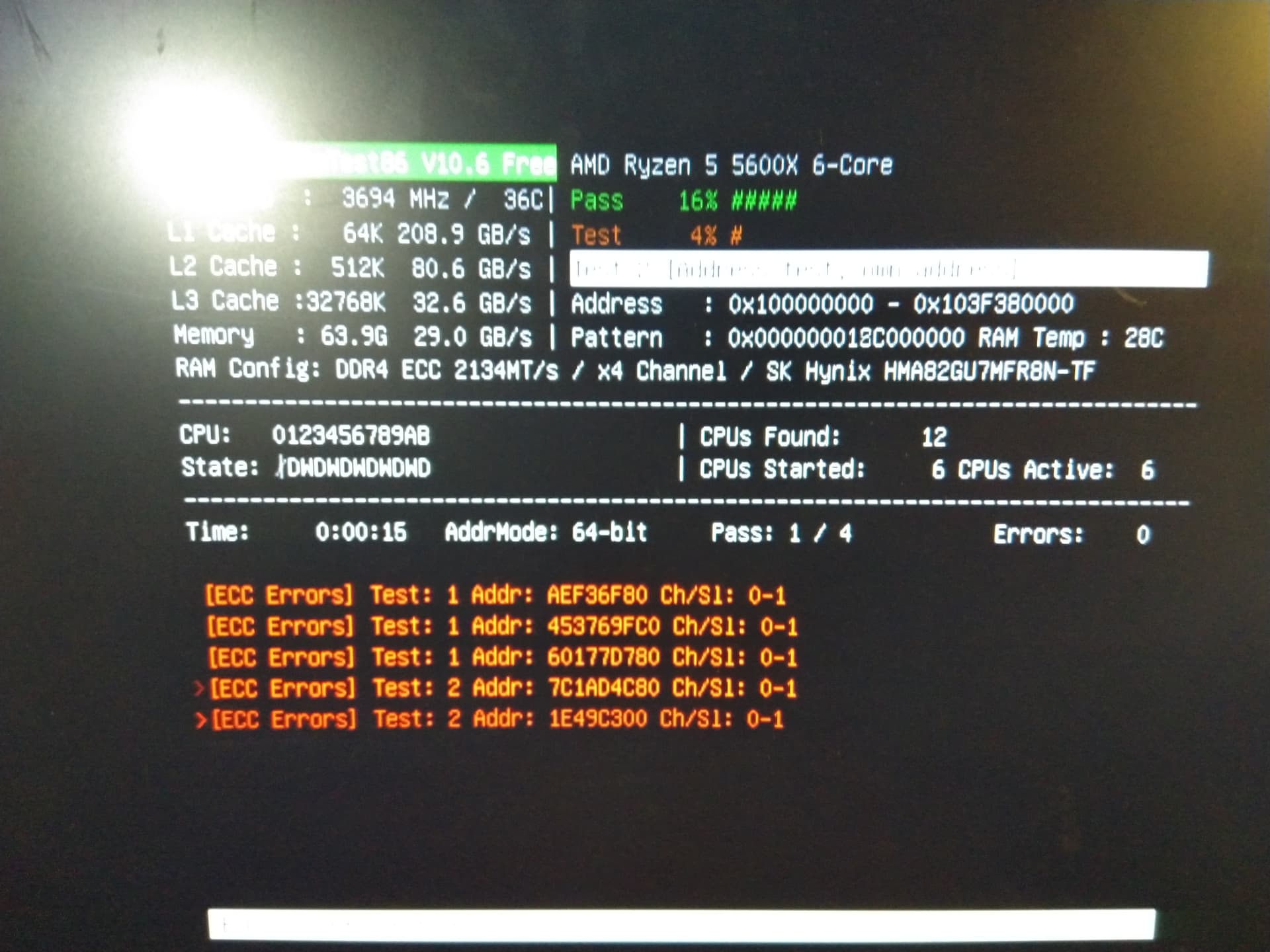
The errors in orange shown above are different from those that MemTest86 spits out when an uncorrected error is detected. This suggests that at least 1-bit (i.e. correctable) errors are both corrected and reported. After this I booted into Debian to reproduce the results. Running memtester 50000 to test 50,000 MB of RAM pretty quickly led to kernel messages indicating it detected something:
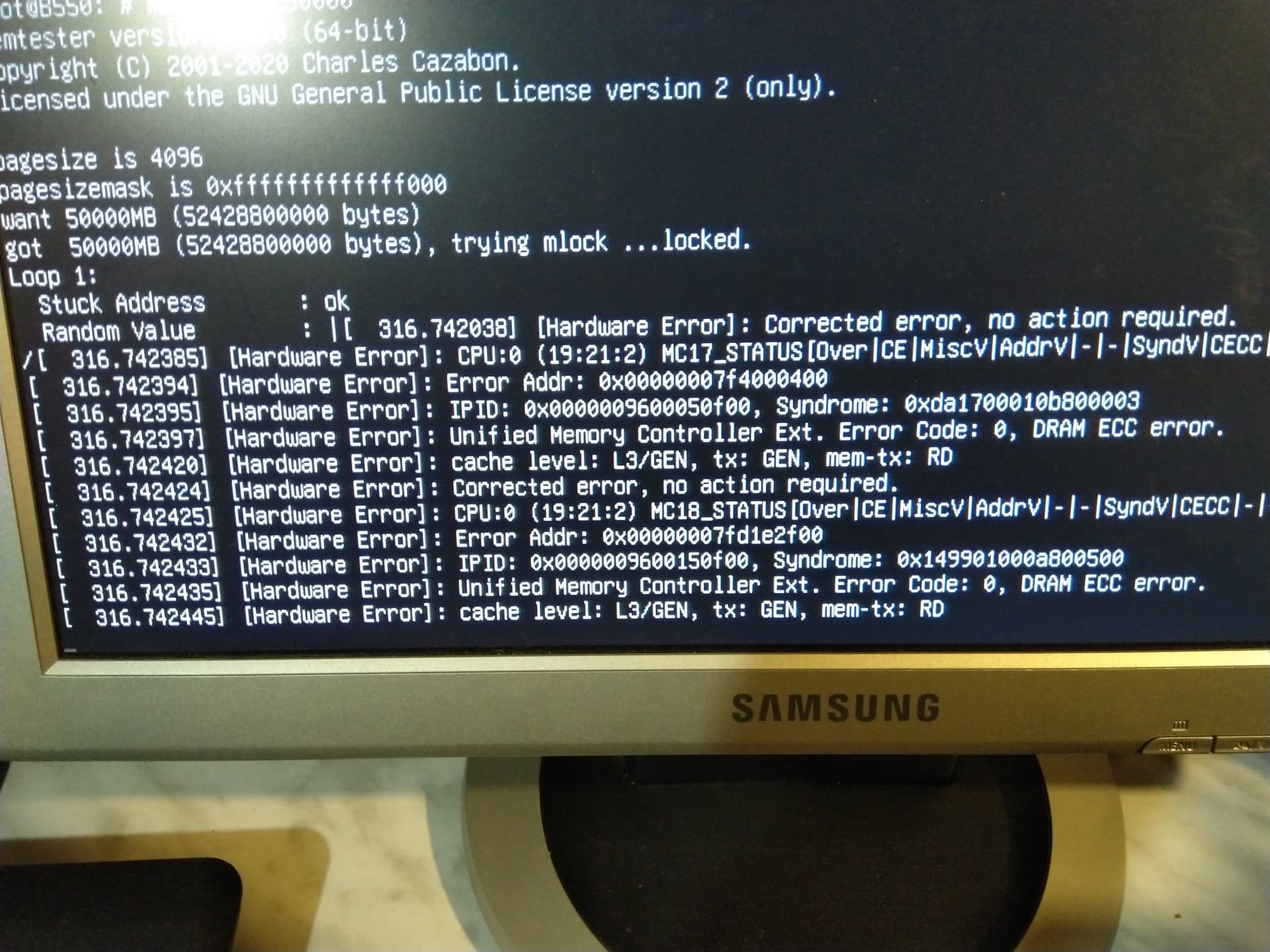
Sure enough, after running the memory test a few times and running ras-mc-ctl --error-count I observed both nonzero correctable (i.e. 1-bit) and uncorrectable (i.e. 2-bit) errors:
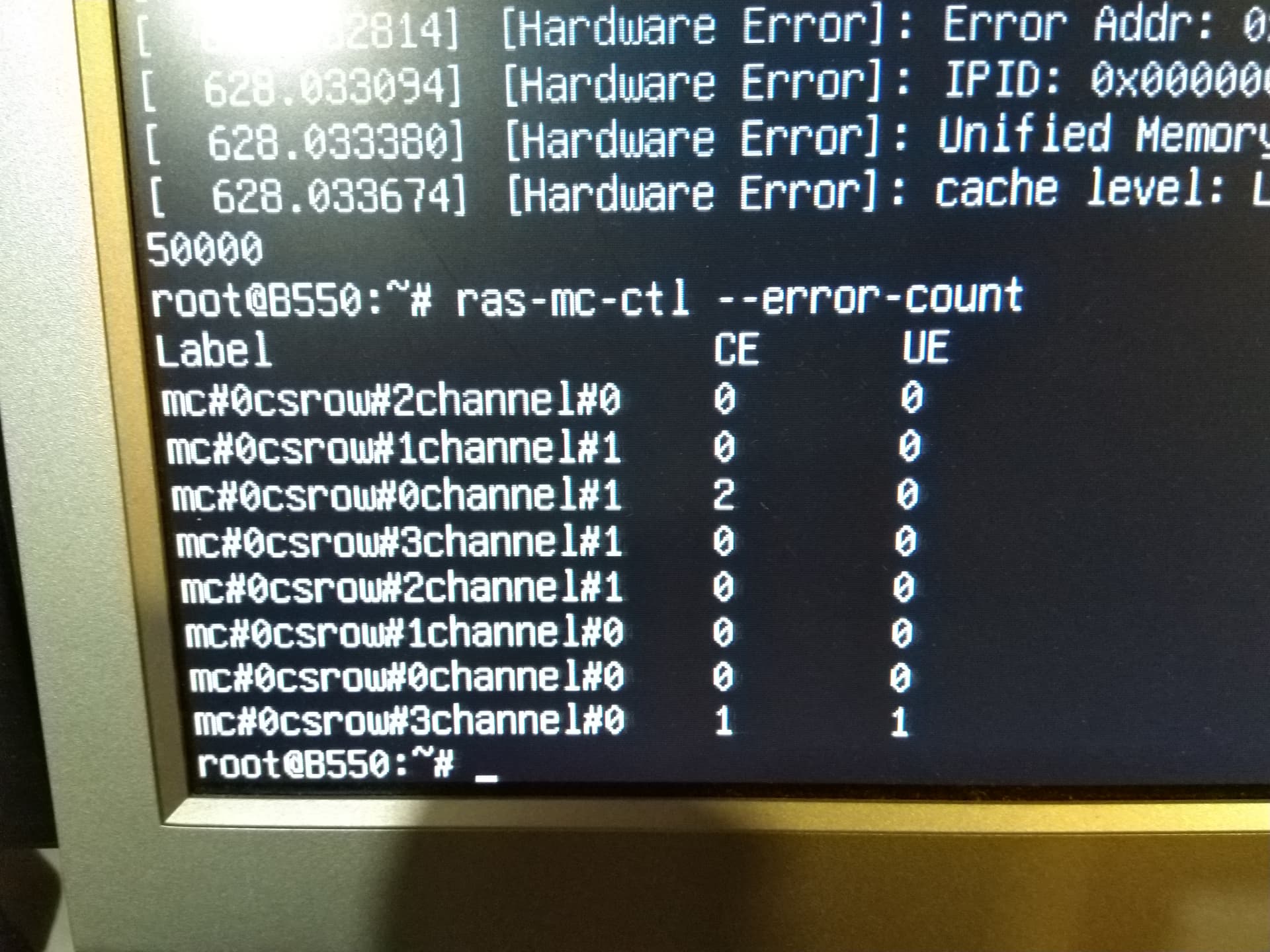
Success! As far as I can tell, this means that ECC works like you’d expect on Debian with the right packages installed. If you disagree, I would love to hear from you!
Postamble
