I recently bought all my hardware for my first Rack, which constist of two r630 and a R520 which will run a Proxmox cluster and enable HA. I have an SC846 (X8DTE-F) that runs TrueNAS that I want to use as storage target (yes, not the best hardware for the usecase) for the VM’s the cluster runs.
I have an additional R510 with TrueNAS that will backup all the SC846 data and be used as Proxmox Backup target with an additional offsite Backup server for irreplaceable data only.
The servers are all connected with 10Gbe to each other. The SC846 has 12 x 8TB IronWolf Pros inside for now.
Now I was wondering what the best pool setup for this Kind of storage will be. I am okay with giving up 6 of the 12 drives for VM storage. Should I create a pool with 3 vdevs that consist of 2 mirrored drives?
As I understand that will actually create a stripe of 3 mirrored vdev, meaning I can loose up to 2 disks as long as they are not on the same vdev, right?
Are there any other reccomended setups for VM storage with ZFS? The VM will probably need a good balance between Read and Write performance, in case that information helps.
I will also be using an Optane P4801x as SLOG in order to have Sync on and preventing the total crumble of the spinning rust, as I am planning to use NFS in order to have thin provisioning and delta backups.
As far as I understood, the VM use-case where a lot of small files are written is what Optane was designed for and will shine, however I am not sure if it will be enough to prevent the performance problem with spinning rust, if not I will have to disable sync. Unfortunately SSDs instead of HDDs is not an option for now.
Excited to get your inputs and thoughts on my setup.
If you have to use HDDs, then yes, mirrors is what you want and are the best you can do with the situation. VMs want IOPS and RAIDZ is simply atrocious in that regard.
A setup with 3 vdevs made of mirrored pairs can actually lose 3 disks, as long as it’s the exact correct disks.
In practice, you should treat the array as being able to lose only a single disk before another one gives you pool failure (typically complete destruction).
Also note that ZFS doesn’t stripe across disks like traditional RAID does, which is why you can add new vdevs without fuss. ZFS breaks things into blocks which it can and will place unevenly, though things end up mostly even In practice this only matters for performance if you have a mostly full pool, and then add a new vdev.
For storage pool, your other 6 drives should be a RAIDZ2.
If eventually you are able to put your VMs on SSDs, then taking your reclaimed 6 disks and adding another 6 disk RAIDZ2 vdev to the storage pool.
Fortunately, the ARC can go a long ways toward accelerating reads. You can adjust it smaller or larger as you need.
Also consider adding NVMe as L2ARC. We don’t know how much memory you got, but it certainly isn’t infinite. Any cheap consumer drive will do. You do NOT want random reads and possibly metadata from spinning rust, no matter if you have a RaidZ or 10 mirror vdevs running. I’m running two multiple TiB zVOLs on my machine and I really don’t want to miss my 1TB Mushkin NVMe. After cache warmed up, it just all went smoother.
Even if you use your memory as SLOG (never ever do!), async is still slower than sync. And the data still has to be written to disk at some point . LOG/SLOG is not a real write cache, although often labeled as such. Don’t expect too much out of it. It certainly is no “oh I buy Optane and write at NVMe speed/latency from now on” but I’ve seen good improvements when testing with a LOG vdev, but straight out disabling sync isn’t a problem to my use case, so I don’t need it.
You are right, if you’re really lucky it will actually survive a 3 drive failure. Obviously, in production the drives that will fail are 2 on the same vdev.
That’s what I researched too and why I didn’t even bother with RaidZ, especially with HDDs.
I didn’t know this, do you have any further readings about that in regards to what the benefits and drawbacks are in the way ZFS handles striped in comparsion to traditional Raid?
I have 192GB of RAM installed and was under the impression that it’ll be enough, but I actually already added an NVMe slot to install an SSD to further down the line for L2ARC. Just wanted to see if it is needed once everything is up and running.
I know it won’t be as fast as iSCSI even with a SLOG as long as Sync is enabled, Tom from LawrenceSystems did a great overview and comparsion about that. I also know that SLOG isn’t really a cache in the traditional sense. From what I understand, the data that is written to the SLOG will be written to memory anyway. The SLOG just has the benefit of being able to report that data has been written to the system to the outside party in order to receive the next data faster without having to wait for the system to actually write the data to the disks yet.
This is always reason for discussion on forums and I believe it comes from a misconception of how it actually plays out in a worst case. Correct me if I’m wrong, but from what i researched, having Sync disabled won’t actually be able to get my pool corrupted. With a Slog device installed, It also won’t loose any data (those 5 seconds people always talk about) as it’s stored in the SLOG and will be read and recovered from there upon next boot.
With a SLOG installed and sync diabled the only time you will loose data is, if the machine crashes (PSU failure, etc.) and the SLOG device stops working at the same time. In that case you will loose those 5 seconds of data, right?
You have to keep in mind that if data is in your memory before flushed to disk as a so called transaction group (txg), you obviously lose that data. But ZFS is a copy-on-write filesystem, so there is no danger of partial writes corrupting your data while the rest of the block is lost due to power outage or whatever. You are just left with a 5 second (default setting) old version of that block which pretends that the last 5 seconds never happened.
