I am planning on a build around the 3975 threadripper platform.
My use case is an always on VM workstation. The main VM instances are:
a Macos desktop (main desktop),
a docker VM with several containers, mixed use (always on servers),
a linux VM with security assessment tools (including GPU accelerated tasks),
a linux forensics VM (with need for the best IO possible on the RAM/DISK)
a windows 10 vm for desktop document editing / windows desktop software use.
a backup VM with an group of spinning disk attached
a NAS VM
Threadripper 3975, 256gb ram, some GPU (Vega64 currently)
My storage plan is to use:
a single bootable NVME drive for PVE (not sure on formatting options for the disk/volume)
a 4x NVME gen 4 Asus PCI card with 4x Samsung 980 Pro drives (primary VM storage)
an array of various spinning disks for bulk storage and backups (mostly 12tb 7200 sata disks)
The main question I have is what advice exists for the configuration of the disks to get the best use of the storage. My current thoughts are:
boot nvme drive with out of the box configuration using a motherboard m.2 slot, formatted with ext4
NVME card in a bifurcated PCI x16 slot with the four drives configured in some type of high performant ZFS array
The forensic VM will be ingesting large files (2tb raw disk images) and parsing them which is extremely IO, RAM and CPU intensive. The reason I need to get good performance from the NVME drives. Maybe I should consider passing through raw disks to this VM?
Spinning disks in some type of high-availability configuration (RAIDZ-2?)
Other questions include:
do I need to change the block sizes of the storage devices to optimize their use?
should I configure a SLOG or ZIL device for the NVME array?
what type of caching should I configure for the NAS storage array of spinning disks?
Depends entirely on your workload, as a SLOG is only beneficial when doing lots of sync writes. Asyncronous writes don’t use the SLOG/ZIL at all. Those Samsung 980 Pro aren’t really made for the SLOG-job, too much wear and no power-loss protection. You only need like 16GB of SLOG for default configurations, so people tend to overprovision their SLOG to the max or use special drives.
Storage nowadays has trouble keeping up with NVMe speeds and ZFS isn’t that different. You may be disappointed when comparing manufacturer numbers with your own numbers. But the raid0 or raid 10 in zfs-equivalents are the two fastest options. Or use md raid 0 for two SSDs, losing all ZFS features for performance and do regular backups to your ZFS pool. I suggest to test run both configurations and decide afterwards.
For HDDs…whatever floats your boat. People like RaidZ because you end up with more usable storage. But if you want to copy/backup those 2TB images to your platters…striped mirror aka Raid10 might save you lots of time at the cost of capacity. Parity raid configurations aren’t known for their write speeds, quite the contrary.
I’m testing consumer NVMes in a special vdev configuration on top of my HDD zpool right now, but you can check on Wendells tuning tips here: ZFS Metadata Special Device: Z
Oh and don’t put non-redundant drives into the same pool as drives with redundancy (RaidZ,1,10). One vDev dead = Pool dead = Game over, man.
Thanks for the info. I’m guessing that I can just leave the SLOG/ZIL out from the ZFS configuration.
I’ll look into the ZFS raid configurations and do some testing when I have the system up. I’m going to try to find a good benchmark to use with Proxmox to get a good indication of performance and probably play around with a few of the configurations to find the best one.
You can always add these later if you need to, as they only really affect in-flight data.
What you cannot (easily) add later is a special metadata drive. I mean you can, but you’ll have to move your data off and back on again. Either way, if you can add a mirrored special vdev to that HDD pool I think you’ll see a big improvement.
As for VMs on ZFS (or any COW filesystem like BTRFS), if you use QCOW2 images, you will have write-amplification (bad). Your options are to A) use RAW vm img formats, which can be a pain, depending on your hypervisor, or B) mitigate the effect of the write amplification by matching the recordsize on your VM dataset to the default recordsize of QCOW2 images. I’m not 100% what that value is at the moment but some quick googling should give you an answer.
