I’ll try to record my notes here for future people, as I just purchased a 7900 for gaming and ML experiments.
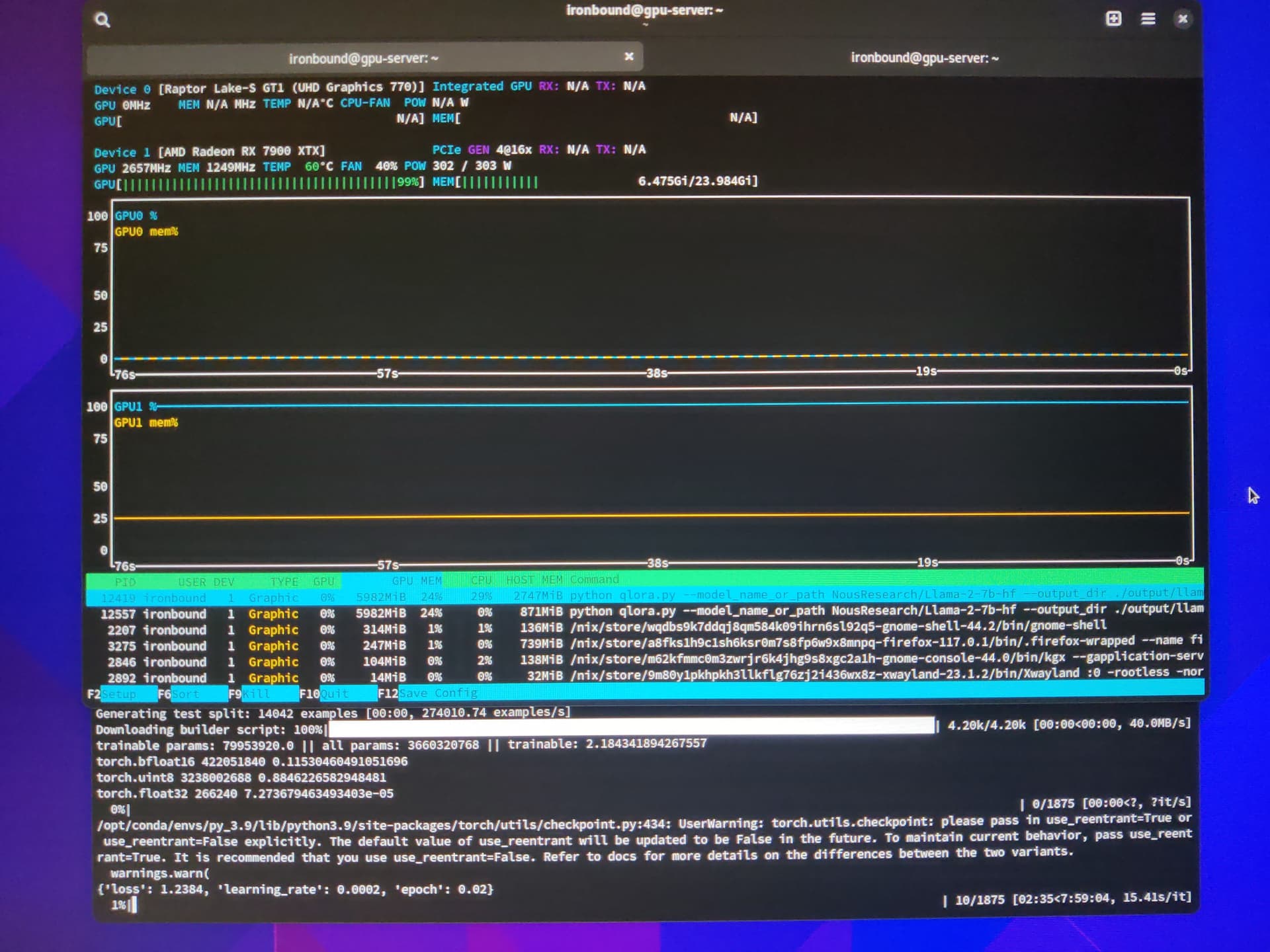
After try the Shakespeare example, I Wanted to train a qLoRA, this is a super efficient 4bit adapter that goes with an existing model.
The process only trains 1/10000 of the model weights so you actually do some training at home… without a computer designed to fight god!
To run the training I had to fix an issue with the bitsandbytes python library, thankfully there was a fork with a solution for Rocm, and with that solved managed to start the train with llama7b, let see how it goes in 8hours!
I am looking at 7900 xt for nearly the same efforts. Would you say the price is worth it. I’m in Canada and it hard to find a 7900 xt for under $1000.
Amd.ca has the 7900 xt for $1172.
Looking at my wandb review and I’ve trained 219 hours now.
Since it’s been hard to find details around 7900 training, I’m sharing the training metric’s below.
I hope its helpful in future!