The LOG is used as a…well…log to recover the delta that occurred in these 5 seconds. That’s the only time the LOG is actually read.
Don’t worry about it then. But keep the option in mind. TrueNAS has some fancy graphs for ZFS stats including many ARC stats. Just check after some time how your hit rates are. ARC is very smart in knowing what’s worthy of precious memory unlike traditional page cache.
But if you are reading like 500GB on a regular basis and want everything cached, keep L2ARC in mind. No fancy hardware required, consumer drive will do. Like SLOG you can plug it in and out as often and whenever you like as both aren’t vdevs.
I’m personally running with 96GB of memory and a TB of L2ARC and I have good experience using an L2 in my use case. HDDs I’m running 6x16TB Toshiba MG08s in 3 mirror vdevs. Like everything with ZFS → “depends on your use case”
Another kind of optimization for reads and writes is the special allocation class vdev or special. They are fast SSD vdevs in an otherwise HDD pool that only store metadata (default) and optionally small files. If you are using VM disk images like .qcow2 or zVOL, the small files option is off the table unless you consider TB big raw disks as small. With 192GB of memory, I doubt you hit the max on ARC metadata percentage either. But again, like L2 or SLOG, dependent on your use case.
vfs.zfs.l2arc.rebuild_enabled set to 1. Saved me so much cache warmup time and write endurance on my disk. Boot time increase is negligible in my experience. I was surprised myself how fast the boot import with the rebuild is. Other than desktop users with boot time fetish,100s of GB of metadata and ARC headers from 4k record/blocksize datasets…no real issue.
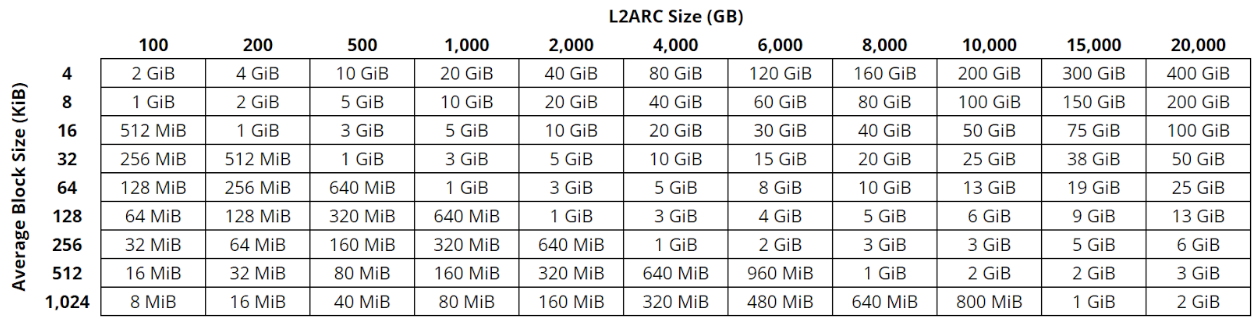
Main issue with L2ARC is that the information if/where data is inside the L2ARC is kept in the ARC and is eating memory just for bookkeeping. This is why 8GB RAM with 1TB of L2ARC is a generally a bad idea. The overhead is per record, not per bit. So smaller recordsize has a disadvantage there. But OP has 192Gig and so that doesn’t apply. I’m using various recordsizes and memory usage for ARC headers on my machine is 1-2% of total ARC size at a 1:10 ratio between ARC and L2.
Neat graph I found somewhere when building my system, shows how much arc bookkeeping you get:
And about these dreaded 5seconds that get mentioned all the time: vfs.zfs.txg.timeout is your tunable for changing that. If you got 16GB or more of SLOG and/or are annoyed by constant write noise, that value certainly is a very convenient one I learned to appreciate.
Ah yes, I actually read that somewhere, but i’ll probably leave it on default until I really get the need to increase that, at which point I will know why I’ll want to so that.
Yeah, I’ll probably be fine for L2ARC on this array and might increase that on the Raid Z2 storage as that will host my Jellyfin library and would probably benefit from a bigger L2ARC.
And if I ever need it for my VM storage too, i got the NVMe slot ready.
Thanks for the additional informations.
Nice, never heard about this option. Does it have any other drawbacks? Boot times aside.
Read that rule of thumb about that sizing the L2ARC too, so for my 196GB of RAM it would be max. 2TB of L2ARC. Thanks for the graph.
I don’t know of any drawbacks on making the L2ARC persistent besides the boot time slow down. I’d be interested to hear if anyone else does because I’m thinking of using it on my next build.
Honestly, based on what I’m seeing in that chart if you are using the default record size of 128KiB (IIRC) then you could easily go higher until it hurts the hit rate of the ARC. But that’s just what my gut says, I don’t have experience to back that up though I’ve heard different ratios mentioned before.
On SLOG, I just wish that ZFS had a proper cache devices. I’ve read that write-back caching has been proposed but hasn’t been added yet. It’s really unfortunate because there isn’t anything to speed up large async writes.
One thing I thought about trying was layering bcache or LVM cache between the disks and ZFS. However, I’m not sure that’s a good solution and definitely not as good as a native one.