Running VMs on ZFS is doable, but if you aren’t careful you can shoot yourself in the foot pretty majorly
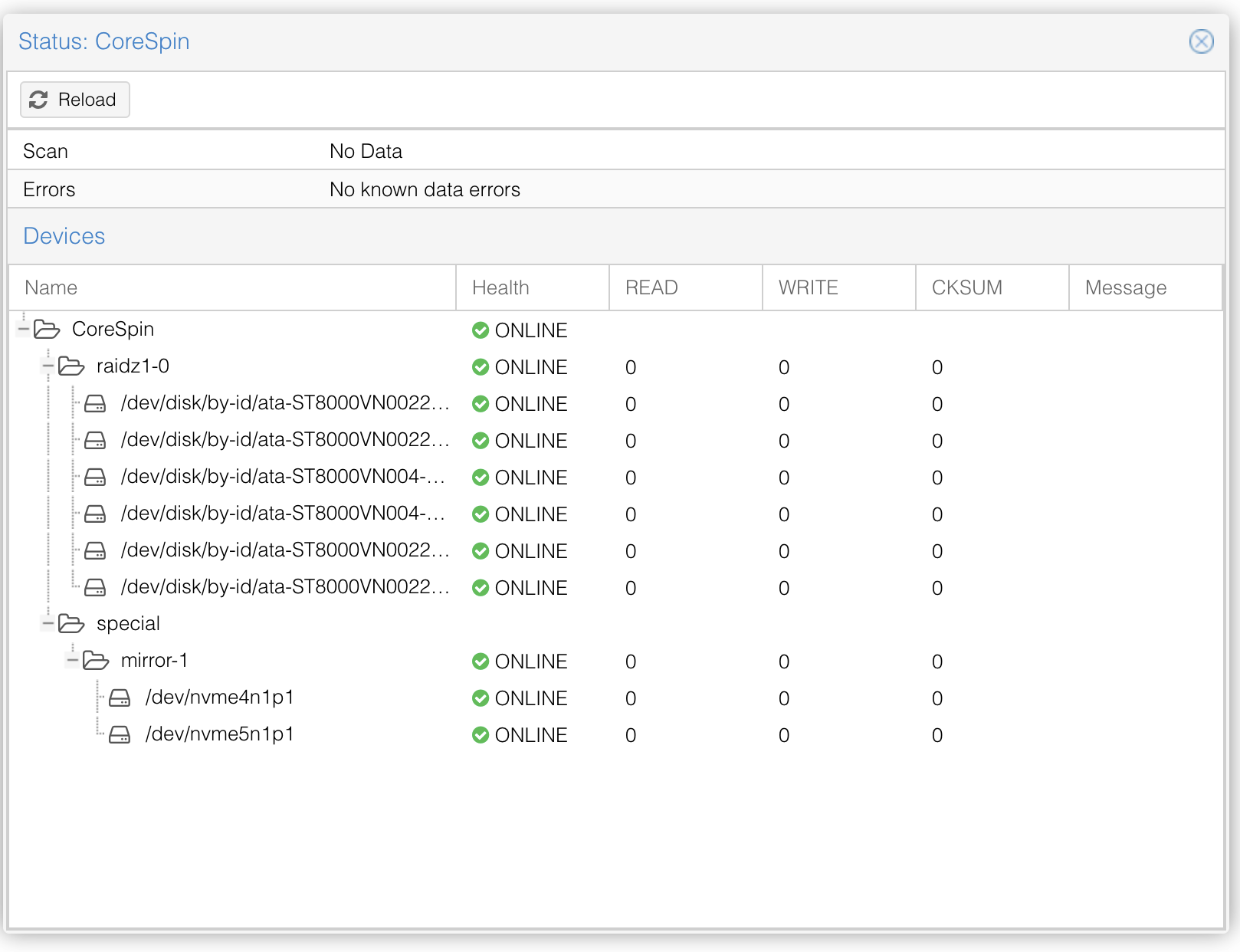
Just to clarify (and modify my design somewhat) there are three different storage buckets with my best guess at their configuration (please suggest changes):
most files on this drive will either be vm drives for virtual machines or fast storage space for working files