To get notified when an error is observed, you could run a script like this on a schedule:
Script
#!/bin/bash
#hck_ram.sh: Monitors ECC RAM error counters via rasdaemon
#arg 1: email recipient(s), comma separated
#arg 2: filename with ras-mc-ctl output (for debugging only)
if [ "$2" != "" ] ; then
debugmode="TRUE"
printf '%s\n' "debugmode is on"
printf '%s\n' "hck_ram.sh: Health Check Starting"
else
printf '%s\n' "$(date +%F_%H.%M.%S) hck_ram.sh: Health Check Starting"
fi
ras_status="$(ras-mc-ctl --status)"
if [[ "$ras_status" != "ras-mc-ctl: drivers are loaded." ]]; then
printf '%s\n' "ERROR: rasdaemon not ready, or ECC RAM not installed"
exit 1
fi
if [ "$debugmode" == "TRUE" ]; then
ras_error_count="$(cat "$2")"
else
ras_error_count="$(ras-mc-ctl --error-count | sort -u)"
fi
ras_error_count_nonzero="$(printf '%s\n' "$ras_error_count" | grep -v 0$'\t'0$ )"
ras_error_count_nonzero_lines="$(printf '%s\n' "$ras_error_count_nonzero" | wc -l )"
if [[ "$ras_error_count_nonzero_lines" -gt 1 ]]; then
report="hck_ram.sh Report $(date +%F_%H.%M.%S): ECC RAM ERRORS DETECTED"
report="$report"$'\n'$'\n'"$ras_error_count"
msg_body="$report"
printf '%s\n' "Subject: $(hostname): hck_ram: ECC RAM ERRORS DETECTED"$'\n'"$msg_body" | msmtp "$1"
printf '%s\n' "$(date +%F_%H.%M.%S) hck_ram.sh: Sent report"
printf '%s\n' "$report"
else
printf '%s\n' "$(date +%F_%H.%M.%S) hck_ram.sh: Check passed"
fi
printf '%s\n' "$(date +%F_%H.%M.%S) hck_ram.sh: Health Check Done"
The script above requires the msmtp apt package to be installed and configured, and run I it like so: bash -c "/script/hck_ram/hck_ram.sh root,[email protected],[email protected]". This is just an example, and I expect there will also be useful output in dmesg and syslog that you can use instead.