While OpenAI’s ChatGPT generates impressive code, letters and summaries.
The secret is a large language model (LLM) with billions of parameters, the operation requiring hundreds of gigabytes of GPU memory on very expensive hardware.
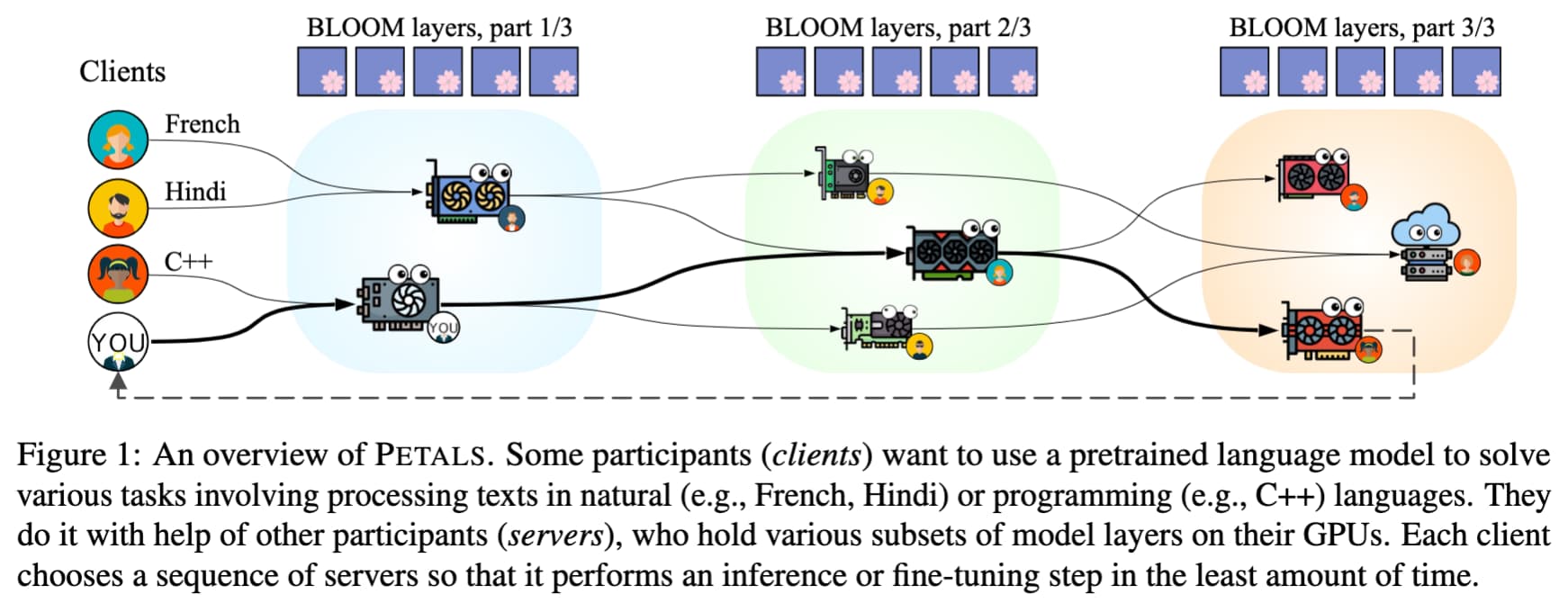
Well rather than the five richest kings, OpenAI and Tech Companies having this ability. We can now address the problem with Petals a solution to share your gaming GPU towards a network, just like a cake you only hold a slice of the model, running vector operations on it.
While the diagram is simple a precision changed LLM was able to fit on 22 gaming graphics cards also higher throughput is available with more cards added.
After using chatGPT the value is clear to setup and run a network for the community as we have a lot of knowledgeable people and may want to up to speed on machine learning via shared projects.
There would also the benefit of using transfer learning, building on the shoulders of this monster 176 billion parameter model save a lot of iteration time.
If we do this right I believe it’s a solid way to maintain access, continue in the spirit of open source and with recent news of OpenAI’s goal of $1 billion in revenue by 2024 its moving towards corporations.
Check out the links and give feedback with a post!
File "/home/any/miniconda3/lib/python3.10/site-packages/petals/server/server.py", line 222, in _choose_num_blocks
assert self.device.type == "cuda", (
AssertionError: GPU is not available. If you want to run a CPU-only server, please specify --num_blocks. CPU-only servers in the public swarm are discouraged since they are much slower