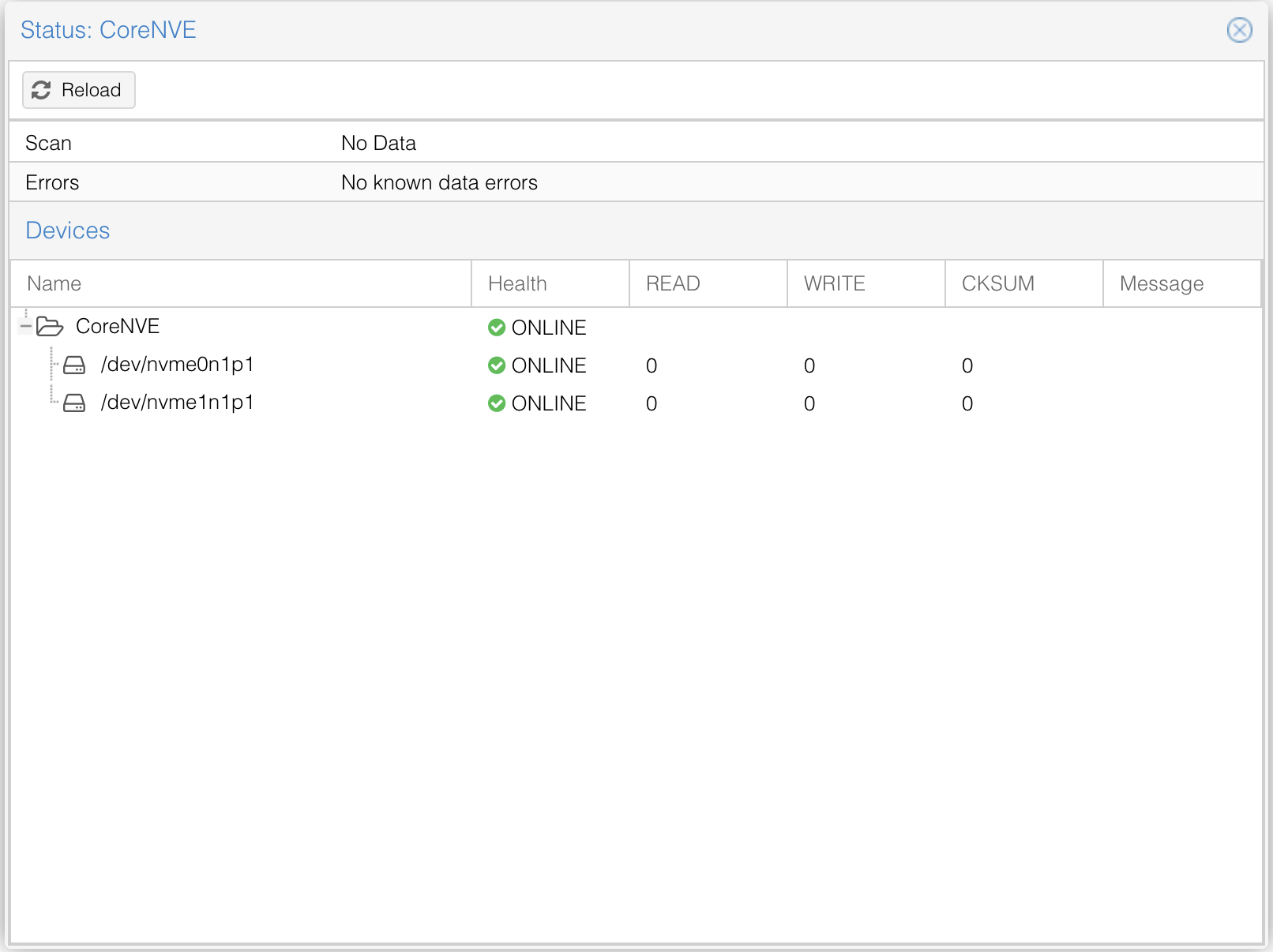
metadata vdev (2x smaller really fast NVMEs? 280gb 3d Xpoint? / 900p)
c) bulk storage (6 x 12tb spinners) this includes lots of different file sizes and types including backups of the faster Pools, and other bulk storage (NAS)
RAIDZ1
should I be using a special metadata vdev on this?
I don’t see the point of metadata vdev on the nvme pool. If you’re getting for Samsung 980 Pros, in a striped mirror config, you should be looking at 14 GB/s write and 28 GB/s read. That’s pretty fast. And conceptually, you would be taking the metadata off of on nvme pool, and on to another one? I think you would be better served adding the metadata vdev to the HDD pool.
Also, You’re probably going to want to mirror the metadata vdevs. Lose that vdev and you lose the whole pool, even if the HDDs are in RAIDZ3 or whatever
Ok, that makes sense for the HDD backed pool, the reason I was thinking that the metadata drive would be useful on the nvme backed pool, is the split of IOPs between data reads/writes and the metadata reads/writes.
RaidZ1 is a good choice, lots of storage. But keep in mind that during resilver (heavy load for all drives, heavy stress so to say) you can’t lose another drive. 3x striped mirror vdevs will boost performance quite a bit, although usable storage goes down to 36TB from 60TB which is like 500$ worth of drives. We all make those tough choices
The point of SLOG/L2ARC and/or special metadata drive is to bypass the low performance on HDDs and dedicate ressources to capitalize on SSD/NVMe performance for these cases to improve overall performance. There is no need for any of them in a pure NVMe pool and I doubt that Optane or other special write-optimized low latency drives will get you noticeable net gains.
If you see a lot of sync writes on you HDD pool = consider SLOG
If you access more data frequently than your memory/ARC can handle = consider L2ARC
If you want all the “tiny bits” of your filesystems IO (where HDDs struggle a lot. move 100k small files from HDD to HDD to witness the abyss itself) to just be handled by an NVMe vdev with insane IOPS/Latency, consider using special vdevs.
That linked blog is really well done (some arguments are dated. e.g. L2ARC is persistent now). ZFS just isn’t plug&play like NTFS on windows, but once you figure out what those like 100 different cogs do, you get a nice and fast storage, specifically tailored to fit your needs.
And if you’re ok on the raw RaidZ1 performance for (incremental) backups, snapshots, and general storage, I wouldn’t bother boosting it with additional NVMe. Never change a running system.
There seems to be an upcoming feature for ZFS to enable full Direct_IO, bypassing the ARC all together for fast NVMe drives to reduce the overall overhead and improve performance for pure NVMe pools. No ETA yet, but at least something on the horizon.
I mean possibly, I guess it’d be another level of striping, but that would only be useful if your nvme data drives were literally 100% maxed out where as putting it on the HDDs would see a performance uplift all the time.
The 4 drive NVME pool is going to be used for high-speed VM disk allocation where performance is the #1 priority. I’m planning on doing very regular backups of this pool to the spinning disk, and do not plan on having any critical data that can’t be lost on that drive.
Everything I’ve read suggests that RAIDZ2 is the way to go with that, but maybe I should just stripe it for performance and forget about the mirror - which would let me regain the original space on the drive too?
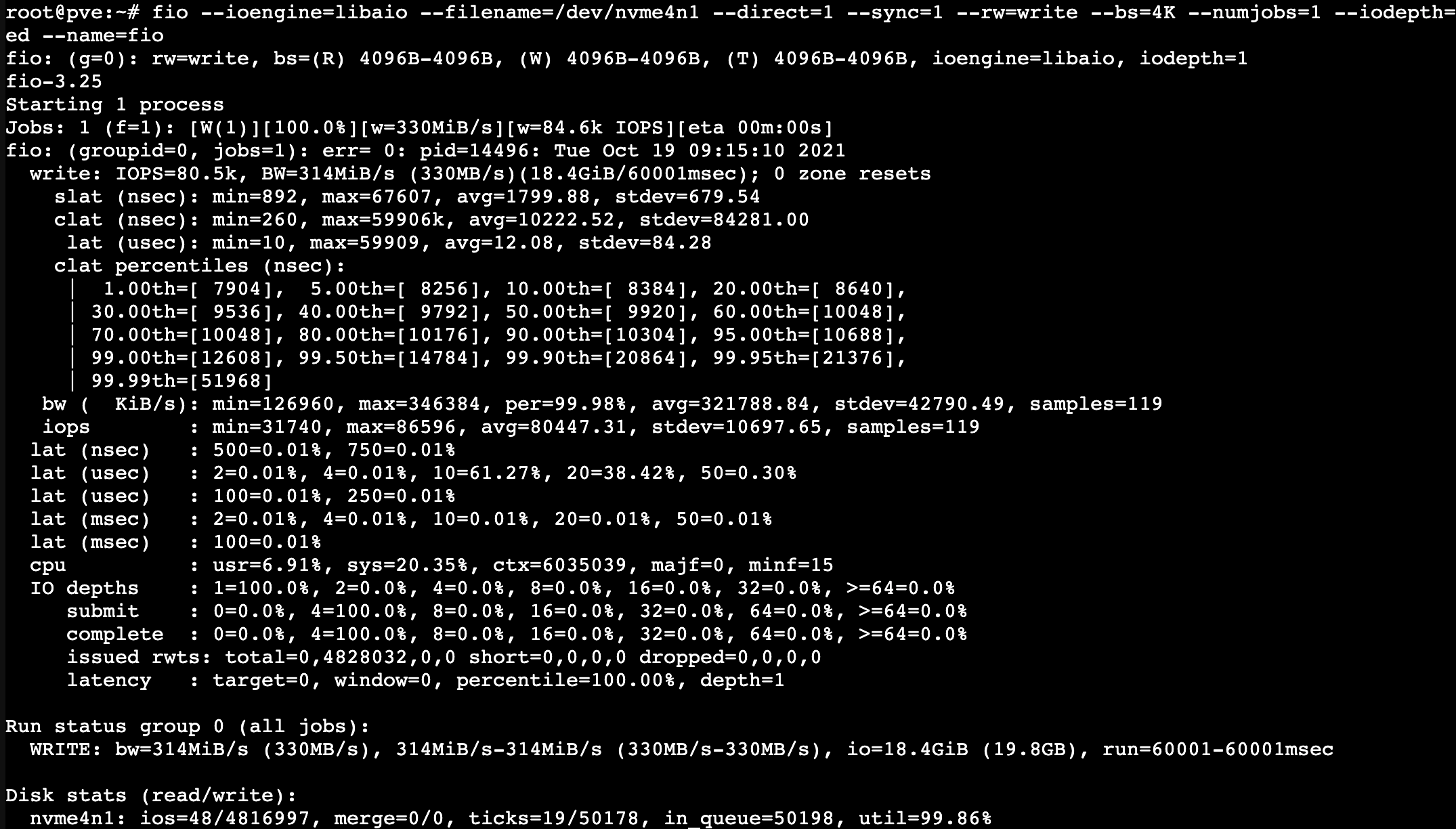
It looks like the Samsung 980pros are all giving me really bad performance. While the ADATA SX8200s are fast as expected. The 980 pros are installed in an ASUS gen4 NVME card the same as the ADATAs. Any ideas?